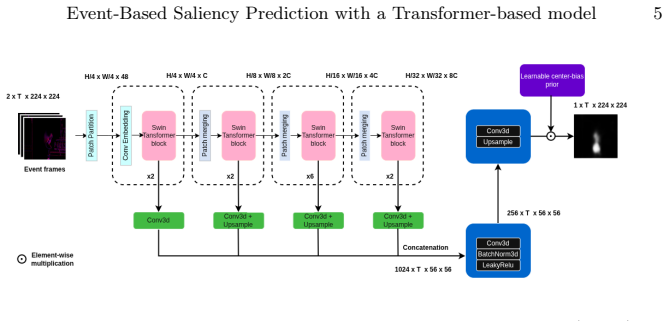
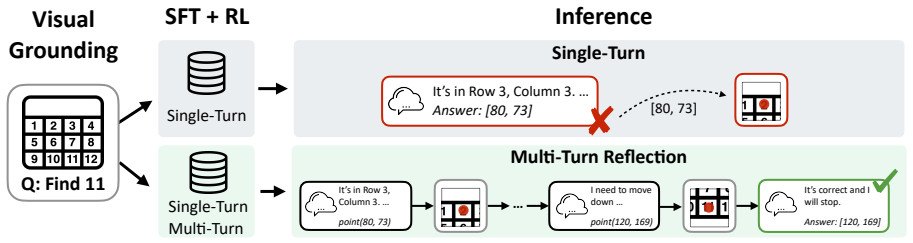
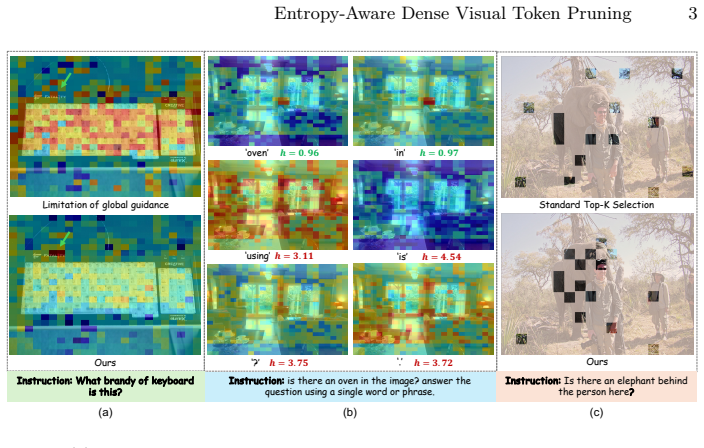
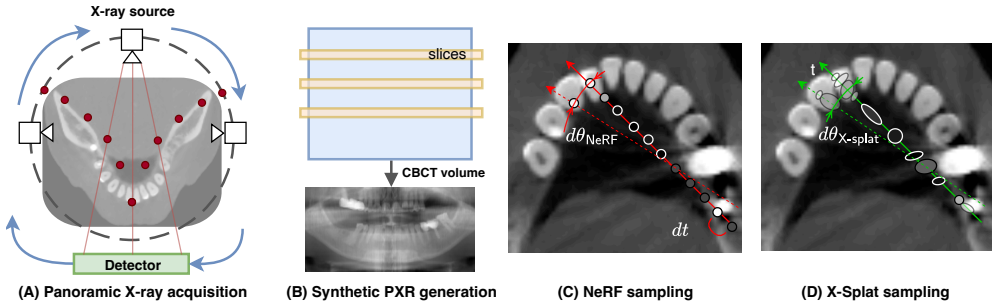
1
3D scene graph plans portraits before shutter click
Before the Shutter: Aesthetic and Actionable Portrait Photography Planning in 3D Scenes
Generates human pose, camera, and lighting setups that raters prefer over post-capture baselines while staying physically valid.
 full image
full image
abstract click to expand
Portrait photography is largely decided before the shutter opens: the subject's pose, the camera configuration, and the lighting devices must be coordinated within the surrounding 3D scene. In contrast, most existing computational methods focus on post-production in 2D image space, such as retouching, relighting, or editing images that already exist; pre-capture photographic planning remains largely unexplored. We introduce 3D aesthetic portrait planning, the task of generating human pose, camera, lighting, and exposure plans that produce visually compelling portraits while satisfying geometric and photometric feasibility in a 3D scene. Our approach builds a Photographic Scene Graph that represents scene affordances, subject-scene relations, and portrait-relevant lighting structure. Built on this representation, we perform aesthetic-guided comparative planning over previous attempts and current viewfinder observations. Experiments across diverse indoor and outdoor scenes show that our method produces portraits preferred by human raters and MLLM evaluators over competitive baselines, while maintaining high physical plausibility. Together, our results suggest a path from post-capture correction toward pre-capture computational portrait planning. Project repository: https://github.com/songrise/Before-the-Shutter