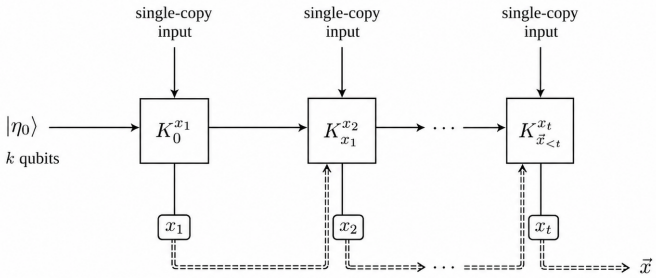
1
Multi-distribution functionals reduce to integrals of coincidence divergences
Monotonicity under data processing and additivity on independent products force every such functional to an integral over four strata
 full image
full image
abstract click to expand
Comparing two probability distributions is a basic building block of statistics and machine learning, and the right family is well understood: the R\'enyi divergences of order $\alpha\in[0,\infty]$ are the unique family monotone under data processing and additive on independent products. Many problems instead compare more than two distributions at once -- multi-population fairness, multi-prior PAC-Bayes bounds, multi-hypothesis testing -- and the right multi-distribution generalization of the R\'enyi family has been an open question.
We characterize it. Every functional of $W$-tuples of distributions that is monotone under data processing and additive on independent products is a positive integral of multi-way coincidence divergences $C_{\alpha}(\pi_1,\dots,\pi_W) := -\log\int \pi_1^{\alpha_1}\cdots\pi_W^{\alpha_W}$ (with $\sum_k \alpha_k = 1$) over a parameter space with four strata: the simplex interior; mixed-sign exponent cones (the analogue of R\'enyi orders $>1$); a tropical boundary at infinity carrying max-divergences; and pairwise Kullback-Leibler edges at the simplex vertices. Each stratum is necessary -- the destination of an explicit data-processing-monotone, product-additive divergence the others cannot reproduce -- and each is a clean limit of simplex-interior atoms.
The same family arises from several independent routes -- the structural axioms, Kolmogorov-Nagumo means with R\'enyi's entropy axiomatics, classical entropy characterizations, multi-hypothesis testing error exponents, and a multi-lottery betting interpretation -- structural evidence that this is the canonical multi-distribution R\'enyi calculus rather than an artefact of any one axiomatic input. The two-prior case recovers the standard R\'enyi result; a worked $W=3$ instance, numerical verification, and a conditional extension round out the treatment.