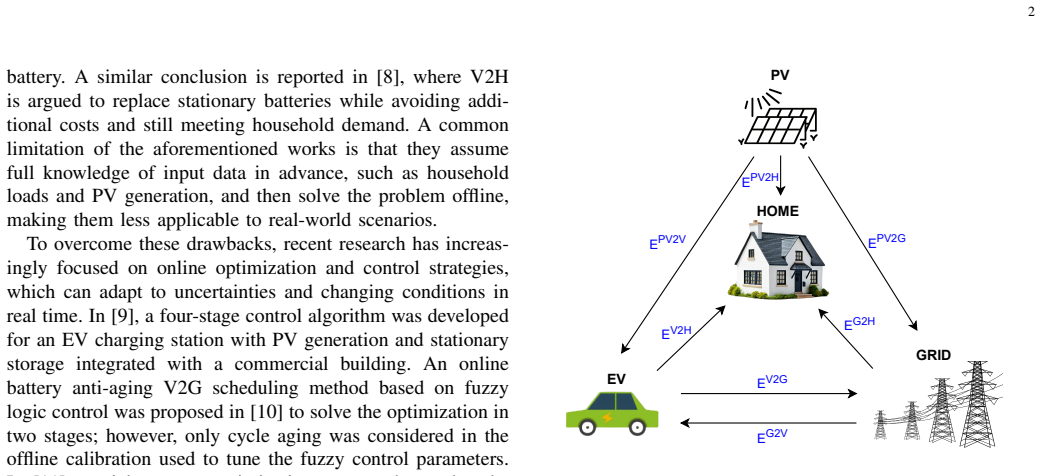
5
AI models lag behind text-only on 3D brain MRI benchmark
NeuroQA: A Large-Scale Image-Grounded Benchmark for 3D Brain MRI Understanding
Top vision-language models reach only 47.5 percent on verified questions while text statistics yield 49.4 percent.
 full image
full image
abstract click to expand
We present NeuroQA, a large-scale benchmark for visual question answering in 3D brain magnetic resonance imaging (MRI), with 56,953 QA pairs from 12,977 subjects across 12 datasets. It spans ages 5-104 and five clinical domains: Alzheimer's, Parkinson's, tumors, white matter disease, and neurodevelopment. Unlike prior medical Visual Question Answering (VQA) efforts that operate on 2D slices or rely on narrow diagnostic labels, NeuroQA pairs every item with a full 3D volume. It evaluates 11 clinically grounded reasoning skills across Yes/No, multiple-choice, and open-ended formats. Of the 203 templates, 131 are image-grounded (answerable from a 3-plane viewer) and 72 are image-informed (ground truth from quantitative volumetry or clinical instruments). To remove text-only shortcuts, we apply answer-distribution refinement, reducing closed-format text-only accuracy from $>$80% to 44.6%; image necessity is assessed separately through an image-grounding protocol released with the benchmark. A 38-rule deterministic pipeline and two rounds of expert review verify every QA pair against FreeSurfer measurements, metadata, or radiology report fields, with zero same-subject contradictions across templates. We conduct a clinician evaluation in which two clinicians independently assess 100 frozen test items on a three-plane viewer. On closed-format (Yes/No + multiple-choice) test-public items, the best zero-shot vision-language model and a supervised 3D CNN baseline reach 47.5% and 43.7% accuracy respectively, both below the 49.4% text-only majority-template floor. NeuroQA adopts a two-tier release with public QA pairs for open-access datasets and reproducible generation scripts for datasets restricted by data use agreements (DUAs), plus subject-level splits, a held-out private test set, and an online leaderboard.