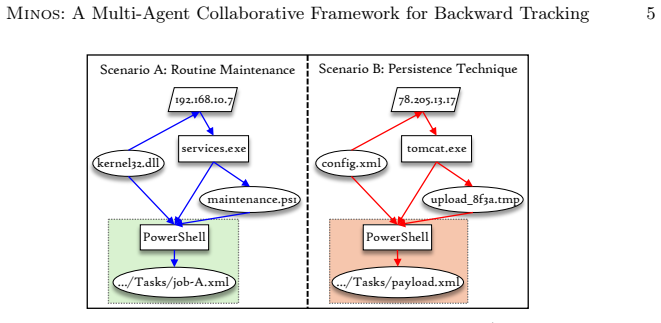
5
Reverse engineering finds six flaws in AirDrop and Quick Share
Protocols on over five billion devices accept complex untrusted data without pairing, exposing reachable denial-of-service and bypass paths.
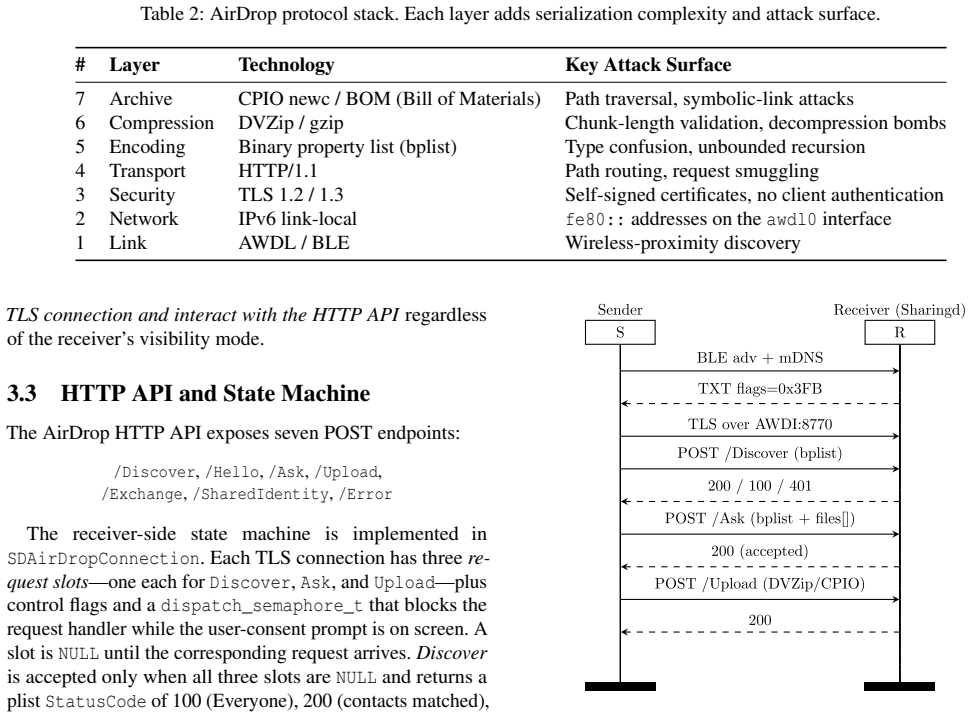 full image
full image
abstract click to expand
Apple AirDrop and Google/Samsung Quick Share are proximity file-transfer protocols used by over five billion devices, yet their application-layer security properties remain largely unstudied because both stacks are proprietary and undocumented. Both protocols are reachable from wireless proximity without any prior pairing and process complex serialized content (binary plists, CPIO archives, Protocol Buffers, UKEY2 handshakes) inside privileged daemons, making them attractive zero-click targets across multiple operating systems. We perform the first cross-platform reverse engineering and protocol-aware fuzzing study of both stacks. We reconstruct AirDrop's seven-layer state machine and DVZip adaptive compression from binary analysis, build AIRFUZZ, a protocol-aware fuzzer that mutates pre-compression representations, and complement it with targeted hand-written analyses of Samsung's Quick Share service and Google's Quick Share for Windows. We discover six vulnerabilities (V1-V6): three pre-authentication issues in macOS/iOS AirDrop (V1: Swift fatalError DoS in the HTTP path router; V2: unbounded XML plist recursion in Foundation; V3: NULL dereference in Network.framework's HTTP/1.1 parser), two protocol-layer flaws in Samsung Quick Share (V4: pre-authentication OfflineFrame dispatch; V5: D2D encryption bypass for three frame types), and a heap use-after-free in Google Quick Share for Windows (V6) for which Google awarded a bounty. We responsibly disclosed all findings, and Apple, Samsung, and Google have acknowledged the reports.