1
Physics models cut table tennis ball prediction error by 59%
Physics Models for Sim-to-Real Transfer in Professional-Level Robot Table Tennis
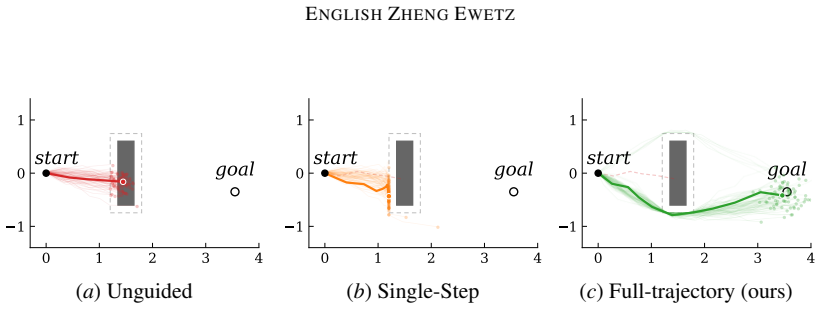
Aerodynamic, buckling, and residual-contact models enable RL policies that compete against professional players after sim-to-real transfer.
 full image
full image
abstract click to expand
At competitive speeds and spins, a table tennis ball follows complex, counterintuitive trajectories that a robot must track and precisely counter within fractions of a second. Training a reinforcement learning policy capable of these skills is prohibitively expensive and dangerous in the real world, making high-fidelity simulation essential. Transferability of such policies, however, critically depends on how faithfully the simulation captures real-world dynamics - a requirement made even more stringent by the adversarial nature of the game, where any modeling inaccuracy becomes an exploitable weakness for the opponent. Prior state-of-the-art in robot table tennis generally focuses on a limited range of velocities and spins and fails to capture the richness of ball behaviors encountered in professional-level play. In this work, we present physics models for aerodynamic ball flight, ball-table contact, and ball-racket contact. that accurately capture the ball behavior over a vast range of speeds and spins relevant to the game. Specifically, we model drag and Magnus force coefficients as functions of Reynolds number and spin ratio in the aerodynamics equations. For the table contact model we model effects of ball buckling on the coefficient of restitution and incorporate residuals into the instantaneous point-contact models. For the racket contact model, we introduce a residual neural network component to complement coefficients related to normal and tangential coefficients of restitution as well as torsional spin damping. Evaluated on an unprecedentedly large dataset of competitive matches (277 games), the proposed models significantly reduces prediction errors (e.g., 59% median landing-position error reduction). The resulting models were used to train the RL policies for the first real-world robot table tennis AI agent capable of competing against professional players.