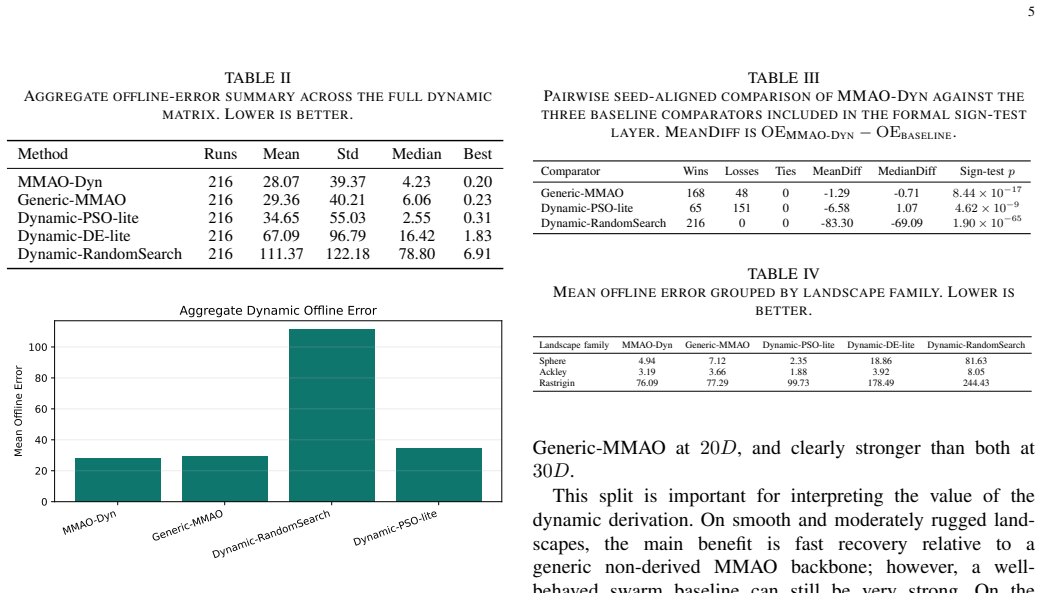
0
Bounded gate stabilizes quantum fast-weight programmers
Stable Self-Modulating Quantum Fast-Weight Programmers with Bounded Memory Gates
Tanh on old-state memory removes divergence in long sequences and improves robustness on forecasting tasks.
 full image
full image
abstract click to expand
Quantum Fast-Weight Programmers (QFWPs) store temporal information in dynamically programmed variational-circuit parameters rather than in nonlinear recurrent hidden states, offering a practical route to quantum sequence modeling. Self-Modulating QFWP improves this framework by using input-dependent gates for both new fast-weight updates and the accumulated fast-weight state, but its unbounded old-state multiplier can diverge in long-sequence regimes. We propose a bounded old-state modulation rule that applies a sign-preserving tanh gate only to the recurrent memory branch while leaving the additive update and new-update modulation unchanged. We evaluate standard QFWP, full Self-Modulating QFWP, Only-New, and Only-Old variants on two CUDA-Q quantum-dynamics forecasting tasks and on Milan SMS telecommunication activity prediction. The quantum-dynamics results show that old-state modulation is the most consistent source of improvement over Standard QFWP, and that bounding the old-state gate removes long-sequence divergence while improving aggregate robustness. On Milan SMS forecasting, the original unbounded Self-Modulating QFWP converges across the tested grid and shows its clearest gains at longer input windows, with behavior close to the Only-Old ablation. These findings identify accumulated-memory modulation as the key mechanism of Self-Modulating QFWP and bounded old-state gating as a targeted stabilization strategy.