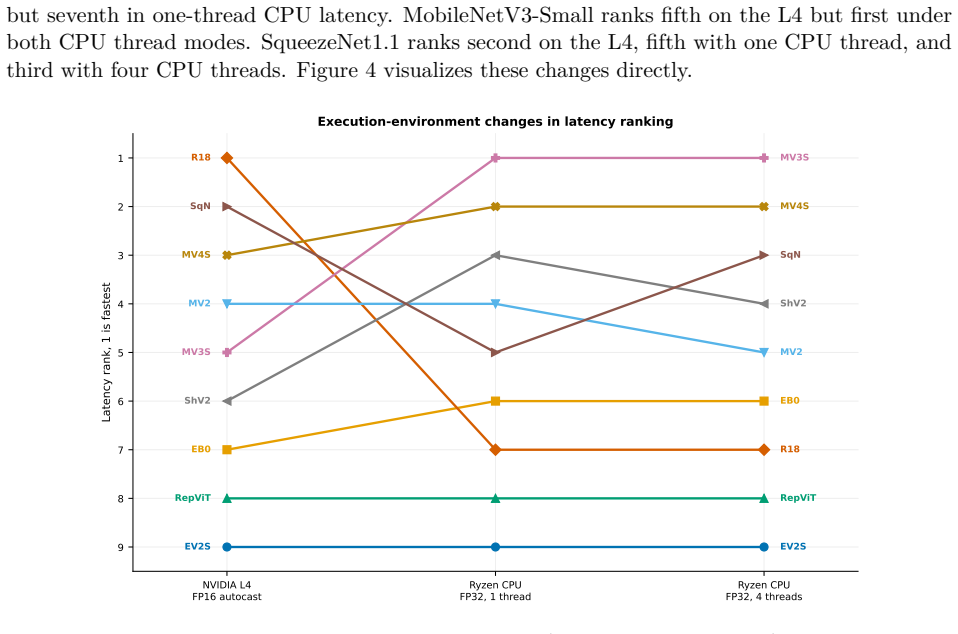
Do Newer Lightweight CNNs Perform Better Under Resource Constraints? A Controlled Multigenerational Study of Architecture, Initialization, Training Budget, and Efficiency
Pith reviewed 2026-07-03 17:18 UTC · model grok-4.3
The pith
Controlled tests find newer lightweight CNNs deliver selective rather than universal gains in accuracy and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a shared downstream training protocol, newer lightweight CNN designs provide selective rather than universal gains. EfficientNetV2-S reaches the highest top-1 accuracy on CIFAR-10 and CIFAR-100, yet EfficientNet-B0 remains within 0.22 to 1.79 points of the best result while using roughly 79 percent fewer parameters and 86 percent fewer GMACs and appearing on every accuracy-resource Pareto frontier. MobileNetV3-Small records higher accuracy and lower measured latency than MobileNetV4-Conv-Small on all three datasets, and latency orderings shift between GPU and CPU hardware. Scratch training leaves EfficientNet-B0 well below its pretrained performance even after extended epochs.
What carries the argument
The shared downstream training protocol and evaluation setup that holds initialization, data augmentation, optimizer, and epoch budget fixed across nine model packages.
If this is right
- EfficientNet-B0 remains competitive across datasets while using substantially fewer parameters and GMACs than later designs.
- MobileNetV3-Small achieves lower GMAC count, faster CPU inference, and higher accuracy than MobileNetV4-Conv-Small under identical conditions.
- Latency rankings differ sharply between NVIDIA L4 GPU and AMD Ryzen CPU, showing GMACs alone do not predict measured inference performance.
- SqueezeNet1.1 records the fewest parameters and lowest peak CUDA memory but substantially weaker accuracy.
- EfficientNet-B0 stays 3 to 17 points below its pretrained accuracy after 100 epochs of scratch training.
Where Pith is reading between the lines
- Model selection for edge devices benefits from empirical Pareto analysis rather than assuming later releases dominate.
- The interaction between architecture and fixed training budget can favor certain earlier designs over their successors.
- Hardware-specific latency measurements are required because operation counts do not reliably rank real inference speed.
- Revisiting well-tuned older models may yield better efficiency trade-offs than adopting the newest variants without controlled re-evaluation.
Load-bearing premise
The shared downstream training protocol and evaluation setup fairly represents typical real-world use cases without systematic biases from initialization or optimization details that favor one generation of models.
What would settle it
Re-training the same nine models with each architecture's originally published training recipe and hyperparameters reverses the observed accuracy ordering between MobileNetV3-Small and MobileNetV4-Conv-Small on CIFAR-10.
Figures







read the original abstract
Newer lightweight convolutional neural networks are often presented as improving predictive performance and deployment efficiency, but such claims require controlled evaluation. This study compares nine lightweight CNN model packages across CIFAR-10, CIFAR-100, and Tiny ImageNet under a shared downstream protocol. We report top-1 accuracy, macro F1, top-5 accuracy, parameter count, FP32 storage, GMACs, batch-size-1 latency on an NVIDIA L4 and AMD Ryzen 5 5500U CPU, peak PyTorch CUDA allocated tensor memory, and point estimate Pareto frontiers. EfficientNetV2-S achieves the highest observed top-1 accuracy on CIFAR-10 and CIFAR-100 at 97.57% and 86.98%, while RepViT-M1.0 leads Tiny ImageNet at 79.87%. EfficientNet-B0 remains within 0.22, 0.85, and 1.79 percentage points of the best result on the three datasets while using approximately 79% fewer parameters and 86% fewer GMACs than EfficientNetV2-S. It also appears on every evaluated accuracy and resource Pareto frontier, making it the most consistently competitive intermediate-budget option. MobileNetV3-Small has the lowest GMAC count, is the fastest model under both CPU thread settings, and records higher observed accuracy than MobileNetV4-Conv-S on all three datasets. Under random initialization, it leads MobileNetV4-Conv-S by 2.55, 1.76, and 0.99 points, with paired test-set intervals excluding zero for the fixed trained models. EfficientNet-B0 remains 3.29, 10.10, and 17.54 points below its pretrained counterpart after 100 epochs of scratch training, despite requiring about five times the recorded training time. SqueezeNet1.1 has the fewest parameters and lowest peak CUDA allocation, but substantially weaker accuracy. Latency rankings differ sharply between the L4 and CPU environments, showing that GMACs alone do not predict measured inference performance. Overall, newer designs provide selective rather than universal gains
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper performs a controlled empirical comparison of nine lightweight CNN packages (EfficientNet-B0/V2-S, MobileNetV3-Small/V4-Conv-S, RepViT-M1.0, SqueezeNet1.1 and others) on CIFAR-10, CIFAR-100 and Tiny ImageNet. Using a single shared downstream training protocol (100 epochs, fixed initialization/augmentation/optimizer), it reports top-1 accuracy, macro F1, top-5 accuracy, parameter count, GMACs, GPU/CPU latency, peak CUDA memory and accuracy-resource Pareto frontiers. Main claims are that EfficientNetV2-S leads CIFAR accuracy, EfficientNet-B0 remains competitive with far lower resources and appears on all frontiers, MobileNetV3-Small outperforms MobileNetV4-Conv-S under the protocol (including under random init), and newer designs yield only selective rather than universal gains.
Significance. If the shared protocol is architecture-neutral, the work supplies concrete, multi-metric evidence that newer lightweight CNNs do not deliver uniform improvements under fixed resource budgets, underscoring the value of older baselines like EfficientNet-B0 and the poor correlation between GMACs and measured latency. The explicit Pareto analysis and cross-environment latency comparison are useful for practitioners choosing models under deployment constraints.
major comments (2)
- [Methods (training protocol)] Methods (training protocol description): The central claim that 'newer designs provide selective rather than universal gains' rests on the assumption that the fixed 100-epoch shared recipe is fair across generations. Newer models (EfficientNetV2-S, MobileNetV4) were originally published with progressive learning, distinct RandAugment policies and optimizer schedules; no ablation or per-model hyperparameter search is reported to isolate architecture from protocol mismatch. This directly affects interpretation of the MobileNetV3-Small vs MobileNetV4-Conv-S gap and the EfficientNet-B0 competitiveness result.
- [Results (accuracy and Pareto sections)] Results (accuracy tables and Pareto frontiers): Only point estimates are shown for most comparisons; while paired intervals are mentioned for the MobileNetV3/V4 case, no multiple random seeds, statistical tests, or variance estimates are provided for the 0.22–1.79 pp gaps cited for EfficientNet-B0 or the RepViT Tiny-ImageNet lead. This weakens the load-bearing claim that EfficientNet-B0 'remains within X points of the best result' and appears on every frontier.
minor comments (2)
- [Abstract and Results] Abstract and results: The phrase 'point estimate Pareto frontiers' is used without clarifying whether the frontiers are constructed from single runs or whether uncertainty bands are considered.
- [Methods] The manuscript should explicitly state the exact data-augmentation pipeline, learning-rate schedule, and optimizer hyperparameters used in the shared protocol so readers can assess compatibility with each model's original recipe.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below, focusing on the controlled nature of the study.
read point-by-point responses
-
Referee: Methods (training protocol description): The central claim that 'newer designs provide selective rather than universal gains' rests on the assumption that the fixed 100-epoch shared recipe is fair across generations. Newer models (EfficientNetV2-S, MobileNetV4) were originally published with progressive learning, distinct RandAugment policies and optimizer schedules; no ablation or per-model hyperparameter search is reported to isolate architecture from protocol mismatch. This directly affects interpretation of the MobileNetV3-Small vs MobileNetV4-Conv-S gap and the EfficientNet-B0 competitiveness result.
Authors: The manuscript's contribution is a controlled comparison under one shared downstream protocol (explicitly described in Methods and the abstract) to isolate architecture effects rather than to optimize each model individually. This fixed-recipe design is the basis for the 'selective rather than universal gains' claim. We will add an explicit statement in the Methods and Discussion sections clarifying that no per-model hyperparameter search or protocol adaptation was performed, so results reflect performance under the common recipe and not necessarily the best attainable accuracy for each architecture. revision: partial
-
Referee: Results (accuracy tables and Pareto frontiers): Only point estimates are shown for most comparisons; while paired intervals are mentioned for the MobileNetV3/V4 case, no multiple random seeds, statistical tests, or variance estimates are provided for the 0.22–1.79 pp gaps cited for EfficientNet-B0 or the RepViT Tiny-ImageNet lead. This weakens the load-bearing claim that EfficientNet-B0 'remains within X points of the best result' and appears on every frontier.
Authors: Paired test-set intervals were computed and reported for the MobileNetV3/V4 comparison. For the remaining gaps we report single-run point estimates, which is standard in many architecture benchmark papers. We acknowledge that multi-seed variance would strengthen the claims. We will add a limitations paragraph noting the single-seed point estimates for most metrics and the consequent reliance on observed differences rather than statistical tests. revision: partial
Circularity Check
Purely empirical comparison; no derivations or self-referential predictions
full rationale
The manuscript performs a controlled multigenerational empirical study of nine lightweight CNN packages on CIFAR-10/100 and Tiny ImageNet. It reports measured top-1 accuracy, F1, latency, GMACs, memory, and Pareto frontiers under one fixed downstream protocol. No equations, fitted parameters, uniqueness theorems, or ansatzes appear; the headline claim of selective rather than universal gains is a direct summary of the tabulated experimental outcomes. No load-bearing step reduces to a self-citation or to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,”Nature, vol. 521, no. 7553, pp. 436–444, 2015
work page 2015
-
[2]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2009, pp. 248–255
work page 2009
-
[3]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto, Technical Report, 2009
work page 2009
-
[4]
Tiny ImageNet visual recognition challenge,
Y. Le and X. Yang, “Tiny ImageNet visual recognition challenge,” Stanford CS231n Course Project, 2015
work page 2015
-
[5]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778
work page 2016
-
[6]
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
F. N. Iandola et al., “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and less than 0.5MB model size,” arXiv:1602.07360, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
MobileNetV2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 4510–4520
work page 2018
-
[8]
ShuffleNet V2: Practical guidelines for efficient CNN architecture design,
N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “ShuffleNet V2: Practical guidelines for efficient CNN architecture design,” inProc. Eur. Conf. Comput. Vis., 2018, pp. 116–131. 17
work page 2018
-
[9]
A. Howard et al., “Searching for MobileNetV3,” inProc. IEEE Int. Conf. Comput. Vis., 2019, pp. 1314–1324
work page 2019
-
[10]
EfficientNet: Rethinking model scaling for convolutional neural networks,
M. Tan and Q. Le, “EfficientNet: Rethinking model scaling for convolutional neural networks,” inProc. Int. Conf. Mach. Learn., 2019, pp. 6105–6114
work page 2019
-
[11]
EfficientNetV2: Smaller models and faster training,
M. Tan and Q. Le, “EfficientNetV2: Smaller models and faster training,” inProc. Int. Conf. Mach. Learn., 2021, pp. 10096–10106
work page 2021
-
[12]
MobileOne: An improved one millisecond mobile backbone,
P. K. A. Vasu, J. Gabriel, J. Zhu, O. Tuzel, and A. Ranjan, “MobileOne: An improved one millisecond mobile backbone,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 7907–7917
work page 2023
-
[13]
Run, Don’t Walk: Chasing higher FLOPS for faster neural networks,
J. Chen et al., “Run, Don’t Walk: Chasing higher FLOPS for faster neural networks,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 12021–12031
work page 2023
-
[14]
FastViT: A fast hybrid vision transformer using structural reparameterization,
P. K. A. Vasu, J. Gabriel, J. Zhu, O. Tuzel, and A. Ranjan, “FastViT: A fast hybrid vision transformer using structural reparameterization,” inProc. IEEE/CVF Int. Conf. Comput. Vis., 2023, pp. 5785–5795
work page 2023
-
[15]
RepViT: Revisiting mobile CNN from ViT perspective,
A. Wang, H. Chen, Z. Lin, J. Han, and G. Ding, “RepViT: Revisiting mobile CNN from ViT perspective,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 15909–15920
work page 2024
-
[16]
MobileNetV4: Universal models for the mobile ecosystem,
D. Qin et al., “MobileNetV4: Universal models for the mobile ecosystem,” inProc. Eur. Conf. Comput. Vis., 2024, pp. 78–96
work page 2024
-
[17]
X. Ma, X. Dai, Y. Bai, Y. Wang, and Y. Fu, “Rewrite the Stars,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 5694–5703
work page 2024
-
[18]
LSNet: See Large, Focus Small,
A. Wang, H. Chen, Z. Lin, J. Han, and G. Ding, “LSNet: See Large, Focus Small,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2025, pp. 9718–9729
work page 2025
-
[19]
Y. Wang and W. Xi, “UniConvNet: Expanding effective receptive field while maintaining asymptotically Gaussian distribution for ConvNets of any scale,” inProc. IEEE/CVF Int. Conf. Comput. Vis., 2025, pp. 20922–20933
work page 2025
-
[20]
Do better ImageNet models transfer better?
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Do better ImageNet models transfer better?” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, pp. 2661–2671
work page 2019
-
[21]
Rethinking ImageNet pre-training,
K. He, R. Girshick, and P. Dollár, “Rethinking ImageNet pre-training,” inProc. IEEE Int. Conf. Comput. Vis., 2019, pp. 4918–4927
work page 2019
-
[22]
Battle of the backbones: A large-scale comparison of pretrained models across computer vision tasks,
M. Goldblum et al., “Battle of the backbones: A large-scale comparison of pretrained models across computer vision tasks,” inAdvances in Neural Information Processing Systems, vol. 36, Datasets and Benchmarks Track, 2023
work page 2023
-
[23]
A comprehensive study of transfer learning under constraints,
T. Pégeot, I. Kucher, A. Popescu, and B. Delezoide, “A comprehensive study of transfer learning under constraints,” inProc. IEEE/CVF Int. Conf. Comput. Vis. Workshops, 2023, pp. 1148–1157
work page 2023
-
[24]
R. Tiwari et al., “RCV2023 challenges: Benchmarking model training and inference for resource- constrained deep learning,” inProc. IEEE/CVF Int. Conf. Comput. Vis. Workshops, 2023, pp. 1534–1543
work page 2023
-
[25]
Which backbone to use: A resource-efficient domain specific comparison for computer vision,
P. Jeevan and A. Sethi, “Which backbone to use: A resource-efficient domain specific comparison for computer vision,”Transactions on Machine Learning Research, 2025
work page 2025
-
[26]
Vision backbone efficient selection for image classification in low-data regimes,
J. Guerin, S. Bansal, A. Shaban, P. Mann, and H. Gazula, “Vision backbone efficient selection for image classification in low-data regimes,” inProc. 36th British Mach. Vis. Conf., 2025, Paper 788
work page 2025
-
[27]
T. Shahriar, “Comparative Analysis of Lightweight CNNs for Resource-Constrained Devices: Predictive Performance, Efficiency Trade-offs, and Initialization Effects,” arXiv:2505.03303, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. Int. Conf. Learn. Represent., 2019
work page 2019
-
[29]
SGDR: Stochastic gradient descent with warm restarts,
I. Loshchilov and F. Hutter, “SGDR: Stochastic gradient descent with warm restarts,” inProc. Int. Conf. Learn. Represent., 2017. 18
work page 2017
-
[30]
Rethinking the Inception architecture for computer vision,
C. Szegedy et al., “Rethinking the Inception architecture for computer vision,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 2818–2826
work page 2016
-
[31]
Miettinen,Nonlinear Multiobjective Optimization
K. Miettinen,Nonlinear Multiobjective Optimization. Boston, MA, USA: Kluwer Academic Publishers, 1999
work page 1999
-
[32]
The proof and measurement of association between two things,
C. Spearman, “The proof and measurement of association between two things,”The American Journal of Psychology, vol. 15, no. 1, pp. 72–101, 1904
work page 1904
-
[33]
Note on the sampling error of the difference between correlated proportions or percentages,
Q. McNemar, “Note on the sampling error of the difference between correlated proportions or percentages,” Psychometrika, vol. 12, pp. 153–157, 1947
work page 1947
-
[34]
B. Efron and R. J. Tibshirani,An Introduction to the Bootstrap. New York, NY, USA: Chapman and Hall, 1993
work page 1993
-
[35]
R. Wightman, “PyTorch Image Models,” GitHub repository and Zenodo software archive, 2019. 19
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.