4
Low dimension suffices for near-max retrieval margins
Is Dimensionality a Barrier for Retrieval Models?
Dimension O(m^{-2} log n) nearly matches the infinite-dimension margin for any relevance matrix A.
 full image
full image
abstract click to expand
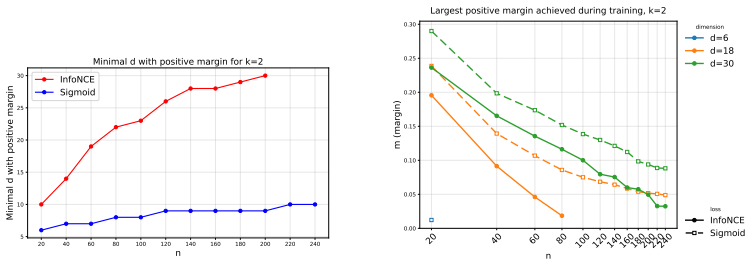
Why does the low dimensionality of representations, typically $d\approx 1000$, not prevent modern embedding-based retrieval models from scaling to billions, or even trillions, of data points? To answer this question, we study maximal-margin embeddings in the following retrieval model, classically studied in communication complexity [PS86] and more recently in embedding-based retrieval [WBNL26]. Let $A\in \{0,1\}^{N\times n}$ be a matrix indicating whether each of $N$ queries is relevant to each of $n$ documents. We are interested in the largest margin $m>0,$ denoted by $\mathsf{m}^{\mathsf{rd}}(d, A),$ for which there exist unit norm embeddings of the queries and documents $\{U_j\}_{j = 1}^N, \{V_i\}_{i = 1}^n$ with the following property. $\langle U_j, V_i\rangle \ge m$ whenever $A_{ji} = 1$ and $\langle U_j, V_i\rangle \le -m$ otherwise. A large margin is a key proxy for representation quality: it controls both robustness to perturbations and compositional generalization across queries. Our main theorem establishes that the best possible margin without a restriction on the dimension, $\mathsf{m}^{\mathsf{rd}}(+\infty, A),$ can be nearly achieved in dimension $d = O(\mathsf{m}^{\mathsf{rd}}(+\infty, A)^{-2}\log n)$ which improves a theorem of [BDES02]. Together with a matching lower bound in Theorem 1.5, we conclude that when $A\in \{0,1\}^{\binom{n}{k}\times n}$ is the matrix containing all possible $k$-sparse rows once, dimension $d = O(k\log (n/k))$ is necessary and sufficient for the maximal possible margin $\mathsf{m}^{\mathsf{rd}}(+\infty, A) = \Theta(k^{-1/2})$ in this setting. This fully resolves the setup of [WBNL26]. We also give several constructions for large margins when $d = o(k\log (n/k)).$ Finally, we empirically test the InfoNCE and sigmoid losses for producing large margin embeddings and demonstrate a clear advantage of the sigmoid loss.

































































