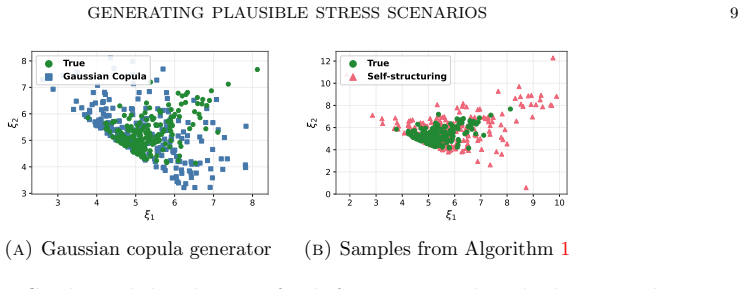
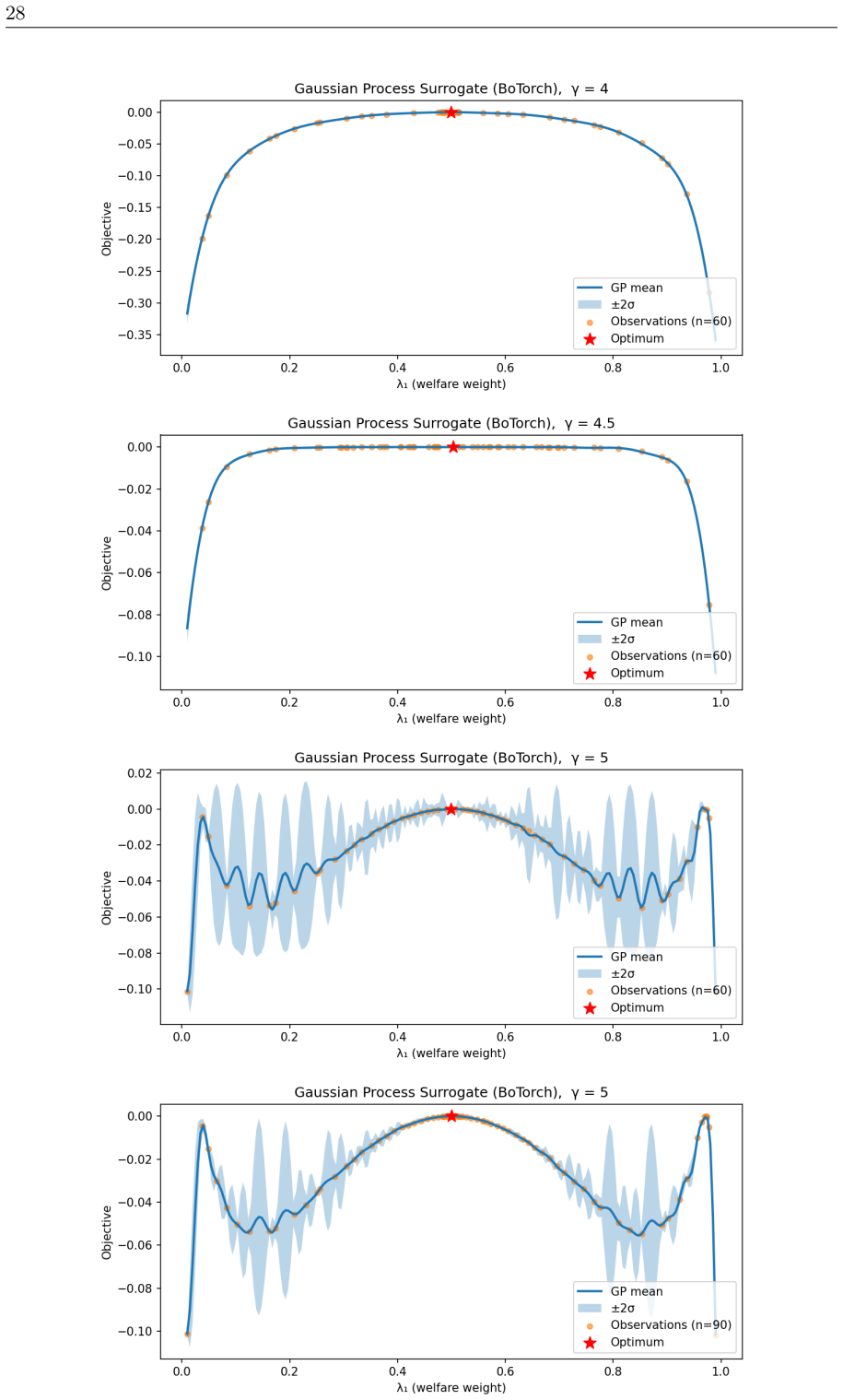
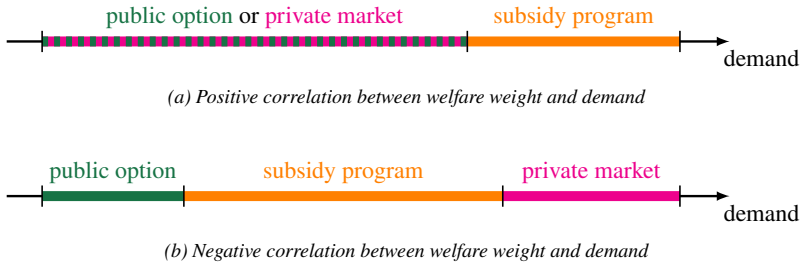
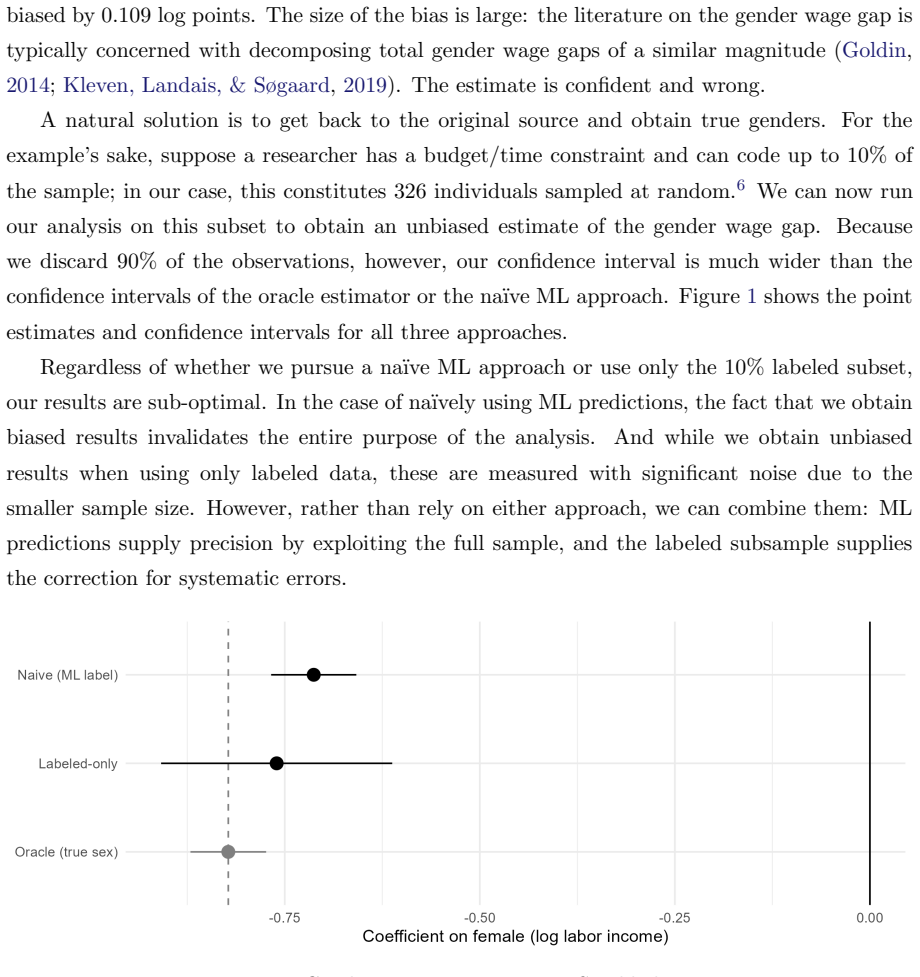
5
Lean 4 verifies arbitrage-free markets admit martingale measures
The Fundamental Theorem of Asset Pricing, Formalized in Lean 4
Explicit minimization of a convex potential replaces Hahn-Banach in the multi-asset one-period case.
 full image
full image
abstract click to expand
The Fundamental Theorem of Asset Pricing states that a market is free of arbitrage exactly when it admits an equivalent martingale measure. We formalize it in Lean 4 over Mathlib in three settings: a finite-state market over a finite horizon (Harrison-Pliska), a one-period market on an arbitrary probability space with a single scalar return (Follmer-Schied), and a one-period market with finitely many assets. The finite case is the geometry of a separating hyperplane; the scalar one-period case is an elementary change of measure. In the $d$-asset case the equivalent martingale measure is constructed explicitly, as the minimiser of the smooth convex potential $\mathbb{E}[\log(1+e^{\langle\theta,Y\rangle})]$: absence of arbitrage is precisely coercivity of the potential, its first-order condition is the martingale property, and the minimiser's logistic weight is the density of the measure. The construction uses no Hahn-Banach theorem, no $L^0$-closedness argument, no measurable selection, and no non-redundancy hypothesis. To our knowledge this is the first machine-checked Fundamental Theorem of Asset Pricing in any proof assistant. The boundary is explicit: the general multi-period Dalang-Morton-Willinger theorem lies outside the development. Every theorem is sorry-free, each headline result's axioms are pinned to Mathlib's classical defaults by a build-enforced gate, and the whole is reproducible from a pinned toolchain.