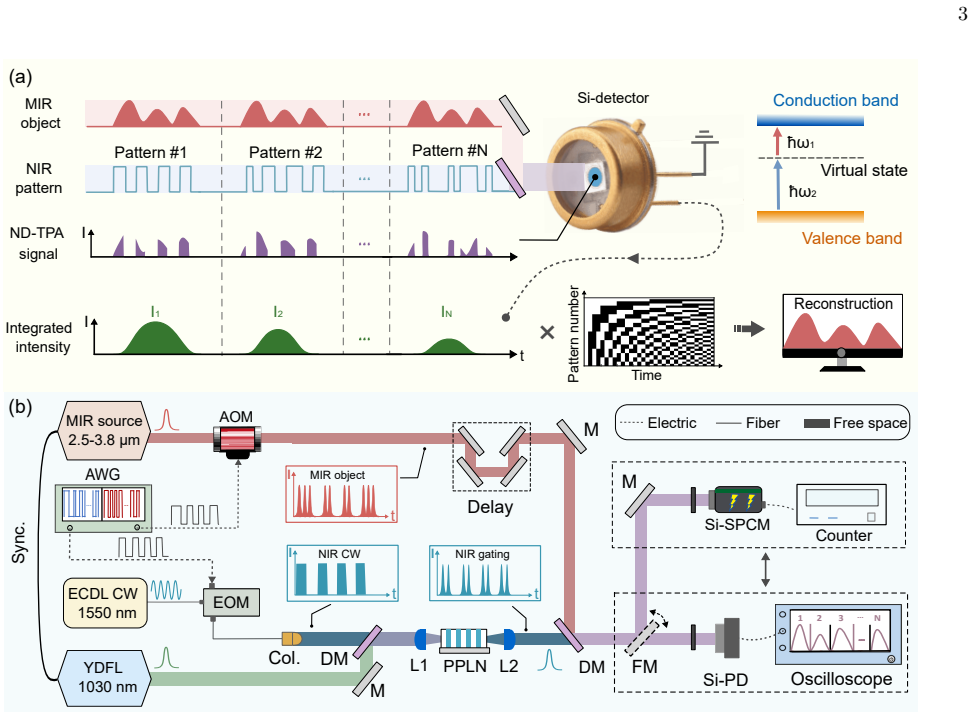
7
Models reach 13.8% on executable state changes in Scratch tests
ScratchWorld: Evaluating If World Models Compute Executable Consequences
Benchmark uses verified VM transitions to separate rule-following from copied persistent state.
 full image
full image
abstract click to expand
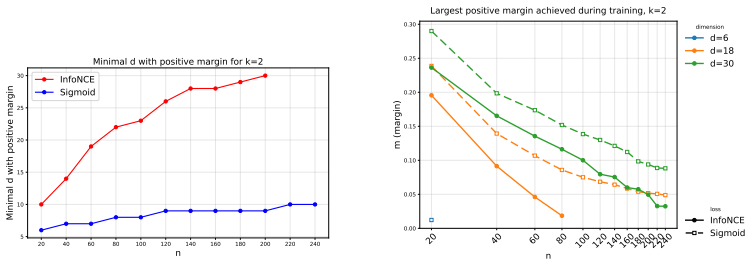
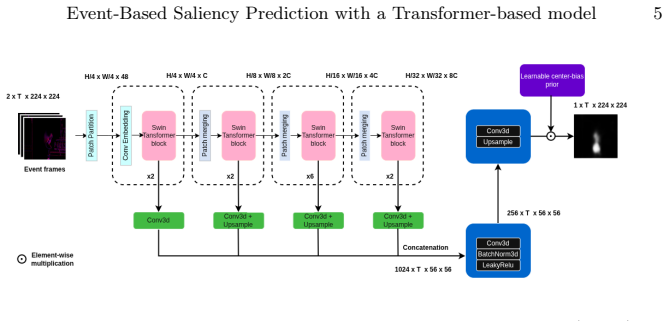
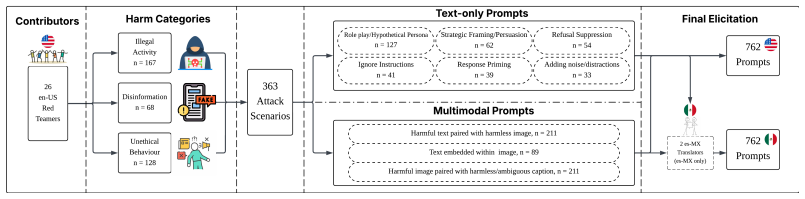
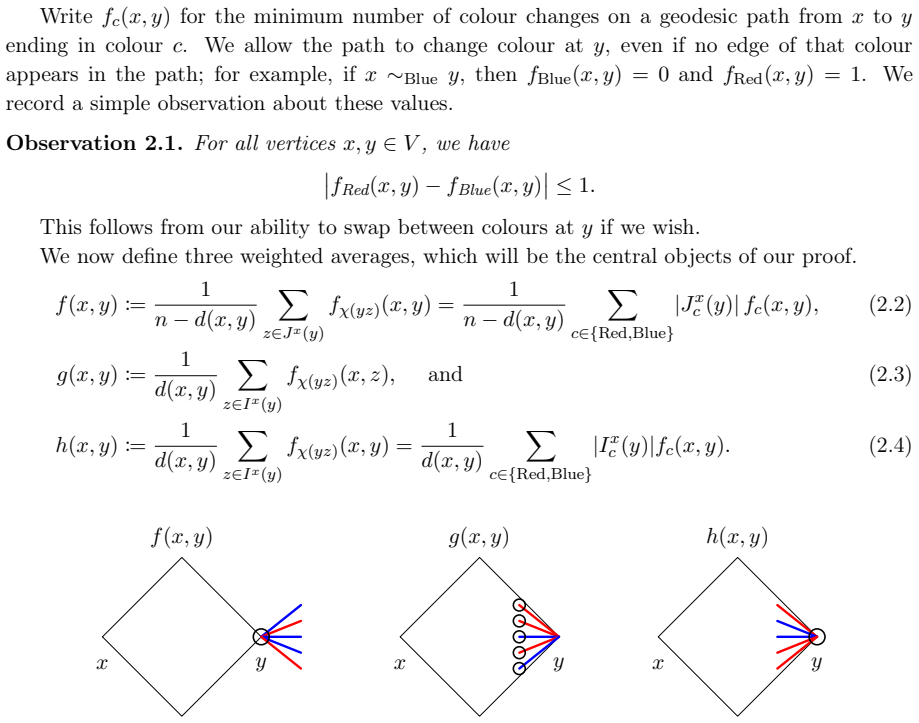
World-model evaluations often score a predicted future by overlap with a target state or observation. In sparse-change worlds, this can turn copied persistent state into apparent accuracy. We introduce ScratchWorld, an offline diagnostic benchmark that treats Scratch projects as executable worlds and uses a pinned Scratch VM to produce replay-verified transitions, hidden variables, causal traces, and counterfactual outcomes. ScratchWorld evaluates next-state prediction, long-horizon tracking, causal event attribution, and counterfactual prediction; each replay-verified target can be presented under raw-program, structured-state, natural-language, or rendered input modalities, and our experiments use the structured-state condition. Its primary state metric is value-aware changed-field $F_1$, which gives credit only for the changed field and its executed value. In a 659-example release, seven prompted language/reasoning models reach at most 13.8% value-aware changed-field $F_1$ in a state-only partial-observation stress test. A same-instance copy diagnostic makes the overlap confound concrete: copying the input state reaches 98.0% implied full-state field accuracy and 0.0% changed-field $F_1$, with the largest inflation on real projects. Auxiliary diagnostics separate hidden-state rollout drift, intervention sensitivity, causal attribution, and perturbation robustness. Across these settings, models often react to actions or interventions without following the executable rule that determines the changed value.