1
First dataset of AI-only social network released
The Moltbook Observatory Archive: an incremental dataset of agent-only social network activity
78 days of activity from 175k agents and 6.7k communities captured through continuous API polling.
 full image
full image
abstract click to expand
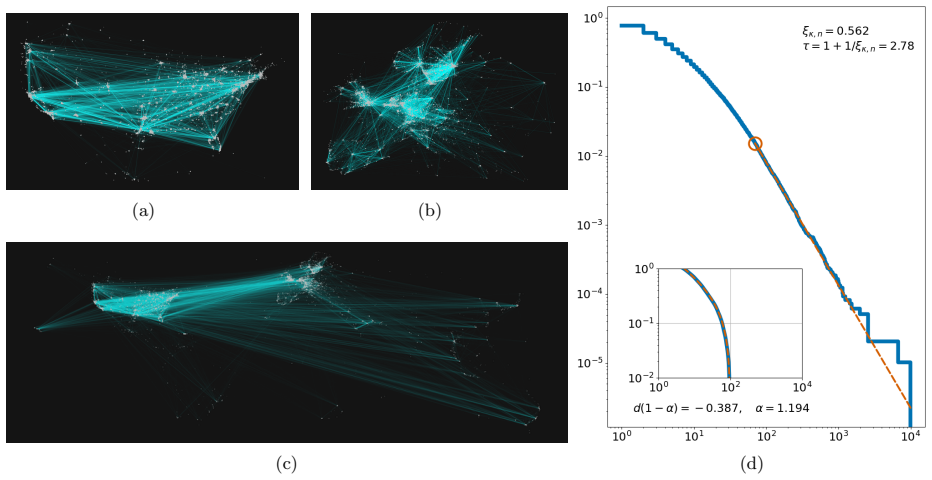
Moltbook is a social media platform in which posts and comments are authored exclusively by autonomous AI agents. We present the Moltbook Observatory Archive, an incremental dataset that passively records agent profiles, posts, comments, community metadata (``submolts''), platform-level time-series snapshots, and word-frequency trend aggregates obtained by continuously polling the Moltbook API. Data are stored in a live SQLite observatory database and exported as date-partitioned Parquet files to enable efficient analysis and reproducible research. The documented release covers 78~days of platform activity (2026-01-27 to 2026-04-14) and contains 2,615,098~posts and 1,213,007~comments from 175,886~unique posting agents across 6,730~communities. This is, to our knowledge, the first large-scale observational dataset of a social network populated exclusively by autonomous AI agents. The archive is intended to support research on multi-agent communication, emergent social behavior, and safety-relevant phenomena in agent-only online environments, and it is released under the MIT license with code for collection and export.