Dual-Regime Absorbing Markov Chain Theory in Remote Estimation: Age-Minimizing Push Policies
Pith reviewed 2026-07-01 02:29 UTC · model grok-4.3
The pith
Dual-regime absorbing Markov chains supply the exact parameters for an SMDP that yields optimal multi-threshold AoII-minimizing push policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The dual-regime absorbing Markov chain (DR-AMC) produces the dual-regime DPH absorption-time distribution that supplies all parameters of an SMDP whose state space equals the original DTMC; solving this SMDP produces the optimal multi-threshold push policy that minimizes the weighted time-average polynomial AoII cost plus energy.
What carries the argument
dual-regime absorbing Markov chain (DR-AMC) and its absorption-time distribution (DR-DPH); these objects generate the exact transition kernel and cost function for the semi-Markov decision process without enlarging the state space beyond the source DTMC.
If this is right
- The optimal policy is always multi-threshold, with thresholds that can depend on the current remote estimate.
- Any discrete phase-type delay distribution can be handled by the same DR-AMC construction.
- The method recovers the classical MDP solution when delays are memoryless.
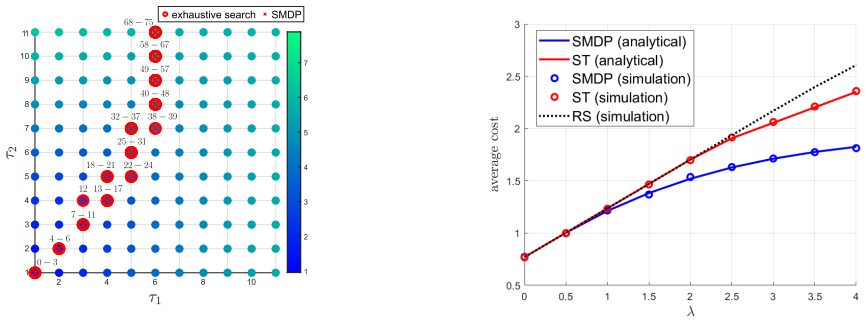
- Numerical examples confirm that the computed thresholds match those found by exhaustive search on small instances.
Where Pith is reading between the lines
- The DR-AMC construction may be reusable for other freshness metrics whose evolution can be tracked by an auxiliary absorbing chain.
- Because the state space remains the size of the source chain, the approach can handle larger source alphabets than methods that augment the state with elapsed time.
- The same dual-regime idea could be adapted to continuous-time Markov sources if an analogous absorption-time distribution is derived.
Load-bearing premise
The reverse channel is perfect, so the source always knows the exact AoII and the monitor's current estimate.
What would settle it
A concrete instance with a small source chain and geometric delay in which the multi-threshold policy returned by the DR-AMC-based SMDP yields strictly higher cost than some non-threshold policy found by exhaustive enumeration of all deterministic policies.
Figures





read the original abstract
For a remote estimation system, we study the optimization of age of incorrect information (AoII), which is a recently proposed semantic-aware information freshness metric. In particular, we assume an information source that observes a discrete-time finite-state Markov chain (DTMC), and occasionally transmits status update packets to a remote monitor which is tasked with remote estimation of the source. For the forward channel from the source to the monitor, we assume the channel delay to be modeled by a general discrete-time phase-type (DPH) distribution, whereas the reverse channel from the monitor to the source is assumed to be perfect, ensuring that the source has perfect information on the AoII and the remote estimate at the monitor, at all times. Push-based transmissions are initiated when AoII exceeds a threshold depending on the current estimation value, i.e., multi-threshold policy. In this very general setting, our goal is to minimize a weighted sum of the time average of a polynomial function of AoII, depending on the remote estimate, and energy consumption from transmissions. We formulate the problem as a semi-Markov decision process (SMDP) with the same state-space of the original DTMC to obtain the optimal multi-threshold policy, whereas the parameters of the SMDP are obtained by using a novel stochastic tool called dual-regime absorbing Markov chain (DR-AMC), and its corresponding absorption time distribution named as dual-regime DPH (DR-DPH). The proposed method is validated with numerical examples using comparisons against other policies obtained by exhaustive search, and also various benchmark policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies AoII minimization in a remote estimation system where the source is a DTMC, forward delays follow a general DPH distribution, and the reverse channel is perfect. It formulates the problem as an SMDP whose state space matches the original DTMC, obtains the optimal multi-threshold push policy, and supplies the required transition probabilities, absorption-time distributions, and costs via a novel dual-regime absorbing Markov chain (DR-AMC) whose absorption distribution is called DR-DPH. Numerical comparisons against exhaustive search and benchmark policies are provided.
Significance. If the DR-AMC construction supplies exact (not approximate) parameters that preserve the Markov property without phase augmentation, the method would allow tractable optimization of polynomial AoII costs under general DPH delays while retaining the source DTMC state space; the numerical validation against exhaustive search would then constitute a concrete strength.
major comments (2)
- [§4 and §5] §4 (DR-AMC construction) and §5 (SMDP formulation): the central claim that the SMDP operates on exactly the original DTMC state space requires an explicit proof that the DR-AMC marginalizes over all DPH phases and all possible source trajectories during the absorption window while preserving the Markov property at decision epochs; without this, the supplied transition probabilities and DR-DPH distribution are incorrect for general DPH delays and the reduced-state SMDP is invalid.
- [Table 1 and Fig. 3] Table 1 and Fig. 3: the reported optimality gaps versus exhaustive search must include error bars or multiple random seeds; a single-run comparison cannot confirm that the DR-AMC parameters produce policies whose performance is statistically indistinguishable from the true optimum.
minor comments (2)
- [§3] Notation for the two regimes in the DR-AMC definition should be introduced with a single diagram that labels the absorbing and transient states in each regime.
- [§2] The polynomial cost function of AoII is stated to depend on the remote estimate; the precise functional form and its dependence on the estimate value should be written explicitly in the problem formulation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below and will incorporate revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [§4 and §5] §4 (DR-AMC construction) and §5 (SMDP formulation): the central claim that the SMDP operates on exactly the original DTMC state space requires an explicit proof that the DR-AMC marginalizes over all DPH phases and all possible source trajectories during the absorption window while preserving the Markov property at decision epochs; without this, the supplied transition probabilities and DR-DPH distribution are incorrect for general DPH delays and the reduced-state SMDP is invalid.
Authors: We agree that an explicit proof of marginalization and Markov property preservation would make the argument more rigorous. The DR-AMC is constructed with two regimes (pre- and post-absorption) whose transient states encode the joint evolution of the DPH phases and the source DTMC; absorption is defined to occur precisely at the first time the source state changes to a value that updates the remote estimate. The transition probabilities and DR-DPH absorption-time distribution are obtained by solving the fundamental matrix and absorption probabilities of this augmented chain, which by construction integrate out both the phase variables and all possible source trajectories within the absorption window. Because the decision epochs coincide with absorption instants and the next state is drawn from the DTMC transition matrix conditional on the current state (independent of prior phases), the Markov property holds with respect to the original DTMC state space. Nevertheless, to address the referee’s concern directly, we will add a dedicated lemma and proof in §4 that formally shows the marginal kernel depends only on the current DTMC state and the chosen thresholds. revision: yes
-
Referee: [Table 1 and Fig. 3] Table 1 and Fig. 3: the reported optimality gaps versus exhaustive search must include error bars or multiple random seeds; a single-run comparison cannot confirm that the DR-AMC parameters produce policies whose performance is statistically indistinguishable from the true optimum.
Authors: We concur that single-run comparisons are insufficient to establish statistical equivalence. The current numerical results were generated from one realization of the exhaustive-search benchmark and one run of the DR-AMC policy. In the revision we will repeat both the exhaustive search and the policy evaluation over multiple independent random seeds (e.g., 20 seeds), recompute the optimality gaps, and report means together with standard-deviation error bars in Table 1 and Figure 3. This will provide quantitative evidence that the performance difference is statistically negligible. revision: yes
Circularity Check
DR-AMC introduced as novel independent tool; derivation self-contained with no reduction to inputs
full rationale
The paper formulates an SMDP whose parameters are supplied by the newly defined DR-AMC and DR-DPH distributions constructed from the given DTMC source and DPH forward delay. No equation or claim in the abstract reduces the SMDP transition probabilities, absorption times, or costs to a fitted quantity or self-citation from the same work; the construction is presented as an external stochastic analysis that preserves the original DTMC state space. This satisfies the default expectation of a non-circular derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Forward channel delay follows a general discrete-time phase-type distribution.
- domain assumption Reverse channel is perfect, providing the source with exact AoII and remote estimate at all times.
invented entities (2)
-
dual-regime absorbing Markov chain (DR-AMC)
no independent evidence
-
dual-regime DPH (DR-DPH)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sensor networks: An overview,
A. Bharathidasan and V . A. S. Ponduru, “Sensor networks: An overview,”Dept. Comput. Sci., Univ. California, Davis, CA, USA, Tech. Rep., 2002
2002
-
[2]
Real-time status: How often should one update?
S. Kaul, R. Yates, and M. Gruteser, “Real-time status: How often should one update?” inIEEE Infocom, March 2012
2012
-
[3]
Age of information: An introduction and survey,
R. D. Yates, Y . Sun, D. R. Brown, S. K. Kaul, E. Modiano, and S. Ulukus, “Age of information: An introduction and survey,”IEEE J. Sel. Areas Commun., vol. 39, no. 5, pp. 1183–1210, May 2021
2021
-
[4]
The age of incorrect information: A new performance metric for status updates,
A. Maatouk, S. Kriouile, M. Assaad, and A. Ephremides, “The age of incorrect information: A new performance metric for status updates,” IEEE/ACM Trans. Netw., vol. 28, no. 5, pp. 2215–2228, October 2020
2020
-
[5]
H. V . Poor,An Introduction to Signal Detection and Estimation. Springer Science & Business Media, 2013
2013
-
[6]
Timely gossip on lines: Hybrid ageing,
H. Xu, J. Pan, Y . Xu, S. Shao, and T. Song, “Timely gossip on lines: Hybrid ageing,” inIEEE ISIT, July 2025
2025
-
[7]
Preempting to minimize age of in- correct information under random delay,
Y . Chen and A. Ephremides, “Preempting to minimize age of in- correct information under random delay,” 2022, available online at arXiv:2209.14254
-
[8]
The age of incorrect in- formation: An enabler of semantics-empowered communication,
A. Maatouk, M. Assaad, and A. Ephremides, “The age of incorrect in- formation: An enabler of semantics-empowered communication,”IEEE Trans. Wireless Comm., vol. 22, no. 4, pp. 2621–2635, October 2022
2022
-
[9]
Age of incorrect information with hybrid ARQ under a resource constraint forN-ary symmetric Markov sources,
K. Bountrogiannis, A. Ephremides, P. Tsakalides, and G. Tzagkarakis, “Age of incorrect information with hybrid ARQ under a resource constraint forN-ary symmetric Markov sources,”IEEE/ACM Trans. on Netwk., vol. 33, no. 2, pp. 640–653, November 2024
2024
-
[10]
Modeling AoII in push- and pull- based sampling of continuous time Markov chains,
I. Cosandal, N. Akar, and S. Ulukus, “Modeling AoII in push- and pull- based sampling of continuous time Markov chains,” inIEEE Infocom, May 2024
2024
-
[11]
Multi-threshold AoII-optimum sampling policies for continuous- time Markov chain information sources,
——, “Multi-threshold AoII-optimum sampling policies for continuous- time Markov chain information sources,”IEEE Trans. Inf. Theory, vol. 71, no. 9, pp. 6968–6988, July 2024
2024
-
[12]
Semantic-aware sampling and transmission in real-time tracking systems: A POMDP approach,
A. Zakeri, M. Moltafet, and M. Codreanu, “Semantic-aware sampling and transmission in real-time tracking systems: A POMDP approach,” IEEE Trans. Commun., vol. 73, no. 7, pp. 4898–4913, December 2024
2024
-
[13]
Age-minimal transmission for energy harvesting sensors with finite batteries: Online policies,
A. Arafa, J. Yang, S. Ulukus, and H. V . Poor, “Age-minimal transmission for energy harvesting sensors with finite batteries: Online policies,”IEEE Trans. Inf. Theory, vol. 66, no. 1, pp. 534–556, September 2019
2019
-
[14]
Timely status updating over erasure channels using an energy harvesting sensor: Single and multiple sources,
——, “Timely status updating over erasure channels using an energy harvesting sensor: Single and multiple sources,”IEEE Trans. Green Comm. Netwk., vol. 6, no. 1, pp. 6–19, August 2021
2021
-
[15]
Age of information in internet of things: A survey,
I. Kahraman, A. K ¨ose, M. Koca, and E. Anarim, “Age of information in internet of things: A survey,”IEEE Internet Things J., vol. 11, no. 6, pp. 9896–9914, October 2023
2023
-
[16]
On the cost of consecutive estimation error: Significance-aware non-linear aging,
J. Luo and N. Pappas, “On the cost of consecutive estimation error: Significance-aware non-linear aging,”IEEE Trans. Inf. Theory, vol. 71, no. 10, pp. 7976–7989, July 2025
2025
-
[17]
Minimization of age of incorrect estimates of autoregressive Markov processes,
B. Joshi, R. V . Bhat, B. N. Bharath, and R. Vaze, “Minimization of age of incorrect estimates of autoregressive Markov processes,” inWiOpt, October 2021
2021
-
[18]
Bidirectional age of incorrect information: A performance metric for status updates in virtual dynamic environments,
C. Schiavo, M. Favero, A. Buratto, and L. Badia, “Bidirectional age of incorrect information: A performance metric for status updates in virtual dynamic environments,” inMetaCom, August 2025
2025
-
[19]
J. G. Kemeny and J. L. Snell,Finite Markov Chains. Springer, 1960
1960
-
[20]
Lakatos, L
L. Lakatos, L. Szeidl, and M. Telek,Introduction to Queueing Systems with Telecommunication Applications, 2nd ed. New York, NY , USA: Springer, 2019
2019
-
[21]
Distribution of age of information in status update systems with heterogeneous information sources: An absorbing Markov chain-based approach,
N. Akar and E. O. Gamgam, “Distribution of age of information in status update systems with heterogeneous information sources: An absorbing Markov chain-based approach,”IEEE Commun. Lett., vol. 27, no. 8, pp. 2024–2028, May 2023
2024
-
[22]
Age of information in a single-source generate- at-will dual-server status update system,
N. Akar and S. Ulukus, “Age of information in a single-source generate- at-will dual-server status update system,”IEEE Trans. Commun., vol. 73, no. 9, pp. 7431–7444, February 2025
2025
-
[23]
Energy-age of incorrect information trade-off with timer-based sleep-wake scheduling,
O. Gursoy and N. Akar, “Energy-age of incorrect information trade-off with timer-based sleep-wake scheduling,” inIEEE PIMRC, September 2025
2025
-
[24]
The age of information in networks: Moments, distri- butions, and sampling,
R. D. Yates, “The age of information in networks: Moments, distri- butions, and sampling,”IEEE Trans. Inf. Theory, vol. 66, no. 9, pp. 5712–5728, May 2020
2020
-
[25]
Moment generating func- tion of age of information in multisource M/G/1/1 queueing systems,
M. Moltafet, M. Leinonen, and M. Codreanu, “Moment generating func- tion of age of information in multisource M/G/1/1 queueing systems,” IEEE Trans. Commun., vol. 70, no. 10, pp. 6503–6516, August 2022
2022
-
[26]
State-aware resource allocation for wireless closed-loop control systems,
L. Scheuvens, T. H ¨oßler, P. Schulz, N. Franchi, A. N. Barreto, and G. P. Fettweis, “State-aware resource allocation for wireless closed-loop control systems,”IEEE Trans. Commun., vol. 69, no. 10, pp. 6604–6619, July 2021
2021
-
[27]
Age-dependent server selection in a dual-server status update system,
N. Akar, I. Cosandal, and S. Ulukus, “Age-dependent server selection in a dual-server status update system,” inAsilomar Conference, October 2025
2025
-
[28]
D. J. White,Markov Decision Processes. John Wiley & Sons, 1993
1993
-
[29]
Strang,Linear Algebra and Its Applications
G. Strang,Linear Algebra and Its Applications. Cengage Learning, 2006
2006
-
[30]
Latouche and V
G. Latouche and V . Ramaswami,Introduction to Matrix Analytic Meth- ods in Stochastic Modeling. SIAM, 1999
1999
-
[31]
R. L. Graham,Concrete Mathematics: A Foundation for Computer Science. Addison-Wesley, 1994
1994
-
[32]
S. M. Ross,Applied Probability Models with Optimization Applications. Dover Publications, 1992
1992
-
[33]
Ibe,Markov Processes for Stochastic Modeling
O. Ibe,Markov Processes for Stochastic Modeling. Newnes, 2013
2013
-
[34]
H. C. Tijms,A First Course in Stochastic Models. Wiley, N.Y ., 2003
2003
-
[35]
Query-based sampling of heterogeneous CTMCs: modeling and optimization with binary freshness,
N. Akar and S. Ulukus, “Query-based sampling of heterogeneous CTMCs: modeling and optimization with binary freshness,”IEEE Trans. Commun., vol. 72, no. 12, pp. 7705–7714, December 2024
2024
-
[36]
Joint age-state belief is all you need: Minimizing AoII via pull-based remote estimation,
I. Cosandal, S. Ulukus, and N. Akar, “Joint age-state belief is all you need: Minimizing AoII via pull-based remote estimation,” inIEEE ICC, May 2025
2025
-
[37]
Which sensor to observe? Timely tracking of a joint Markov source with model predictive control,
——, “Which sensor to observe? Timely tracking of a joint Markov source with model predictive control,” inIEEE ISIT, June 2025
2025
-
[38]
The Stirling numbers of the second kind and their applications,
S. Bagui and K. Mehra, “The Stirling numbers of the second kind and their applications,”Ala. J. math., vol. 47, no. 1, pp. 1–22, 2024
2024
-
[39]
Estimation and optimal control for constrained Markov chains,
D. J. Ma, A. M. Makowski, and A. Shwartz, “Estimation and optimal control for constrained Markov chains,” inIEEE CDC, December 1986
1986
-
[40]
Randomized and past-dependent policies for Markov decision processes with multiple constraints,
K. W. Ross, “Randomized and past-dependent policies for Markov decision processes with multiple constraints,”Operations Research, vol. 37, no. 3, pp. 474–477, May 1989
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.