Unveiling the Non-Monotonic Effect of Privacy on Generalization under Byzantine Robustness
Pith reviewed 2026-07-03 20:55 UTC · model grok-4.3
The pith
Privacy reduces generalization error under strong Byzantine robustness but increases it when privacy is weaker.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
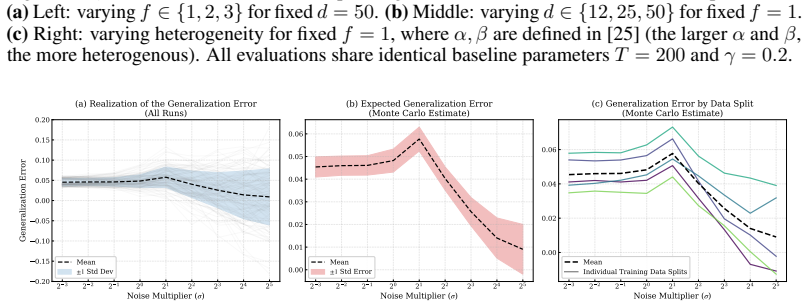
In the high-noise regime of strong privacy, increasing the privacy level reduces the generalization error, so there is no tension between Byzantine robustness and privacy. In the low-noise regime of weaker privacy, increasing privacy raises the generalization error and the tension reappears. This behavior is established by proving matching lower and upper bounds on the algorithmic stability of Byzantine-robust distributed learning under local differential privacy constraints, with the theoretical predictions confirmed by experiments.
What carries the argument
Matching lower and upper bounds on algorithmic stability of Byzantine-robust distributed learning under local differential privacy constraints.
If this is right
- The trilemma between robustness, privacy, and optimization error does not carry over to generalization error in all regimes.
- In high-noise settings, stronger privacy and Byzantine robustness can be increased together without harming generalization.
- In low-noise settings, increasing privacy while maintaining robustness will increase generalization error.
- The non-monotonic dependence is fully characterized by the stability bounds rather than by optimization error alone.
Where Pith is reading between the lines
- Designers of private robust systems could choose noise levels to sit in the high-noise regime when generalization is the priority.
- The same stability analysis might apply to other aggregation rules or attack models beyond the Byzantine case studied here.
- If the matching bounds hold for neural networks, the non-monotonic effect would appear in large-scale private federated learning.
Load-bearing premise
The proof depends on being able to match lower and upper bounds on algorithmic stability exactly for the chosen data distribution, loss, and aggregation rules.
What would settle it
A calculation or experiment that produces a generalization error that fails to decrease with stronger privacy in the high-noise regime, or fails to increase in the low-noise regime, would falsify the central claim.
Figures




read the original abstract
Recent work has established a fundamental trilemma between Byzantine robustness, local differential privacy (LDP), and optimization error in distributed learning. We show that this trilemma does not universally extend to generalization error, but instead depends critically on the privacy regime. Specifically, in the high-noise regime (strong privacy), we prove that increasing privacy reduces the generalization error, i.e., there is no tension between robustness and privacy. In the low-noise regime (weaker privacy), however, the tension between robustness and privacy reappears and increasing privacy indeed degrades generalization. Our theory explains this surprising non-monotonic behavior of the generalization error via matching lower and upper bounds on the algorithmic stability of Byzantine-robust distributed learning under LDP constraints. We corroborate and further analyze these theoretical findings with empirical evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the established trilemma between Byzantine robustness, local differential privacy (LDP), and optimization error does not universally extend to generalization error. Instead, generalization exhibits non-monotonic behavior with privacy strength: in the high-noise regime (strong privacy), increasing privacy reduces generalization error with no tension between robustness and privacy; in the low-noise regime (weaker privacy), the tension reappears and increasing privacy degrades generalization. This is explained via matching lower and upper bounds on algorithmic stability of Byzantine-robust distributed learning under LDP constraints, corroborated by empirical evaluations.
Significance. If the matching stability bounds hold under the stated conditions, the result is significant for distributed learning as it identifies privacy regimes where robustness and privacy are compatible for generalization (unlike optimization error), offering practical guidance and resolving an apparent universal tension. The use of matching bounds to explain the non-monotonicity is a strength, as is the empirical analysis; however, the result's generality depends on the regularity conditions used in the stability analysis.
major comments (3)
- [Stability bounds derivation (theorems establishing matching bounds)] The central non-monotonic claim rests on matching lower/upper algorithmic stability bounds that are regime-dependent on privacy noise scale and Byzantine fraction. The analysis must explicitly list the required assumptions on loss smoothness, strong convexity or uniform Lipschitzness, data moments (e.g., bounded fourth moments), and aggregator contraction properties (e.g., trimmed mean vs. Krum); without these, the bounds may fail to match for standard problem instances and the high-noise 'no tension' result does not hold.
- [High-noise regime analysis] § on high-noise regime: the proof that increasing privacy reduces generalization error relies on the upper stability bound dominating the lower bound. If the lower bound construction requires additional regularity conditions not listed in the main theorem statement, the claimed absence of tension is not guaranteed to hold beyond the specific loss and distribution considered.
- [Low-noise regime analysis] The low-noise regime claim that tension reappears (increasing privacy degrades generalization) similarly depends on the bounds matching only under the unstated conditions; a counterexample under standard Lipschitz losses without strong convexity would undermine the regime-dependent distinction.
minor comments (2)
- [Preliminaries] Notation for the privacy noise scale and Byzantine fraction should be introduced consistently in the problem setup before the stability theorems.
- [Experiments] Empirical section: clarify the exact aggregator used in experiments and whether it matches the one analyzed in the bounds.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback, which highlights important aspects of our stability analysis. We address each major comment below and commit to revisions that enhance the clarity and explicitness of our assumptions without altering the core claims.
read point-by-point responses
-
Referee: [Stability bounds derivation (theorems establishing matching bounds)] The central non-monotonic claim rests on matching lower/upper algorithmic stability bounds that are regime-dependent on privacy noise scale and Byzantine fraction. The analysis must explicitly list the required assumptions on loss smoothness, strong convexity or uniform Lipschitzness, data moments (e.g., bounded fourth moments), and aggregator contraction properties (e.g., trimmed mean vs. Krum); without these, the bounds may fail to match for standard problem instances and the high-noise 'no tension' result does not hold.
Authors: We agree that a consolidated list of assumptions will improve readability. While the manuscript states the assumptions within the theorem statements and proofs (e.g., L-smoothness and μ-strong convexity of the loss, bounded fourth moments on gradients, and contraction properties specific to trimmed mean and Krum aggregators), we will revise by adding an explicit 'Assumptions' subsection in Section 3 that enumerates all conditions used for the matching bounds. This addresses the concern directly and ensures the regime-dependent results are clearly scoped. revision: yes
-
Referee: [High-noise regime analysis] § on high-noise regime: the proof that increasing privacy reduces generalization error relies on the upper stability bound dominating the lower bound. If the lower bound construction requires additional regularity conditions not listed in the main theorem statement, the claimed absence of tension is not guaranteed to hold beyond the specific loss and distribution considered.
Authors: The lower and upper bounds in the high-noise regime are derived under identical assumptions (L-smooth μ-strongly convex losses with bounded moments and aggregator contraction), as detailed in the proof of the relevant theorem. The domination leading to no tension is shown algebraically when the privacy noise scale exceeds a threshold depending on the Byzantine fraction. We will add a remark in the theorem statement and a clarifying paragraph in the high-noise section to explicitly reference these shared conditions and note that the result holds under them. revision: yes
-
Referee: [Low-noise regime analysis] The low-noise regime claim that tension reappears (increasing privacy degrades generalization) similarly depends on the bounds matching only under the unstated conditions; a counterexample under standard Lipschitz losses without strong convexity would undermine the regime-dependent distinction.
Authors: The low-noise regime analysis requires strong convexity for the lower bound to match the upper bound tightly, as stated in the theorem; without it the distinction may not hold in the same form. We will revise to include an explicit discussion of this assumption's role, add a remark on potential differences for merely Lipschitz (non-strongly convex) losses, and note the scope of the claimed tension reappearance. This clarifies the conditions without changing the main results. revision: yes
Circularity Check
No circularity: matching stability bounds derived independently of inputs
full rationale
The paper's central result is a proof of matching lower and upper bounds on algorithmic stability for Byzantine-robust LDP learning, used to explain the non-monotonic generalization behavior across privacy regimes. No equations, parameters, or predictions are shown to reduce to fitted inputs or self-citations by construction. The abstract and context present the bounds as derived from the model assumptions without self-referential fitting or renaming of known results. This is the expected self-contained theoretical derivation; no load-bearing step collapses to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions on loss functions, data distributions, and aggregation in distributed learning
Reference graph
Works this paper leans on
-
[1]
Y . Allouah, S. Farhadkhani, R. Guerraoui, N. Gupta, R. Pinot, and J. Stephan. Fixing by mixing: A recipe for optimal byzantine ml under heterogeneity. InAISTATS, 2023
work page 2023
-
[2]
Y . Allouah, R. Guerraoui, N. Gupta, R. Pinot, and J. Stephan. On the privacy-robustness-utility trilemma in distributed learning. InICML, 2023
work page 2023
-
[3]
Y . Allouah, R. Guerraoui, and J. Stephan. Towards trustworthy federated learning with untrusted partici- pants. InICML, 2025
work page 2025
-
[4]
A. Attia and T. Koren. Algorithmic instabilities of accelerated gradient descent.NeurIPS, 2021
work page 2021
-
[5]
Bach.Learning Theory from First Principles
F. Bach.Learning Theory from First Principles. Adaptive Computation and Machine Learning series. MIT Press, 2024
work page 2024
-
[6]
S. Boucheron, G. Lugosi, and P. Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2013
work page 2013
- [7]
-
[8]
O. Bousquet and A. Elisseeff. Stability and generalization.JMLR, 2:499–526, 2002
work page 2002
-
[9]
W. G. Cochran. The distribution of quadratic forms in a normal system, with applications to the analysis of covariance.Mathematical Proceedings of the Cambridge Philosophical Society, 30(2):178–191, 1934
work page 1934
-
[10]
L. Devroye and T. Wagner. Distribution-free performance bounds for potential function rules.IEEE Transactions on Information Theory, IT-25:601 – 604, 10 1979
work page 1979
-
[11]
J. Dong, A. Roth, and W. J. Su. Gaussian differential privacy.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 84(1):3–37, 2022
work page 2022
-
[12]
J. C. Duchi, M. I. Jordan, and M. J. Wainwright. Local privacy, data processing inequalities, and statistical minimax rates.arXiv preprint arXiv:1302.3203, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
- [13]
-
[14]
S. Farhadkhani, R. Guerraoui, O. Villemaud, et al. An equivalence between data poisoning and byzantine gradient attacks. InICML, 2022
work page 2022
- [15]
-
[16]
M. González, R. Guerraoui, R. Pinot, G. Rizk, J. Stephan, and F. Taïani. Byzfl: Research framework for robust federated learning.arXiv preprint arXiv:2505.24802, 2025
-
[17]
R. Guerraoui, N. Gupta, and R. Pinot. Byzantine machine learning: A primer.ACM Computing Surveys, 56(7), 2024
work page 2024
- [18]
-
[19]
P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings, R. G. L. D’Oliveira, H. Eichner, S. E. Rouayheb, D. Evans, J. Gardner, Z. Garrett, A. Gascón, B. Ghazi, P. B. Gibbons, M. Gruteser, Z. Harchaoui, C. He, L. He, Z. Huo, B. Hutchinson, J. Hsu, M. Jaggi, T. Javidi, G. Joshi, M. Khodak, ...
work page 2021
-
[20]
S. P. Karimireddy, L. He, and M. Jaggi. Learning from history for byzantine robust optimization. InICML, 2021
work page 2021
-
[21]
A. Krizhevsky. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[22]
L. Lamport, R. Shostak, and M. Pease. The byzantine generals problem.ACM Transactions on Program- ming Languages and Systems, 4(3):382–401, 1982. 11
work page 1982
-
[23]
B. Laurent and P. Massart. Adaptive estimation of a quadratic functional by model selection.Annals of Statistics, 28, 10 2000
work page 2000
- [24]
-
[25]
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith. Federated optimization in heterogeneous networks.MLSys, 2020
work page 2020
-
[26]
G. Neu, G. K. Dziugaite, M. Haghifam, and D. M. Roy. Information-theoretic generalization bounds for stochastic gradient descent. InCOLT, 2021
work page 2021
- [27]
-
[28]
A. Ramezani-Kebrya, K. Antonakopoulos, V . Cevher, A. Khisti, and B. Liang. On the generalization of stochastic gradient descent with momentum.JMLR, 25(22):1–56, 2024
work page 2024
-
[29]
R. Reshef and K. Y . Levy. Private and federated stochastic convex optimization: Efficient strategies for centralized systems. InICML, 2024
work page 2024
-
[30]
W. Rogers and T. Wagner. A finite sample distribution-free performance bound for local discrimination rules.The Annals of Statistics, 6, 05 1978
work page 1978
-
[31]
M. Rudelson and R. Vershynin. Hanson-wright inequality and sub-gaussian concentration. 2013
work page 2013
-
[32]
S. Shalev-Shwartz, O. Shamir, N. Srebro, and K. Sridharan. Learnability, stability and uniform convergence. JMLR, 11(90):2635–2670, 2010
work page 2010
-
[33]
V . Vapnik and A. Chervonenkis. Theory of pattern recognition.Nauka, 1974
work page 1974
-
[34]
Vershynin.High-Dimensional Probability: An Introduction with Applications in Data Science
R. Vershynin.High-Dimensional Probability: An Introduction with Applications in Data Science. Cam- bridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2018
work page 2018
-
[35]
D. Wang, M. Gaboardi, A. Smith, and J. Xu. Empirical risk minimization in the non-interactive local model of differential privacy.JMLR, 21(200):1–39, 2020
work page 2020
-
[36]
Y .-X. Wang, J. Lei, and S. E. Fienberg. Learning with differential privacy: Stability, learnability and the sufficiency and necessity of erm principle.JMLR, 17(183):1–40, 2016
work page 2016
-
[37]
C. Xie, O. Koyejo, and I. Gupta. Fall of empires: Breaking byzantine-tolerant sgd by inner product manipulation. InUAI, 2020
work page 2020
-
[38]
sup ∥v∥2≤1 1 |H| X i∈H ⟨v,eg(i) t −egt⟩2 # =E
J. Ye and R. Shokri. Differentially private learning needs hidden state (or much faster convergence). In NeurIPS, 2022. 12 A Stability or DP implies generalization in robust distributed learning In this section, we focus on the formal link between uniform stability and generalization under Byzantine failures. The proof follows classic arguments [8]. Propo...
work page 2022
-
[39]
+p 2( s 2) =e − c1 16 (n−f−1) min{ n−f−1 16(n−2f) ,1} +e − (n−f)(n−f−1) 2048f . As a result, P \ t∈{ntest+1,...,T} E3,t ≥ 1−p 1( s 2)−p 2( s 2) T−n test = 1−e − c1 16 (n−f−1) min{ n−f−1 16(n−2f) ,1} −e − (n−f)(n−f−1) 2048f T−n test ∈Ω(1)if and only ifT∈ O min{e c1 16 (n−f−1) min{ n−f−1 16(n−2f) ,1}, e (n−f)(n−f−1) 2048f } . (ii) Under E1 and the t...
-
[40]
There exists a constantα min >0such thatα := f n−f ∈[α min,1/2)
-
[41]
3.µ > µ min and n−f−1≥N min, where µmin and Nmin are constants that depends on assumption 1
There exist constantsµ, ν >0such thatµ≤ d n−f ≤ν. 3.µ > µ min and n−f−1≥N min, where µmin and Nmin are constants that depends on assumption 1. & 2., and the problem spectral and finite-sample structure. That is, µmin := 4 c2max(1−r max) , and Nmin := max 3(√ν+ √1−α min + max{C1, C2}) 1− √1−α min 2 , 16 min(1, ν) cδ √µ q 2 + αminµc2 min(1,ν) , ...
-
[42]
We identifyΣ 22 analogously. To bound the maximal eigenvalue,λmax(ΣSt) = supv∈Sd−1 v⊺ΣSt v, we aim at upper bounding (25), v⊺ΣSt v≤x 2Σ11 +y 2λmax(Σ22) + 2|xy|∥Σ12∥2 = (|x| |y| ) Σ11 ∥Σ12∥2 ∥Σ12∥2 λmax(Σ22) |x| |y| , 6For any intermediate subset Sk containing exactly 0< k < f Byzantine vectors, the expected variance along the direction e1 introduces a bet...
-
[43]
– The lower tail ∥Σ12∥2 ≤U 12 − δ 4.First, note that if U12 < δ 4 the probability of the event is 0
Defineτ := δU12 8 , we have P ∥Σ12∥2 ≥U 12 + δ 4 =P ∥Σ12∥2 2 ≥U 2 12 + δ 2 U12 + δ2 16 =P ∥Σ12∥2 2 ≥E∥Σ 12∥2 2 +τ+ G+ 3δU12 8 + δ2 16 ≥P ∥Σ12∥2 2 ≥E∥Σ 12∥2 2 +τ . – The lower tail ∥Σ12∥2 ≤U 12 − δ 4.First, note that if U12 < δ 4 the probability of the event is 0. We only need to control the regime where U12 > δ 4, which is equivalent to 2τ= δU12 4 ≥ δ2
-
[44]
Under this condition, the squared lower tail event write ∥Σ12∥2 2 ≤U 2 12 − δ 2 U12 + δ2 16 =E∥Σ 12∥2 2 −τ−(2τ− δ2 16)−(τ−G) Hence, ifG≤τ, which we prove below, we have P ∥Σ12∥2 ≤U 12 − δ 4 =P ∥Σ12∥2 2 ≤U 2 12 − δ 2 U12 + δ2 16 =P ∥Σ12∥2 2 ≤E∥Σ 12∥2 2 −τ−(2τ− δ2 16)−(τ−G) ≥P ∥Σ12∥2 2 ≤E∥Σ 12∥2 2 −τ . –EnsuringG≤τ.Recall thatG 2 = α2(1−α)4 (n−f)2 σ4 DPU4 V...
-
[45]
Substituting tA = min{ τ 3(d−1) ,p τ 3 }= min{ δU12 24(d−1) , q δU12 24 }, the exponent forP(|Q| ≥t A/2)is EQ :=C A min δ2U2 12 2304∥MA∥2 F (d−1) 2 , δU12 96∥MA∥2 F , δU12 48v2 1(d−1) , √δU12 2 √ 24v2 1 . ForL∼ N(0,4v 4 2β2(n−2f)), we apply the Gaussian tail boundexp(− (tA/2)2 2σ2 L ), EL := min δ2U2 12 18432v4 2β2(n−2f)(d−1) 2 , δU12 768v4 2β2(n−2f) . Wr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.