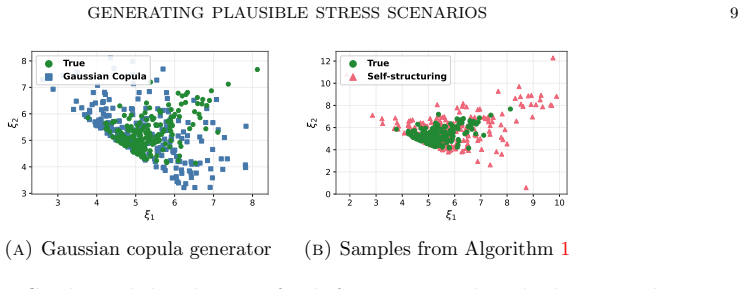
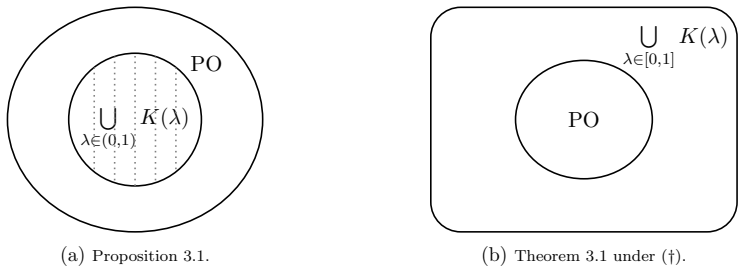
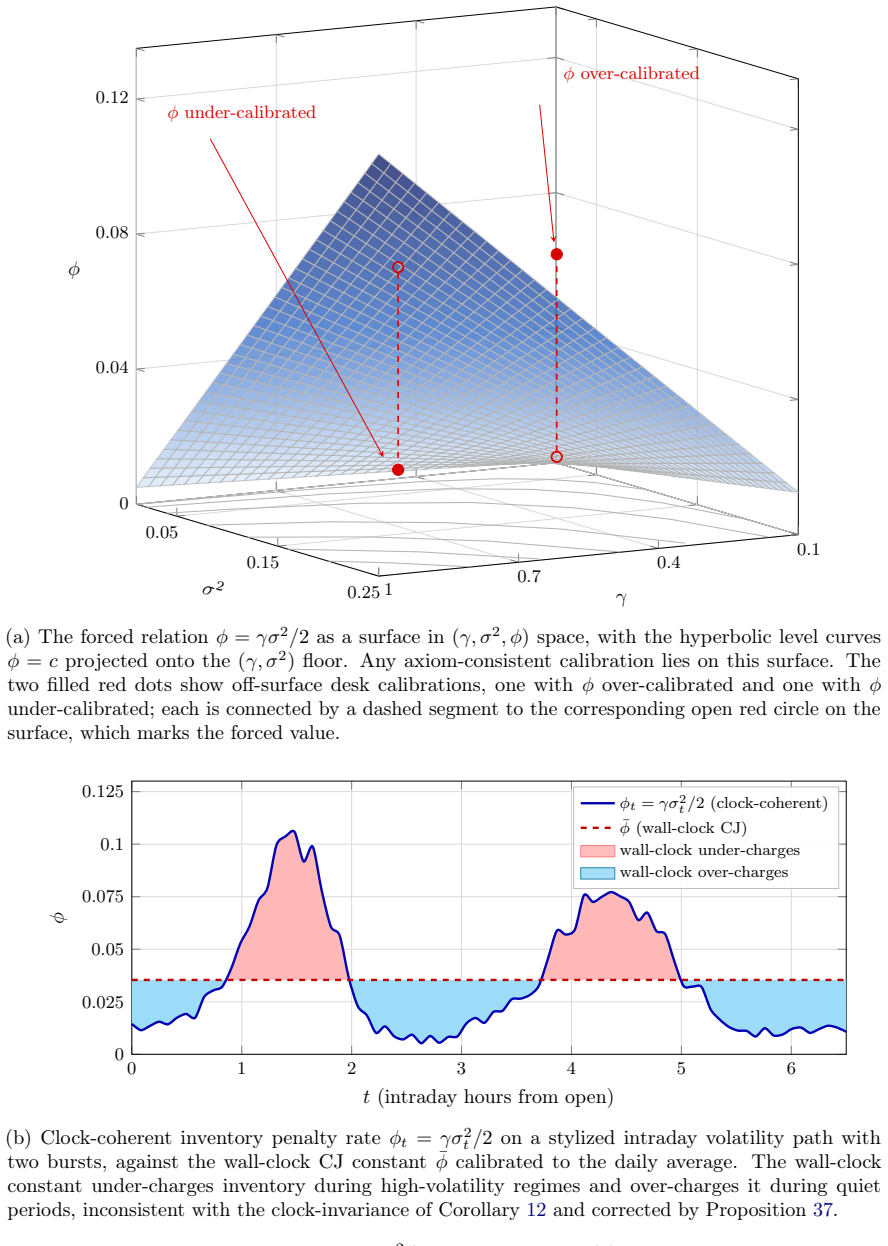
1
Risk drops by cutting exposure to top-risk scenarios via full matrix spectrum
New ordering of investment scenarios reduces out-of-sample return variability while keeping average returns and Sharpe ratios steady.
 full image
full image
abstract click to expand
In this research, starting from a widely accepted definition of risk, we support the idea that risk reduction is a more realistic objective than risk minimization, which represents a theoretical utopia. Furthermore, significant risk reduction can be achieved without relying on risk measurement and risk minimization. To this end, we propose a generalization of the numerical rank and the condition number of a matrix, specifically the return matrix in this application. This generalization considers the entire matrix spectrum instead of focusing only on the smallest eigenvalue, as the condition number does. The approach directly provides an order among a finite number of risky scenarios. Risk reduction is obtained by identifying the riskiest scenarios and reducing investment exposures corresponding to them. The validity of this theoretical proposal is supported by a comprehensive experiment performed on real data. The capacity of the proposed approach to effectively reduce risk is proven by measuring the variability of out-of-sample returns for benchmark portfolios-constructed by minimizing standard risk measures-compared to the strategy of reducing exposure in high-risk scenarios. Finally, preventing large losses with limited active management-thereby controlling the impact of transaction costs-not only reduces risk but also preserves the average return and, consequently, the portfolio's Sharpe ratio.