I propose a cap-axis integral diagnostic for factor-model evaluation. Low-dimensional factor models can improve the maximum-Sharpe frontier while leaving zero-alpha violations on economically fixed subspaces. The diagnostic studies one such subspace by lifting pricing errors into a bridge-alpha curve along the market-capitalization rank axis. Under an aggregate-market gate, a zero curve is equivalent to pricing the market's internal cap-rank subspace. In 1967-2024 CRSP data, q5's daily negative bridge attenuates under lead-lag correction, while Fama-French and Carhart bridges are more visible monthly. Across 154 factors, the cap-axis norm is distinct from Sharpe gain and size exposure.
In recent years, large language models have achieved remarkable success and have seen growing adoption in financial applications. At the same time, explainability remains critical in finance, a domain characterized by high stakes and strict regulatory requirements. Although numerous methods have been proposed to explain black box machine learning models, the majority of these approaches are designed for general purpose tasks and do not incorporate domain specific knowledge. In this work, we study the explainability of financial textual data modeled by large language models through the lens of the Shapley value. Specifically, we investigate whether Shapley based attributions align with established financial domain knowledge. Through rigorous theoretical analysis and extensive empirical evaluations, we demonstrate that Shapley values can yield explanations that are consistent with financial reasoning and can offer meaningful insights into the model's behavior in text based financial applications.
LLM agents are increasingly cast as autonomous portfolio managers, and benchmarks have moved from financial question-answering to sequential trading. Yet most still rank agents by returns over a fixed window -- a weak proxy, since a period's return is dominated by the market path and apparent alpha can dissolve once look-ahead leakage is controlled. Such a ranking certifies neither sound reasoning, nor a consistent strategy, nor a durable edge. We introduce CLQT, which reframes closed-loop trading evaluation as diagnosis rather than ranking: an instrument that localizes where and why an agent's process succeeds or fails. CLQT is a fully closed-loop, cost-aware, strategy-consistent, temporally-gated environment whose agents run a five-stage cycle: gather, synthesize, allocate, execute, reflect. Each round emits a complete DecisionRound sealed into a recompute-verifiable hash chain, so every metric is reconstructable from the trail. Six pillars form the substrate: a hard TimeGate, institutional transaction- and financing-cost modeling, strategy-consistency scoring, three-tier memory, a Model-Context-Protocol tool layer, and mandate-aware synthesis. The same agent runs as a constrained committee of specialized roles or a single full-autonomy orchestrator, making process scaffolding an experimental variable. From the audit trail we compute a five-axis capability scorecard (APM-CS: Coherence, Acuity, Composure, Discipline, Reliability), with Coherence judged partly by a held-out, out-of-cohort LLM to curb self-preference bias. We validate it on a contamination-controlled multi-model backtest with an ablation grid and a live broker track on unseen, post-cutoff data, against a repeated-run noise floor. CLQT separates outcome from capability, yielding not a model ranking but a durable, extensible map of agent competencies and limitations.
Financial decision-makers face more information than they can directly inspect, making context compression necessary. Yet when large language models (LLMs) compress financial source material, they can alter the investment judgment supported by the original source. We frame this problem as information fidelity: compression loses fidelity when it changes the decision induced by the source. In agentic systems, such losses may recur across intermediate steps and amplify throughout the decision process. Across financial filings and earnings-call transcripts, we find that LLM-based compression can produce fluent and factually plausible compressed contexts that nevertheless alter downstream decisions. We analyze two diagnostic patterns associated with fidelity loss: decontextualization, where salient evidence is retained but separated from the caveats and contextual qualifiers needed for correct interpretation, and model dependency, where different compressors expose different views of the same source. We then propose Agentic Context Compression, which generates multiple candidate compressions and audits their disagreements against the original source. Our results suggest that financial compression should be evaluated not only by efficiency or factuality, but also by its ability to preserve decision-relevant context.
Trade and price history recovers informed-trader versus market-maker distinction for linear strategies
abstractclick to expand
We show that net demand for liquidity by algo strategies is identifiable from its trade and price history alone, with no knowledge of its signal or optimization problem. An exact multi-period regret decomposition implies that the sign of this statistic classifies a linear strategy as a net liquidity consumer or provider, recovering the Kyle (1985) informed-trader/market-maker dichotomy from observables alone. Under an AR(1) cost process, the same statistic equals the product of strategy size and the squared Roll (1984) implied spread, making the correction a direct proxy for prevailing illiquidity. Extending to endogenous price impact and aggregating across N correlated strategies yields a liquidity-balance condition whose violation produces welfare loss scaling as N squared, a closed-form fire-sale externality. We calibrate to CRSP equity data (2016-2025), tracking implied spreads through the COVID-19 and 2022 rate-shock episodes, with an estimator computable in O(Tnd) time.
Spectral methods solve it in 1-2 seconds and reveal nonlinear variance dependence, outperforming finite differences by an order of magnitude
abstractclick to expand
A flexible forward (FF) is a customized FX hedging instrument that guarantees a fixed exchange rate while letting the holder choose the delivery date within a pre-agreed window. It is therefore an American-style option on timing, and its valuation must respect the volatility skew of the underlying currency pair. We price FF contracts (and, more generally, American options) under a time-inhomogeneous Heston model which captures the forward-skew term structure while preserving analytical tractability through a recursive (matrix) Riccati solution for the joint characteristic function. Extending the integral-equation (decomposition) approach to time-dependent coefficients, we derive a Volterra equation characterizing the early-exercise surface. The expectation in the decomposition formula is evaluated by two complementary spectral methods: a double cosine (COS) expansion of the transition density, and a damped-Sinc (DSINC) local-basis scheme that is more accurate and stays robust when a low Feller ratio or large vol-of-vol induces Gibbs oscillations in the COS series. Benchmarked against a penalty-iteration MCS-ADI finite-difference solver, both methods price a contract in about 1-2 seconds, roughly an order of magnitude faster than the finest finite-difference grid, while DSINC improves median accuracy over COS by about a factor of twelve. The experiments also show that the early-exercise surface is a substantially nonlinear function of the variance, contrary to the linear-in-variance approximation common in earlier work.
This paper compares different methods for forecasting the term structure of U.S. and European zero-coupon government bonds using both traditional econometric and Machine Learning (ML) approaches. We compare classical models (e.g., Dynamic Nelson-Siegel (DNS) and Principal Component Analysis (PCA)) with different Neural Network (NN) architectures, including those inspired by the classical models, on the U.S. Treasury market and bonds issued by the European Central Bank (ECB). To enhance predictive performance, macroeconomic variables are incorporated. The findings for both markets are separately analyzed and compared. To this end, we propose a robust model evaluation framework combining statistical accuracy metrics - such as RMSE, MAE, and directional accuracy - with the economic relevance of a quantitative bond trading strategy. Results show that NNs consistently outperform traditional models in both forecasting accuracy and portfolio performance. For the U.S., the most effective approach is a direct-forecasting NN that incorporates DNS factors to reduce the dimensionality of zero-rate data and an Autoencoder (AE) to extract macroeconomic features, while for Europe, the optimal model is a factor-based NN using PCA-derived zero-rate factors without the integration of macroeconomic variables. Overall, the paper demonstrates how combining traditional modeling approaches with modern ML techniques and evaluation can improve yield curve forecasts and support applications in fixed-income portfolio construction.
This paper develops a robust hedging valuation adjustment (HVA) measure for dynamic hedging. Simulated rebalancing and maturity-unwind trades generate a loss distribution for each no-trade-band rule, and we define robust HVA as the worst-case expected loss over a relative-entropy neighborhood of that distribution. Because band width affects turnover, the same relative-entropy radius applied to different bands can imply different levels of demand-liquidity stress. We distinguish a fixed-radius convention from a fixed benchmark-stress convention and show that wider no-trade bands lower rebalancing costs but raise hedge-error risk.
This paper proposes a two-stage decision support system for long-short portfolio optimization under environmental, social, and governance (ESG) considerations. In the first stage, assets are evaluated using a multi-criteria procedure based on TODIMSort, with criterion weights derived using the MEREC (Removal Effects of Criteria) method. This allows assets to be assigned to classes ordered according to preferences that respond to market conditions and investor priorities, thus generating sets of long and short opportunities that dynamically adapt to the prevailing regime. In the second stage, we formulate a non-convex portfolio optimization problem that maximizes the Omega ratio while respecting budget, bound and leverage constraints. To solve it, we introduce an adaptive particle swarm solver equipped with a controller that selects, at each iteration, the most suitable recombination operator from a diverse pool of operators and combines it with a projection-based repair mechanism for constraint management. The empirical study, conducted on 421 stocks in the STOXX Europe 600 index, examines both the exploration capabilities and solution quality of the proposed solver compared to state-of-the-art benchmarks, as well as the ex post profitability of the resulting portfolio strategies. The results show that ESG-enhanced long-short portfolios offer competitive and often superior performance compared to their non-ESG counterparts and the market-value-weighted benchmark.
This thesis studies the use of randomized neural networks for the estimation of exposure profiles and unilateral CVA of American options within a Monte Carlo framework. The analysis is carried out separately under both Black-Scholes and Heston dynamics, combining American option valuation, expected exposure and potential future exposure estimation, and unilateral CVA calculation with portfolio netting effects.
The numerical experiment compares this approach with the classical Least-Squares Monte Carlo (LSM) used as a benchmark in both low-dimensional single-asset and high-dimensional multi-asset scenarios, and also includes a path convergence test and a sensitivity analysis. The results show that the randomized feedforward neural network approach preserves convergence to the LSM benchmark when it is extended from pricing to exposure and CVA estimation, while its main advantage appears in high-dimensional problems, where it scales more efficiently and leads to lower computational cost.
These results support the use of randomized neural networks as a useful alternative for exposure and CVA estimation in high-dimensional American-style options.
The Fokker-Planck equation is fundamental to statistical mechanics, yet in settings with multiple state variables, anisotropic (cross-) diffusion, and jumps, conventional discretizations frequently produce non-physical negative probability densities. Building on the operator approach of "A. Itkin, Pricing derivatives under Levy models. Modern finite difference and pseudo-differential operators approach, Springer, 2017, ISBN 978-1-4939-6792-6", we introduce a family of "Diagonal Frog" discretizations whose spatial operators are eventually M-matrices (EM-matrices). Although these operators lack a local M-matrix structure, positivity of the directional sub-operators emerges in the spirit of Zeno's paradox: the matrix exponential, assembled as the limit of infinitely many ever-smaller substeps, is provably nonnegative after a short transient even though no single substep is. For the mixed-derivative block, whose generator is not eventually nonnegative, positivity instead rests on a factorized resolvent solver and holds conditionally, on an explicit step-size window; discrete mass is conserved exactly by the splitting for every step size. The resulting schemes are second-order accurate in time and space and require O(m 2 N + m 3) operations per time step, where m is the dimension of the Krylov subspace used to apply the exponential. As stress tests, we solve a two-dimensional anisotropic Fokker-Planck equation in the strong cross-diffusion regime against an exact Gaussian reference, a Kramers escape problem in a double-well potential, and an advection-dominated problem, and observe that the schemes remain stable, nonnegative, and mass-conservative for a wide range of P\'ecklet numbers (so, don't need any flux limiter). Finally, we extend the construction to multidimensional processes and to the backward Kolmogorov equation with jumps.
In this paper, we consider pricing a Bermudan swaption with a small number of exercise dates. We begin with the case of two exercise dates.
In this limit, we show that the Bermudan price decomposes into the sum of short-dated European swaptions, setting an upper bound, minus a correction term. This correction is expressed as an integral involving a forward volatility agreement type payoff with start at the first exercise date, and it can be evaluated in closed form. The magnitude of the correction is smaller when variance is front loaded and larger when it is back-loaded.
We extend to three-exercise Bermudans via backward induction under rolling forward measures. A key feature is boundary linearity enabling further analytic steps.
The exercise boundary of options splits into a strike-dependent term and a variance term; together they determine optimal exercise. The linear term is negative, supressing the exponentials in subsequent steps and aiding analytic calculations.
This boundary linearity extends to multiple exercise dates and yields pricing formulas with the same decomposition, showing how optionality accumulates across exercise dates.
We conclude that the Bermudan can be reconstructed by adding, at each exercise date, the initial short swaption with an increasingly higher strike and subtracting the integrated payoffs of all forward-starting receiver swaptions starting at that date. The corresponding double and higher-order integrals decrease rapidly and, in the presence of only a few exercise dates, can be safely neglected without materially impacting the valuation. The general case is discussed at the end.
Synthetic generators of daily equity returns let practitioners stress test, backtest, and design scenarios that a single realized market history cannot supply, but only if the generator reproduces the stylized facts of real returns: heavy tails, negligible linear autocorrelation, and slow decay of the absolute-return autocorrelation. Hidden Markov models with few Gaussian states were long thought unable to reproduce that slow decay, and the standard fix was to abandon them for more complex hidden semi-Markov models. We revisit this issue with a continuous hidden Markov model whose regime chain governs the autocorrelation while per-regime densities govern the marginal, separating the temporal and distributional sides of the original failure. A unified expectation-maximization framework fits Gaussian, Student-t, Laplace, and generalized-error emissions under shared forward-backward recursions and quantile-based initialization, and a spectral identity bounds the number of decay modes by the rank of the centred transition matrix. Across SPY walk-forward folds, a sector-balanced 30-ticker panel, a CRSP cross-decade transfer, and a six-asset basket, that bound was not binding once a few states were used: heavy-tailed marginals, not additional decay modes, closed most of the fit gap, recovering volatility clustering above the i.i.d. baseline and narrowing the kurtosis gap without a tuning hyperparameter. The original failure is therefore distributional, not temporal. On daily US equities, a simple, interpretable Markov model suffices, and unlike a bootstrap or semi-Markov fit that wins only on a single-window fit, the fitted model also yields a regime-conditional Value-at-Risk that passes a joint conditional-coverage test and a copula that reproduces cross-asset correlations: one interpretable generator serving both path simulation and downstream risk and portfolio tasks.
It meets a 25-minute deadline for a 10,000-instrument universe where the OSQP baseline completes only 4 of 500 accounts.
abstractclick to expand
Institutional rebalancing is a batched optimization workload with a hard operating deadline: hundreds of accounts need new weights under budget, turnover, exposure, exclusion, and tax-aware controls before trading can proceed. This paper evaluates Asymmetry PRISM, a CPU/GPU portfolio optimization engine, through a public evaluation boundary; problem data in, and returned weights, status codes, timings, memory class, external feasibility diagnostics, eligible objective comparisons, and audit records out. Within that boundary, the evaluation protocol fixes hardware and software versions, declares timing lanes, separates cold single calls from repeated workloads, and admits objective-gap claims only where an eligible reference solver completed. On completed multi-solver rows from N=100 to N=2,000, Asymmetry PRISM-CPU is 4.5x to 24.1x faster than the fastest completed reference row in the same lane. In the production queue study, Asymmetry PRISM-GPU completes 500/500 accounts over a 10,000-instrument universe in 109.5 s within a declared 25-minute operating window, with zero missed deadlines and an audit record for every solve; the recorded OSQP queue baseline completes 4/500. On an operationally constrained real-data suite (tax-motivated transition penalties, restriction caps, turnover controls, batches), Asymmetry PRISM clears constrained solves 3.4x to 126.7x faster than the best completing incumbent at certified-equal objectives, and the GPU route widens to 8.8x over the CPU route at N=384,800. Rows without a completed reference are reported as feasibility, timing, memory, and failure-status evidence.
Ethereum's beacon chain hosts over 920,000 active validators, a number inflated by the legacy 32 ETH stake cap. The Pectra upgrade (May 2025) addresses this by introducing 0x02 compounding validators, raising the maximum stake per validator from 32 to 2,048 ETH and enabling automatic reward reinvestment. This paper examines how compounding affects consensus-layer rewards, whether higher balances provide execution-layer advantages, and whether the APR uplift justifies migration for different staker types. We analyse adoption patterns across solo stakers and staking providers, investigate the role of consolidation (merging multiple 32 ETH validators into one) in early migration, and identify barriers slowing the transition. Through simulation, we find that compounding provides roughly +5% relative consensus-layer APR uplift for small balances, diminishing to under 1% for large staking providers. Empirical analysis of all active beacon chain validators shows 0x02 validators achieving modestly higher median CL APR. Solo stakers show higher relative adoption but face operational barriers, whilst providers cite infrastructure costs and protocol constraints. The results suggest that without improved reward accessibility and stronger economic incentives, 0x02 migration will remain gradual despite its network efficiency benefits.
This paper extends the approximate Bayesian estimation framework for Stochastic Volatility in Mean (SVM) models to accommodate heavy-tailed distributions from the Scale Mixture of Normals (SMN) family. To overcome the computational challenges arising from these models, we propose a numerically stable estimation procedure that exploits special functions to eliminate the need for direct numerical integration. Furthermore, the implementation incorporates parallel computing strategies that substantially reduce computational costs. Simulation studies and empirical applications demonstrate that the proposed approach delivers accurate inference while achieving computational times that are approximately an order of magnitude smaller than those required by conventional Markov chain Monte Carlo (MCMC) methods.
It stays accurate at high volatility and multi-year horizons, offering a faster alternative to full numerical schemes for XVA and CDS pricin
abstractclick to expand
Using the path-integral formalism, we develop an accurate and easy-to-compute semi-analytical approximation for a general class of {default intensity} models. We illustrate the accuracy of the method by presenting results for the Black-Karasinski model for which the proposed approximation provides remarkably accurate results, even in regimes of high volatility and multi-year time horizons. The accuracy and the computational efficiency of the proposed approximation makes it a viable alternative to fully numerical schemes for a variety of applications in econometrics and derivatives pricing, including the computation of XVA for credit products. As a practical example, we consider the pricing of a quanto Credit Default Swap (CDS) under stochastic intensity of default and an FX devaluation model.
The accurate calibration of interest rate models is central to market-consistent valuation and Economic Scenario Generators (ESGs). Traditional calibration methods for multi-factor models such as the G2++ model often rely on point estimates, neglecting the influence of specific market data and the quantification of estimation uncertainty. This paper develops a diagnostic framework embedding the calibration problem into non-linear regression theory. It shows that the common industry practice of minimizing the Root Mean Squared Relative Error (RMSRE) is equivalent to a Weighted Least Squares (WLS) problem. This equivalence yields the corresponding formulations for diagnostic tools, including the Weighted Hat Matrix for leverage analysis, Influence Functions for local sensitivity diagnostics, and the Functional Delta Method for local, boundary-respecting confidence intervals. The implementation uses an efficient Jacobian factorization that exploits the analytical tractability of At-The-Money (ATM) caps. The framework is applied to a dataset of Euro ATM caps covering the period 2016--2025. Our empirical analysis reveals a boundary-dominated leverage profile, repeated losses of effective dimensionality due to active parameter constraints, and a diagnostic regime shift in local parameter stability around the post-2022 market transition. The resulting message for actuarial model governance is that low RMSRE is not sufficient for calibration validation. We conclude by discussing the framework's applicability to general least-squares problems while highlighting the computational challenges for instruments lacking closed-form gradients, such as swaptions.
An integrated and extendable approach for stress-testing loan portfolios is presented, which includes both a loan production component and a credit risk component. In this approach, we simulate a completed portfolio using realistic loan parameters and distributional assumptions. Thereafter, we generate the uncertain cash flow history of these loans within a multistate probabilistic framework. We illustrate our approach using a simulation-based study, though the approach can be fit to real-world data. Such a simulation-based approach is ideal for stress-testing since it allows for evaluating a range of conditions. From these completed loans, we compute portfolio-level credit risk metrics, e.g., default and loss rates. Stress scenarios are introduced by varying the loan parameters accordingly within a broader Monte Carlo setup, thereby resulting in a range of portfolios. A classical approach to stress-testing does not typically integrate loan production or embed the correlation structure amongst risk metrics. In our approach, we integrate the forecasting of risk metrics with receipt-generation. Given data, the loan parameters within our extendable approach can be dynamically modelled as functions of input variables using any applicable technique. Overall, our approach can render predictions that are more dynamic and flexibly tuned, which can enhance stress-testing practices within any bank.
Simulation based solvers for optimal stopping problems must discretize the stopping decision. Under classical dynamic programming, a coarse exercise grid with only a few stopping opportunities can materially undervalue the optimal expected reward, whereas on a very fine grid, approximation errors accumulate through the backward recursion. To remove this limitation, we develop a new reinforcement-learning inspired algorithm that enables us to learn the exercise rule at arbitrarily fine time resolution. Our CARLOS (Continuous-time Adaptive Reinforcement Learning for Optimal Stopping) algorithm utilizes an aggregate deep neural network (ADNN) to learn a joint space-time decision boundary. Starting from a coarse time grid, we progressively increase the frequency of stopping opportunities, while in parallel training the ADNN to refine its timing-value estimates. We moreover design an adaptive sampling strategy that gradually concentrates training effort near the stopping boundary. Benchmarked results show that CARLOS delivers higher prices than existing Bermudan solvers, approaching the American upper bound, and achieves high computational efficiency relative to non-RL comparators.
We introduce Martingale Doppelg\"anger-Eval, a public shadow-market benchmark for auditing whether vision-language models (VLMs) use candlestick evidence rather than extrapolate past trends. The central difficulty is identification: on real market histories, chart evidence and trend are strongly coupled, so an observational score cannot determine whether a fluent technical-analysis narrative is grounded in local visual evidence. We prove this limitation formally: no evaluation functional computed from observational chart--label data can distinguish a grounded responder from a trend-shortcut responder under strong coupling, whereas matched evidence interventions separate the same responders at an exponential rate and trend--label swaps provide an independent shortcut stress test. The benchmark therefore evaluates frozen VLMs on rendered OHLCV charts under four controlled mechanisms: a martingale-null market, injected-alpha counterfactual pairs, trend-confounder swaps, and regime shifts. A structural behavioral model identifies null-market bias, trend sensitivity, evidence sensitivity, prompt/renderer fragility, and evidence faithfulness; the accompanying statistical toolkit provides minimum detectable effects, block-aware sequential testing for metered APIs, and an overlap-weighted artifact check. Across frozen commercial and open VLMs, the identified regression assigns large positive coefficients to past trend but evidence coefficients that are zero or opposite to the rule-implied sign. Matched-pair analyses show that models either ignore injected candlestick semantics or move opposite to the rule-implied direction conditional on responding. The benchmark isolates a failure mode that standard observational chart benchmarks cannot detect and gives a reusable audit template for time-series imagery with controllable label mechanisms.
Given risk-neutral densities of a tradeable forward, fitted as $N$-component mixtures at a finite set of expiration pillars, we look for a continuous-time interpolation that (i) stays inside the mixture family (it remains a mixture of the same kernel, though generically with more components than either pillar), and (ii) is the marginal flow of a Markov martingale, equivalently carries a non-negative Dupire local volatility. The second requirement is the peacock (convex-order) property. For full-support kernels (Gaussian, lognormal) a peacock corresponds to a unique continuous local-volatility diffusion (Lowther). We give a constructive interpolation that stays in a fixed $2N$-component family, note as an open question whether $N$ components suffice, and describe the main practical difficulty: in strongly bimodal regimes the local volatility stays finite but becomes badly conditioned.
In this paper, we develop a continuous-time model-free reinforcement learning algorithm to learn deterministic equilibrium policies in general time-inconsistent control problems. Utilizing the extended Hamilton-Jacobi-Bellman system, we recast the original time-inconsistent problem into an equivalent two-stage problem. In the first stage, for given auxiliary functions, we employ the deterministic policy gradient approach to learn an optimal policy in an auxiliary time-consistent control problem. In the second stage, given the updated policy, we exploit the inner fixed point iterations and some martingale characterizations to learn the auxiliary functions. As a theoretical contribution, we provide some mild model assumptions and establish the convergence of inner fixed point iterations. By repeating this actor-critic style of iterations across two stages, our algorithm aims to learn the equilibrium under different sources of time-inconsistency in a unified manner. The superior effectiveness of the proposed algorithm are illustrated in two classical financial applications with time-inconsistency: mean-variance portfolio management and optimal tracking portfolio under non-exponential discounting.
Recent advances in error-corrected qubits have accelerated the timeline for practical quantum computing. It poses a threat to cryptographic primitives used to secure financial systems, government infrastructure, communication networks, and DeFi (Decentralized Finance) ecosystems. This paper introduces a post-quantum secure federated DeFi framework that enables inter-bank collaboration to improve the inclusivity of individuals underserved by local lenders due to limited financial histories. Multiple banks contribute encrypted information batches to a virtual server, where lattice-based Fully Homomorphic Encryption (FHE) enables end-to-end homomorphic computation. The server fuses local data-driven probabilistic assessments, expert beliefs, and verifiable evidence generated by the NASA-IBM Prithvi Geospatial Foundation Model (GFM), in encrypted format. Decentralized technologies are employed to ensure tamper-proof evidence and auditable accountability for all encrypted data exchanges between institutions and the server. The framework is tested on agricultural lending decisions for rural borrowers in Virginia.
Regime-specific analytical guesses plus one Householder polish reach machine precision in under two steps on average.
abstractclick to expand
We present a regime-split Black--Scholes implied volatility solver in which every initial seed is a fully closed-form analytical expression, derived from the asymptotic structure of the Black--Scholes price in its natural domain. At the money, series reversion of an exact Gaussian identity yields a fourth-order seed with error $\mathcal{O}(s^8)$. In the moderate out-of-the-money region, successive Gaussian CDF approximations of increasing order produce explicit initial seed formulas whose accuracy is proved numerically, with no iteration or numerical inversion at the seed stage. In the deep out-of-the-money region, a Gaussian tail cancellation identity -- the Mills ratio -- reveals the asymptotic structure of the Black--Scholes price and motivates a ratio-corrected seed that achieves near-machine-precision initialisation for large moneyness. All regime boundaries are derived analytically from CDF truncation tolerances and numerical solver theoretical error bounds, with no empirically tuned constants. A universal fourth-order Householder polisher then drives all regimes to machine precision, with mean update iterations strictly below two on both standard and granular benchmark grids -- meeting and surpassing the two-iteration target established by the highest-accuracy reference implementation in the literature (J\"ackel, 2015). The resulting C implementation achieves a $1.73$--$1.85\times$ throughput gain over the state-of-the-art benchmark (J\"ackel, 2015) under identical hardware and compiler conditions, with maximum absolute error $\mathcal{O}(10^{-14})$, stable across grid configurations. A Python/Numba implementation confirms portability. All source code is publicly available.
This study investigates whether regime-dependent volatility forecasting and machine-learning-based return prediction can be jointly integrated to improve both statistical forecasting performance and economic strategy outcomes in equity markets. Using high-frequency CSI 300 Index data from 2005 to 2023, a sequential twostage framework is developed. In the first stage, realized volatility is modeled using regime-augmented HARQ specifications combined with Markov-switching GJR-GARCH filtering to capture long-memory dynamics, asymmetry, and structural market regimes. In the second stage, volatility forecasts, regime indicators, and return-related predictors are incorporated into an XGBoost return-prediction model estimated through a strictly walk-forward out-of-sample procedure. The empirical results demonstrate that regime-aware volatility forecasting consistently outperforms baseline HARQ models across forecast evaluation metrics and is generally supported by formal forecast comparison tests. In contrast, return predictability remains weak, state-dependent, and concentrated primarily in low-volatility regimes. Although naive predictive trading strategies generally fail after accounting for realistic transaction costs, carefully designed implementations incorporating volatility scaling, low-volatility gating, threshold calibration, and turnover controls can improve defensive economic performance. The findings suggest that the practical value of predictive systems in financial markets may depend less on generating strong unconditional return forecasts and more on transforming weak state-dependent signals into economically robust portfolio allocation rules. Overall, the study contributes by integrating econometric volatility modeling, regime classification, machine-learning return prediction, and implementation realism within a unified framework.
This study addresses the optimal execution of large stock sell programs by introducing TT-DAC-PS (Twin-Target Deterministic Actor-Critic with Policy Smoothing), a deterministic actor-critic architecture that combines twin exponential-moving-average critic targets with pessimistic min backup, TD3-style target policy smoothing noise, delayed actor updates, and conservative Q regularisation to curb overestimation. Exploration uses Ornstein-Uhlenbeck (OU) noise with a hybrid schedule: deterministic episode-wise decay, variance-guided adjustment based on recent reward dispersion, and a Soft Actor-Critic (SAC)-style temperature that is learned and mapped to the noise scale. The environment integrates Almgren-Chriss (AC) trade impact with Limit Order Book (LOB) prices and volumes, normalised state features, per-step volume participation caps, and a utility-based reward. The trade execution algorithm is applied to LOB data for ten U.S. stocks. Performance is assessed against reinforcement-learning baseline algorithms, including Proximal Policy Optimisation (PPO), Soft Actor-Critic (SAC), and Advantage Actor-Critic (A2C), as well as alternative trade execution algorithms, including Time-Weighted Average Price (TWAP), Volume-Weighted Average Price (VWAP), and AC. The proposed model consistently reduces mean implementation shortfall percentage with competitive variance, outperforming classical baselines and standard reinforcement-learning benchmark models.
Large language models (LLMs) and agentic systems are increasingly proposed for financial trading, yet their reported performance remains difficult to compare because studies vary in data provenance, temporal split discipline, execution timing, turnover treatment, and transaction-cost modeling. This article presents a targeted topical review and reproducibility audit of execution realism in LLM-based trading research. A coded evidence matrix covering 30 trade-relevant primary studies is used to assess point-in-time controls, split transparency, held-out evaluation, cost and turnover treatment, execution semantics, universe definition, and artifact release. Across the audited sample, architecture reporting is generally clearer than the evaluation assumptions needed to judge whether a trading result is economically interpretable or reproducible. A 10-equity worked example is included only as a methodological scaffold to illustrate how explicit friction and timing choices can materially compress active-strategy results. The main conclusion is that the next useful step for LLM trading research is not only better agent design, but also clearer reporting standards for execution realism, reproducibility, and evaluation comparability.
Rejection criteria net positive on 4874 observations but profits hinge on three trades
abstractclick to expand
This paper measures hour-of-day effects, filter precision, fragility, and realised yield in a 15-day paper-traded deployment of an autonomous memecoin trading system on Solana decentralised exchanges. The 190-trade sample (March 29 to April 12, 2026) shows a 40.5 percent win rate, mean per-trade return of +0.62 percent, cumulative +117.7 percent (net SOL +0.039), skewness -1.21, excess kurtosis 6.61. A Mann-Whitney U test of three poorest-performing UTC hours (2, 13, 23) against the others yields U = 1,274, p = 0.22; directional but not significant at n = 190. The three hours were selected in-sample, so the comparison is exploratory, not confirmatory. A parallel counterfactual rejection-tracking system collected 4,874 forward-sample observations across 184 distinct rejection events. Of those events, 17.9 percent reached a 50 percent drawdown from reference within 24 hours; 26.0 percent of forward samples recorded the rejected token below half-reference. The filter stack avoided these realised drawdowns: evidence that the rejection criteria are net-positive against forward-market outcomes. Fragility is the principal caveat. Removing the top three trades (1.6 percent of sample) flips cumulative return unprofitable. Profitability rests on a small number of large winners and is structurally fragile. The dataset and audit script are deposited under CC-BY-4.0 (Zenodo DOI 10.5281/zenodo.20043302).
Method records price and liquidity of filtered candidates to judge trading filters against observed results rather than backtests.
abstractclick to expand
Algorithmic trading systems on decentralised exchanges (DEXs) reject most candidate tokens they evaluate. The counterfactual outcome of rejected candidates (what would have happened had the system entered) is rarely measured. This paper introduces Post-Rejection Follow-up Sampling (PRFS). A separate tracking subsystem samples each rejected token's price and liquidity at a configurable cadence, over a horizon of up to twenty-four hours. PRFS produces the data needed to evaluate filter precision against actual market outcomes of rejected candidates, not against synthetic backtest reconstructions. The methodology, data architecture, and deposit format are described in Section III. The companion dataset contains 67,000 forward-outcome observation rows across 2,997 rejection events spanning 457 unique mints, collected over a continuous eight-day window (2026-04-10 to 2026-04-19, UTC). Approximately 55 percent of rejection events receive at least one forward observation; coverage at the mint level is complete. The principal binding constraint on downstream classification is per-event horizon density, not event-level coverage. PRFS is dataset-independent. It generalises to any algorithmic decision system in which rejections substantially outnumber executions.
Modern option-learning systems operate in two coordinates: price space, where markets quote and no-arbitrage constraints are most naturally enforced, and implied volatility (IV) space, where volatility surfaces are smoothed, regularized, and evaluated. The bottleneck is interface, not approximation: J\"ackel's seminal "Let's Be Rational" (LBR) solver already inverts the Black-Scholes price to machine precision efficiently. What is missing is a differentiable layer that preserves LBR in the forward pass and avoids backpropagating through its branch logic. Such a layer must also confront the unavoidable singularity of the inverse map in the low-vega regime, where the sensitivity 1/vega diverges as vega -> 0.
We close this gap with PIVOT, the Price-Implied-Volatility Objective Translator. PIVOT keeps the LBR forward pass intact and supplies the backward pass by implicit differentiation through the smooth Black-Scholes/Black-76 price map, with an explicit gating contract: invalid domains return NaN, well-conditioned rows receive the exact 1/vega gradient, and low-vega rows are attenuated rather than silently regularized. On a single H100, a fused Triton kernel reaches 1.79e9 IV/s at machine precision (9.3e-14 max relative error vs. the reference C solver); end-to-end label generation sustains 48.9M/s on synthetic chains and 16.6M/s on SPX OptionMetrics. In a HyperIV-style one-day reproduction on SPX, PIVOT-augmented objectives Pareto-dominate the baselines, reducing held-out price MAE by up to 43.4% and the strongest three-seed gated objective improving price MAE by 38.8% and IV MAE by 21.3% jointly; cross-asset results on RUT, VIX, and NDX show directional price-MAE gains of 40.1%, 24.2%, and 16.7%, while an ungated IV-roundtrip control collapses to a degenerate near-zero surface, confirming the gate as a correctness contract rather than a tuning knob.
Per-ticker forecasting models dominate financial time-series work yet remain blind to cross-company propagation: a foundry disruption in Taiwan does not register in a single-asset model until Apple's own price has already moved. To address this limitation, we introduce a heterogeneous Rust-Python streaming architecture that maps cross-company attention as a continuous-time graph driven directly from text. We show that on the ingestion side, a zero-copy Rust edge parses news records in $\sim$100 ns and scans the target equity universe in $\sim$1.2 $\mu$s. On the inference end, a multivariate Neural Hawkes Process featuring per-node continuous-time LSTM states and a bilinear latent projection propagates directed excitation, while an adaptive pruning rule bounds the computational cost of dynamic neighborhood updates. Combining these stages, we demonstrate an end-to-end processing latency of $\sim$13 ms per incoming news record on a single commodity CPU. Evaluated on a one-month temporal holdout of the FNSPID corpus (638 articles across 47 tickers), the system delivers a $1.70\times$ precision lift over random at the 90th-percentile next-day return threshold, and $3.36\times$ over a same-sector baseline. Crucially, removing the graph topology collapses precision to zero, confirming that the dynamic attention network is the sole driver of cross-company signal in this architecture.
We present a hybrid news sentiment engine that continuously learns market
sentiment from paired news headlines and concurrent asset-price snapshots
without requiring any neural network training or GPU compute. The system uses
a three-way ensemble combining (1) a financial-domain lexicon (FinBERT-style
keyword scoring), (2) an adaptive statistical TF-IDF cluster learner that
organizes headlines into semantic neighborhoods and tracks their average
realized price reactions, and (3) an auto-calibrating weighting mechanism
that adjusts ensemble contributions based on each signal's historical
correlation with actual price movements. The engine runs on a 3-hour polling
cycle from the Tradeflags NewsFeed API, which provides 22 price-snapshot
fields per news item spanning equity indices (ES, NQ, SPY, DJIA, NDX, IWM),
commodities (CL), and cryptocurrencies (BTC, ETH). All processing occurs at
sub-second latency on a CPU-only server at effectively zero marginal cost per
analytic cycle. We compare our approach against established methods --
FinBERT, GPT-based scoring, VADER, and commercial sentiment APIs -- across
dimensions of cost, latency, accuracy, and adaptability. Our statistical
cluster learner, which adapts to changing market regimes without retraining,
represents a novel contribution not found in existing sentiment systems.
Financial forecasting is difficult due to low signal-to-noise ratios, latent factors, heavy tails, regime shifts, and jumps. Real-world benchmarks offer limited failure attribution: researchers can observe underperformance, but often cannot isolate why because mechanisms are unobservable and entangled. Real financial data reveal only one realized path, making it difficult to assess tail-risk calibration or data efficiency. We introduce FinStressTS, a mechanism-aware synthetic benchmark that links model behavior to controlled structural causes. FinStressTS comprises 30 diagnostic environments around six mechanism families: volatility clustering, multi-scale persistence, heavy-tailed shocks, regime switching, self-exciting jumps, and zero-inflated processes. We evaluate two tasks: point forecasting, using NMAE across five settings, and probabilistic forecasting, using CRPS under known data-generating mechanisms. We benchmark 15 models, from classical methods (HAR, VAR) to Transformer forecasters (PatchTST, iTransformer) and deep probabilistic architectures (DeepAR, TSFlow), and use learning curves to measure sample efficiency. Our evaluation reveals three insights. First, performance is mechanism-dependent: autoregressive and linear models are highly competitive, and often outperform Transformer-based models, in several volatility-, tail-, and jump-driven environments. Second, distributional alignment matters: parametric probabilistic models such as DeepAR calibrate well in stationary settings, while flexible models can help when distributions become multimodal or sparse. Third, neural models often require more data to match simple baselines, with larger gains mainly when learning latent regimes or complex distributions. FinStressTS provides an open framework for diagnosing failure modes and advancing risk-aware forecasting.
We provide a brief primer for the idea behind formalising hierarchical causality in the context of complex systems. Here actors are not simply agents. Actors instantiate causation classes. Agents implement local dynamics in given levels or organisation in a given system. Hierarchical causality then describes how actor-level roles constrain, select, and organise agent-level behaviour across levels. The system then necessarily requires three additional structures. First, causation classes to abstract a given form of causal influence that an actor instantiates. Second, aggregation operators to move across the levels. Third, discrete event-time maps are required because the system comprises events, and the relation between local event counts and any global clock must be specified. Our formulation here is purposefully simple and discrete.
The standard generalization bounds assume that the training and deployment distributions are the same, or are static, and don't consider regime switching environments where the ratio of calm vs crisis states is different. This paper proposes a framework that generalizes regime-aware models by quantifying the extra risk due to regime composition mismatch, when distribution shifts are Markov-switching. We obtain an exact decomposition, separating regime mismatch from regime sensitivity; we extend the bound to beta-mixing data using the effective sample size corrected for the spectral gap; and we show a minimax lower bound for synthetic data and on 25 years of global equity indices. The proposed penalty is an ex post realized generalization gap, whereas the training-only estimator does not show significant correlation: the feature geometry of crises can be detected, but not the temporal arrival. Thus, the framework is not a forecast machine. Forecasting the composition of the future regime is an open question in the rare cases of regime change.
Over 200 theorems are machine-checked with explicit classification of how each matches classical statements and which axioms it uses.
abstractclick to expand
We describe a library of mathematical finance built in the Lean~4 proof assistant, on top of Mathlib and the \lean{BrownianMotion} package. It is broad: more than two hundred \lean{sorry}-free theorems across eleven areas, from the measure-theoretic foundations of continuous-time stochastic calculus through derivative pricing to applied risk, portfolio, and fixed-income theory, and, to our knowledge, the most comprehensive machine-checked development of mathematical finance to date. Two things make it more than a catalogue. It reaches into the continuous theory far enough to construct the $L^2$ It\^o integral as a bounded linear isometry and to \emph{derive}, rather than assume, the risk-neutral pricing measure. And it audits its own faithfulness: every result is classified by how its Lean statement relates to the mathematics it claims, and a build-enforced gate pins the axioms each proof actually uses, so a reader can see precisely what has been proved and what has only been proved under added hypotheses. We close with a finding: a formal base over classical financial mathematics yields certified \emph{unification} of known results rather than new financial theory. The contribution is therefore methodological and infrastructural (reusable verified foundations for mathematical finance, together with the faithfulness audit above), not a new financial result.
Real-world asset tokenization is often presented as a mechanism for improving the liquidity of traditionally illiquid assets. However, on-chain representation and secondary-market liquidity are distinct outcomes. This paper examines whether tokenized real-world assets exhibit meaningful observed liquidity and identifies the token characteristics associated with higher market activity. Using token-level data from RWA.xyz and supplemental contract-level observations from Etherscan, the study constructs an Ethereum-based monthly panel of non-stablecoin real-world assets across three prominent categories: U.S. Treasury-backed tokens, gold-backed commodity tokens, and private-credit-related tokens. Liquidity is measured using turnover, active addresses, and an active-month indicator. The empirical design combines descriptive statistics, non-parametric group tests, and exploratory panel regressions suited to short and sparse token histories. The results show substantial heterogeneity across asset categories. Gold-backed tokens exhibit broader holder bases and more persistent on-chain activity than many Treasury and private-credit-related products, while outstanding asset value alone does not reliably predict observed liquidity. The paper contributes to the literature by developing a clearer empirical measurement framework for real-world-asset liquidity and showing that tokenization and liquidity should be analyzed as distinct outcomes.
We propose a five-step diagnostic protocol for residual-trained neural HJB-PIDE solvers with control-dependent L\'evy jumps, targeting a general failure mode of neural PDE methods: a learned solution can match headline scalar diagnostics while miscomputing an operator inside its training loss. The protocol pairs each neural solve with at least one from-scratch independent reference, decomposes the Hamiltonian into drift, diffusion, compensator, and nonlocal-integral components across a u-grid, and compares the value function and its low-order derivatives over a (t,x) grid before any argmax comparison. Applied to a standard CRRA-Merton-Variance-Gamma benchmark, it isolates a missing 1/2-mixture factor in the neural method's importance-proposal density that scaled the nonlocal integral by exactly half - a textbook signature of a constant proposal scale error, invisible to longer training, grid refinement, and truncation sweeps. With the bug corrected, four references - two finite-difference solvers with disjoint discretizations, the neural solver, and a semi-analytic scalar baseline obtained from CRRA homogeneity - agree on the optimal control to within ~2%. The constant-coefficient CRRA benchmark collapses by homogeneity to a scalar maximization, so the scalar baseline is the efficient method here; the contribution is the protocol, applicable in principle to non-homogeneous and higher-dimensional settings where neural HJB-PIDE solvers are genuinely needed. The episode is a concrete instance of a broader neural-PDE verification failure: pointwise agreement of a learned value or control can coexist with a systematically wrong nonlocal operator, so per-component and surface-level checks are needed before trusting the argmax policy.
We study a forward-time formulation of the Black-Scholes equation with state-dependent volatility. In contrast to the classical terminal-value pricing problem, where the option payoff is prescribed at maturity and the price is computed backward in time, the present problem prescribes the current option-price profile and seeks to recover the option-price profile at the expiration date T. This formulation is ill-posed, since the equation evolves in the unstable direction of the parabolic operator and high-frequency perturbations in the initial data may be strongly amplified. To address this difficulty, we introduce a price-dimensional reduction based on shifted Legendre polynomials. The original Black-Scholes equation is projected onto a finite-dimensional Legendre basis in the asset-price variable, leading to a system of ordinary differential equations in time for the expansion coefficients. This reduction acts as a spectral cutoff and also relaxes the degeneracy caused by the factor S^2 at the zero-price boundary. The main reconstruction method is a dimension-reduced Legendre--Tikhonov method. We prove existence, uniqueness, data stability, and convergence for each fixed truncation level. We also include a reduced PINN solver as a secondary computational comparison after the Legendre reduction. Numerical experiments with smooth, butterfly-spread, and European put payoffs show that the Legendre--Tikhonov method recovers the terminal option-price profile from noisy initial data, while the reduced PINN solver provides a useful additional benchmark. Comparisons with the conventional physical-space quasi-reversibility method demonstrate the stabilizing effect of the Legendre reduction.
Deep learning models show promise in financial forecasting, yet their generalization is often undermined by small datasets, noisy signals, and non-stationarity. While meta-learning and related techniques mitigate some of these issues, they typically do not account for a core limitation in macro-financial prediction: the scarcity of distinct macroeconomic regimes that drive asset returns. We introduce HANET (Hierarchical Attention Network), a hybrid LSTM-based architecture that integrates macroeconomic domain knowledge through attention over long-run macro contexts while preserving high-frequency market dynamics. HANET organizes information in a hierarchical mixed-frequency structure, with daily asset-return signals nested within monthly macroeconomic windows, and introduces a Hierarchical Cross-Attention mechanism that reconciles low-frequency macro signals with high-frequency returns without discarding granular daily information. By framing regime selection as attention over macroeconomic contexts, the model adapts to scarce and shifting regimes. Empirically, across 55 liquid futures spanning multiple asset classes, HANET consistently outperforms neural forecasters that ignore macroeconomic information, particularly during turbulent periods, improving risk-adjusted returns and mitigating losses. Ablation studies show that these gains rely on structured macro conditioning rather than naive feature augmentation: an LSTM with the same macro representation performs poorly, and shuffling macro contexts substantially degrades performance. Finally, HANET provides interpretability through attention weights, highlighting which historical regimes are most influential for each forecast and linking macro conditions to portfolio outcomes. These results establish HANET as a systematic approach to integrating macroeconomic information into attention-based deep learning for financial forecasting.
Three-dimension scoring from turnover, holders, and activity shows high-value tokens can still be illiquid and concentrated.
abstractclick to expand
Tokenized real-world assets (RWAs) are often evaluated through headline indicators such as total value locked (TVL) or on-chain asset value. However, a large asset base does not necessarily imply low risk, since tokenized assets may remain illiquid, weakly traded, or highly concentrated among a small number of holders. Using public data from RWA.xyz, this paper develops an empirical and explainable risk scoring framework for tokenized RWA markets. The framework evaluates three dimensions of risk: liquidity risk $L$, concentration risk $C$, and market-quality risk $M$. These risk dimensions are constructed from observable indicators, including turnover, holder distribution, active-address activity, transfer frequency, and network concentration measured through Herfindahl indices. The analysis shows that several RWA tokens with substantial on-chain value exhibit high empirical risk because they combine limited transfer activity, low turnover, and concentrated ownership structures. In contrast, assets with broader participation and stronger on-chain activity display lower liquidity and concentration risk, even when their headline asset values are smaller. The findings demonstrate that TVL alone can obscure important risks in tokenized asset markets. By providing a transparent and data-driven risk scoring approach, this paper contributes to the empirical assessment of RWA liquidity and offers a practical basis for comparing tokenized assets beyond headline valuation metrics.
FlashIV is a low-latency Black--Scholes implied-volatility solver for production use. It normalises each input to an out-of-the-money price and solves a tail-stable erfcx/log-price residual. The hot path combines a cheap Li/asymptotic seed with a fixed, branch-light Householder refinement and guarded boundary handling. Across regular and stressed benchmarks, FlashIV stays close to the expanded J\"ackel reference price while running materially faster than a normalised Java port of J\"ackel's \emph{Let's Be Rational}. FlashIV+ adds an optional J\"ackel--Newton correction for applications that need tighter agreement with that reference price, trading latency for reference-price alignment.
Quantifying worst-case and best-case performance under complex market scenarios is a persistent challenge in financial risk management and the verification of path-dependent financial instruments, such as exotic options and structured products. Simulation-based methods are well suited for probabilistic estimation, but they do not directly provide exhaustive guarantees over all admissible scenarios or explicit witnesses for extremal outcomes.
To address this, we introduce a quantitative automata-based framework for the exact extremal analysis of financial systems under declarative scenario constraints. At the core of our approach are event history automata (EHAs), a new formal model that integrates regular-expression event patterns with admissible numerical intervals to represent constrained event histories with memory. Quantitative payoffs are represented by weighted finance finite automata (WFFAs), which allow transition weights to depend on observed market values. By computing the synchronized product of EHAs and WFFAs, our framework enables the exact calculation of upper and lower payoff bounds. Furthermore, the method automatically extracts interpretable witness event histories that realize these extremal outcomes.
We demonstrate the practical viability of the approach through a case study of an autocallable structured product with path-dependent mechanisms. The case study analyzes how different scenario constraints affect coupon accumulation, early redemption, and protection-loss outcomes. Scalability experiments indicate that the framework's execution remains computationally feasible for practical contract horizons and nontrivial constraint configurations. Overall, this approach provides a mathematically rigorous complement to standard financial simulation methods.
This study looks at the statistical properties and predictability using deep learning methods of the U.S. aggregate bond index in daily observations spanning 2018 to February 2026. We first establish that index levels are extremely persistent and consistent with unitroot behavior (Dickey and Fuller), while log returns are covariance-stationary with weak linear dependence and pronounced volatility clustering characteristic of ARCH-type processes (Engle; Bollerslev). Motivated by the trade-off between stationarity and information retention, we construct a "stationary but maximally persistent" representation via fractional differencing (Granger and Joyeux; Hosking) following the procedure of L\'opez de Prado, and evaluate shorthorizon forecast using two neural paradigms: (i) Multilayer Perceptrons (MLPs) trained on lagged vectors with joint lag-length and hyperparameter tuning (Hornik et al.; Rumelhart et al.); and (ii) Convolutional Neural Networks (CNNs) trained on Gramian Angular Field (GAF) image encodings (Wang and Oates). Empirically, MLPs match the strong naive persistence benchmark on levels, collapse toward near-zero forecasts on returns, and achieve the strongest incremental performance on the fractionally differenced series, where moderate dependence remains but unit-root drift is attenuated. In contrast, CNN-GAF models deliver consistently negative out-of-sample R 2 across all three representations. Overall, the results imply that, for short-horizon forecasting of broad bond indices, the primary determinant of predictive performance is the transformation of the series-its degree of stationarity and memory-rather than architectural complexity. Lag-based models remain competitive under persistence, while GAFbased CNNs are better suited to pattern-based tasks than to persistence-dominated next-step prediction.
Heston-Bates-CIR calibration to equity options and Euribor shows continuous volatility controls short horizons while stochastic rates affect
abstractclick to expand
This study develops an integrated stochastic modeling framework for pricing short and medium-maturity equity options and assessing interest-rate risk using the Heston (1993), Bates (1996), and CIR (1985) models. We calibrate the Heston model using both the Lewis (2001) Fourier inversion and the Carr-Madan (1999) FFT approach, finding near-identical parameter sets, which is consistent with the calibration stability reported in recent studies such as Agazzotti et al. (2025). Extending the model to Bates shows that jump intensities converge to values effectively equal to zero for 60-day maturities, echoing empirical findings that jumps contribute marginally to short-term smile fitting. We further compare our calibration approach with the joint volatility-surface and variance-term-structure framework proposed by Yoo (2025), confirming that standard Heston/Bates calibration remains robust for the maturities considered. Finally, we calibrate the CIR short-rate model to the Euribor term structure, generating positive and economically consistent forward-rate scenarios in line with recent stochastic-rate option-pricing research by Jeon and Kim (2025). Overall, our results show that continuous stochastic volatility dominates near-term pricing dynamics, while stochastic interest rates materially influence valuations beyond one year.
This study develops a regime-aware portfolio allocation framework that integrates Markov switching models with Reinforcement Learning (RL) to dynamically allocate across equities (SPY), long-term Treasuries (TLT), and gold (GLD). Using daily ETF data from 2004-2025, we first characterize market behavior through a discrete Markov chain and then estimate a three-state Gaussian Hidden Markov Model (HMM) selected by the Bayesian Information Criterion (BIC). The estimated regimes-low-volatility, transitional, and high-volatility-exhibit strong persistence and state-dependent return dynamics consistent with recent findings on nonlinear market states (Ardia et al., 2024; Gupta & Pierdzioch, 2023). State-conditional analysis shows that SPY dominates in stable regimes, while TLT and GLD provide protection during stressed periods, motivating regime-conditioned allocation rules.
We evaluate rule-based rotation and RL-driven strategies using a 30% out-of-sample test window with a one-day execution lag to avoid look-ahead bias. Both HMM-based allocations outperform a passive SPY benchmark, while the RL policy achieves the highest risk-adjusted performance, delivering the strongest Sharpe ratio and materially lower drawdowns, yet remains fully interpretable through discrete regime-dependent actions. Sensitivity analysis confirms the robustness of the three-state specification relative to two-state alternatives. Overall, the results demonstrate that RL can systematically enhance HMM-based regime detection, providing a transparent, adaptive, and empirically grounded framework for tactical asset allocation. The combined HMM-RL system provides a transparent, rules-based approach to tactical allocation that improves risk-adjusted performance relative to standard benchmark strategies.
Deep LSMC shows no accuracy loss when rates turn stochastic and needs no hand-crafted features, unlike polynomial regression.
abstractclick to expand
In general, the pricing of variable annuities with guarantees can be done by solving the corresponding optimal stochastic control problem if the contract withdrawal strategy is assumed to be optimal. This is typically solved as a dynamic programming problem using deterministic grid methods, which become computationally infeasible for more than a few state variables. In such situations, one needs to rely on simulation methods. The least-squares Monte Carlo (LSMC) method has become a popular simulation method for solving optimal stochastic control problems in quantitative finance over the last decades. In principle, the LSMC, originally developed for pricing Bermudan options, cannot be used directly for pricing variable annuities without simplifying assumptions because the underlying state variables are affected by the control decisions. This paper presents modifications of the LSMC algorithm that makes the pricing of general variable annuities feasible. For numerical illustrations, the pricing of variable annuities with guaranteed minimum withdrawal benefit under optimal withdrawal strategies is obtained with and without stochastic interest rates, using either polynomial regression or neural network regression in the LSMC algorithm. We found that the classical polynomial LSMC can give very accurate prices, at the cost of manual feature engineering, and with a standard deviation of the estimator that increases greatly when interest rates are made stochastic. By contrast, neural network LSMC gives slightly less accurate prices, requires more training time, but does not require manual feature engineering, and making interest rates stochastic makes no visible difference to its accuracy, suggesting a more stable and robust pricing performance of deep LSMC for higher-dimensional pricing problems.
Transition-related financial markets are increasingly exposed to abrupt repricing episodes, elevated volatility, and heterogeneous macro-financial shocks. Under such conditions, conventional Gaussian-linear forecasting frameworks may provide an incomplete representation of the dependence structure linking fossil-energy, renewable-energy, technology, and utility-sector assets. This paper investigates whether transition-related financial returns exhibit residual non-linear predictability after controlling for heavy-tailed multivariate linear dynamics. To address this question, we develop a hybrid forecasting framework combining Student-t Vector Autoregressions with nonlinear recurrent residual learning architectures. The empirical analysis considers six major exchange-traded funds representing broad equity markets and key transition-sensitive sectors. The results reveal substantial departures from Gaussian-linear behavior, including excess kurtosis, volatility clustering, and remaining nonlinear dependence after econometric filtering. Out-of-sample forecasting experiments show that the proposed framework consistently improves predictive accuracy relative to conventional VAR models, standalone machine-learning methods, and alternative hybrid specifications. The forecasting gains become more pronounced during periods of macro-financial stress, particularly during the COVID-19 crisis and the Ukraine-related energy shock. Overall, the findings suggest that transition-related financial systems exhibit regime-sensitive and heavy-tailed predictive dynamics that are insufficiently captured by standard Gaussian-linear models alone.
Multi-asset option pricing under local- and stochastic-volatility models leads naturally to high-dimensional parabolic PDEs. We develop an end-to-end quantum PDE framework for European option pricing under local-volatility Black--Scholes and Heston models. The framework takes classical contract and model data as input and returns classical estimates of selected option values. We solve the pricing PDEs after finite-difference discretization on spatial grids. For $N=2^n$ grid points per spatial direction and $d$ assets, the end-to-end gate complexity for single-point recovery, counted in elementary CNOT gates and one-qubit Pauli-axis rotations, has leading grid-size dependence $\widetilde{O}(d^2 N^{2+d/2})$ for local-volatility Black--Scholes and $\widetilde{O}(d^2 N^{d+2})$ for Heston. Relative to grid-based finite-difference baselines, these scalings correspond to polynomial improvement factors $N^{d/2}$ and $N^d$, respectively. These estimates translate to Clifford+T resources via standard compilation. We complement the complexity analysis with numerical benchmarks against standard classical methods. In the Heston setting, the framework recovers option prices across strikes together with the associated implied-volatility smile/skew. Overall, this work provides a complete end-to-end quantum pricing pipeline with explicit resource accounting and theoretical performance guarantees.
We study risk-neutral density extraction from short-dated option chains. As expiry approaches, option premia decline and bid--ask spreads can be large relative to prices, making mid quotes particularly uninformative. Stale or asynchronous quotes may also generate potential static arbitrages, rendering standard procedures infeasible or unstable. We develop a model-free pipeline that treats bid-ask quotes as the primitive market constraint. The pipeline consists of two steps. First, a procedure called ``Arbitrage Removal Iterative Executable Strategy'' (ARIES) filters executable static arbitrage at quoted bid and ask prices under market-depth constraints. Second, the ``Smooth Entropic Density EXtraction'' (SEDEx) then recovers the density through a criterion leveraging smoothness and entropy under bid-ask constraints. We test the pipeline on synthetic Heston panels and short-dated SPX option data, sampled from a few hours to one week before expiry. Computation is fast and returns robust densities across various market conditions, including scheduled macroeconomic announcements. As an empirical application, we use the recovered densities to construct short dated implied-volatility smiles.
We present ThiopheneIV, a Black-Scholes implied-volatility solver with a monotone core and explicit production guards. The solver starts from the simple Choi-Huh-Su L3 lower-bound seed and applies three Euler-Chebyshev steps on a lower branch and three Halley steps on the remaining upper branch. We prove that, in exact arithmetic, the seed lies below the root and both maps increase monotonically without overshooting. We also detail the practical challenges encountered for a double-precision implementation: parity normalisation, microscopic Bachelier-limit handling, saturated price treatment, and an optional J\"ackel-Newton polish. Across standard grids, market-like data, high-volatility cases, and adversarial corners, ThiopheneIV agrees closely with multiprecision Black reference prices at low latency.
We provide detailed comparisons with recent solvers, including J\"ackel's Let's Be Rational. The broader lesson is that a convergence proof gives a clean core, but robust production inversion still depends on boundary handling and on the pricing objective one chooses to match.
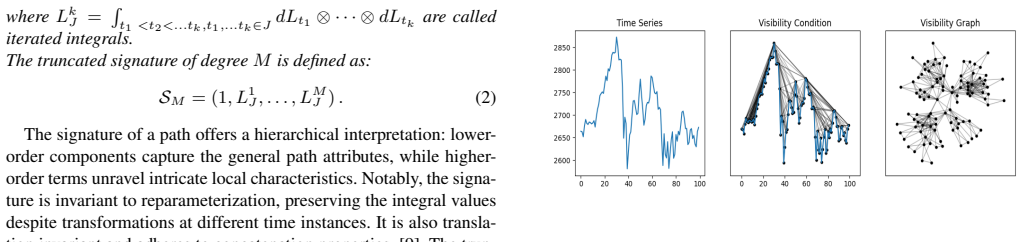
Generating synthetic data for financial time series poses challenges, especially considering their non-stationary nature. Traditional statistical time series models normally assume weak stationarity. However, this assumption can constrain their effectiveness. Deep learning models, particularly Generative Adversarial Networks (GANs), have exhibited considerable potential in emulating complex probability distributions. GANs employ a generator-discriminator framework, where the generator creates data samples, while the discriminator distinguishes real from generated data. In this research, we introduce the Sig-Graph GAN model, which integrates the time-series signature, offering a structured summary of its temporal evolution; the Long Short-Term Memory network, capturing its inherent autoregressive structure; and Graph Neural Networks (GNNs), leveraging geometric patterns within the time-series data. To employ GNNs optimally, we use the visibility graph algorithm to derive a graph-based representation of the underlying time series. Numerical evaluations demonstrate that the Sig-Graph GAN model outperforms baseline methods in replicating the distribution of logarithmic returns across different stock exchanges. The integration of the graph structure with the autoregressive component effectively captures both geometric and temporal patterns embedded in time-series data. This research advances the field of GAN models for time series by introducing a model capable of leveraging both autoregressive properties and geometric structures for synthetic data generation.
This paper studies empirical deep hedging for S&P 500 index options under a local downside-shortfall reward. It moves beyond performance comparison by asking what the learned hedge does, when it fails, and whether it can be made auditable. TD3 agents are compared with a daily-updated Black-Scholes delta hedge on the same option episodes. In walk-forward tests from 2015 to 2023, the agents usually learn a systematic delta haircut relative to Black-Scholes. The correction is explained by spot-implied-volatility co-movement and often improves accumulated reward and terminal downside variance, but it is regime-fragile: 2022 exposes losses in adverse daily states, while 2023 shows that underhedging can raise ordinary variance when option P&L is spot-dominated and the volatility channel is unusually weak. Symbolic regression distills the neural policies into compact formulas that can be traded out of sample; these formulas preserve much of the reward, downside-variance, and CVaR advantage over Black-Scholes, and sometimes sharpen it, but inherit the same fragility in difficult regimes.
We study the reconstruction of implied volatility surfaces from sparse and noisy option quotes using deep learning models under no-arbitrage constraints. We compare multiple neural architectures, including multilayer perceptrons, convolutional networks, U-Nets, variational autoencoders, and Transformer-based models against classical SVI parameterizations on option market data. Results show that Transformer and U-Net architectures achieve strong reconstruction accuracy, particularly under sparse observation regimes, while soft arbitrage penalties significantly reduce arbitrage violations with moderate impact on reconstruction error. We further analyze the trade-off between accuracy and arbitrage consistency across architectures and regularization strengths.
Institutional crossing platforms face a hidden-information problem: investors value trades as portfolios, but liquidity discovery is typically organized around individual securities. We model portfolio crossing as limited-communication preference elicitation over signed portfolio trades. The platform first uses price-directed demand queries to search the portfolio space and then verifies selected packages through value queries; an incumbent verification query records the demand-discovered allocation before further exploration. Final allocations are chosen from elicited reports, so the learning model guides queries but does not determine welfare. The analysis shows why search and verification are complementary. Demand queries locate high-value regions of a nonseparable portfolio space, but they provide only conservative welfare evidence unless selected packages are verified. Value queries provide exact welfare comparisons, but they are ineffective when applied to poorly targeted packages. Market-calibrated experiments using equity panels from the United States, Korea, Japan, and Germany show that demand-only and value-only designs recover only about half of full-information welfare under a limited query budget, whereas the hybrid procedure recovers 88\% and approaches 95\% as communication expands. We then compare exact security-level packages with factor-completed basket packages within the same allocation rule. Security-level packages are the unadjusted-efficiency mode when exact-securities disclosure is inexpensive. Factor-completed baskets become preferable when pretrade message informativeness is costly. The results characterize portfolio crossing as a selective verification problem and identify disclosure-sensitive package representation as a core design choice for hidden liquidity platforms.
Forecasting univariate time series in the financial market is a challenging endeavor. While numerous statistical and machine learning models have been introduced to address this challenge, they typically concentrate solely on analyzing temporal patterns within the time series data. In this research, we study the statistical significance of the inclusion of geometric patterns in enhancing forecasting accuracy within the context of time series analysis. We introduce the Time-Geometric model, a combination of models designed to exploit both geometric and temporal patterns. The contribution of this research lies in advancing the domain of univariate time series prediction,as demonstrated through extensive empirical evaluations. Our findings underscore that leveraging geometric patterns, captured through Graph Neural Networks, yields statistically significant improvements in forecasting accuracy.
In this paper, we investigate whether deep reinforcement-learning agents interacting in a shared optimal-execution environment can sustain supra-competitive outcomes, in the sense of achieving lower implementation shortfalls than the relevant game-theoretical competitive benchmark. We study a two-agent Almgren-Chriss liquidation game and examine how learned behavior depends on intra-episode environment feedback, the ability to interpret the mid-price and the agent's knoledge of the past. We first use ex-ante schedule-learning agents to remove intra-episode feedback and isolate what can arise when agents commit to complete liquidation trajectories before execution begins. We then allow agents to condition on the evolving state using a variety of DDQN architectures. We find that, when agents are given access to intra-episode history, especially recent prices and own past actions, supra-competitive outcomes become substantially more frequent and more persistent. These findings indicate that supra-competitive behavior in this execution game is driven not by multi-agent learning or by current price observation alone, but by feedback, memory, and state-contingent interaction along the realized execution path.
We present two explicit rational formulae for Bachelier, or normal, implied volatility. The formulae take the option price, forward, strike, and expiry as inputs and return the implied normal volatility without iteration. They follow the branch structure of LFK-4, but use the simpler near-the-money variable given by the absolute forward-strike difference divided by the tail time value, avoiding a logarithm and a small-argument Taylor branch in that region. LFK-2026 is the accuracy-oriented formula and approximates reciprocal absolute standardized moneyness directly in the far tail. LFK-2026C keeps the same shifted out-of-the-money rational tail approximation, but splits the near-the-money branch two low degree rationals. In double precision tests both remain close to machine accuracy, while LFK-2026C is the faster scalar implementation on the current benchmark mix.
We propose a data-driven Fourier-trained neural-network method for estimating fixed-horizon probability densities from empirical characteristic-function (CF) information. The estimator is a positive Gaussian--Laplace mixture with closed-form CF, so training can be performed directly in Fourier space while preserving nonnegativity and unit mass. We consider two sampling settings. In the direct i.i.d. sampling setting, the method is trained against an empirical CF constructed from i.i.d. samples. In the resampling-based pseudo-sampling setting, it is trained against an empirical pseudo-CF constructed from dependent data by resampling. For the direct i.i.d. case, we derive an expected $L_2$ error bound that separates Fourier truncation, empirical training error, discretization, and CF sampling error. For the pseudo-sampling case, we obtain a conditional analogue with two additional pseudo-law discrepancy terms. We develop a multidimensional extension of the framework and analyze its computational complexity. Numerical experiments show competitive performance relative to Expectation--Maximization on Gaussian-mixture benchmarks, clear gains on heavy-tailed targets, $L_2$ error decay consistent with the theory in a well-specified setting, and effective estimation of one-year Australian equity return law from resampled dependent data.
Walk-forward tests on MNQ five-minute data show accuracies stuck at the 51.8 percent base rate.
abstractclick to expand
This paper compares gradient boosting and long short-term memory (LSTM) architectures for intraday directional prediction in Micro E-Mini Nasdaq 100 futures (MNQ). Motivated by recent foundation-model research on financial candlestick data, including the Kronos architecture, we test whether five-minute OHLCV bar sequences contain exploitable sequential predictive structure at the scale of a single instrument dataset. Using 944 trading days from 2021-2025, four model configurations are evaluated under strict expanding-window walk-forward validation across three out-of-sample periods. The target variable is whether the session close exceeds the 10:30 AM open by more than ten points. No configuration produces statistically significant out-of-sample accuracy above the 51.8% base rate. Combined OOS accuracies range from 50.00% to 50.89% across gradient boosting variants, while the LSTM achieves 50.59%. Permutation tests yield p-values of 0.135 for the best gradient boosting model and 0.515 for the LSTM, indicating no statistically significant predictive edge. Feature importance instability across walk-forward folds suggests noise fitting rather than stable structural signal capture. The results indicate that four years of single-instrument five-minute OHLCV data are insufficient for reliable sequential ML-based intraday forecasting. The primary contribution is a documented evaluation of a Kronos-inspired architecture on a constrained real-world dataset, providing an empirical lower bound on data scale requirements for sequential financial ML.
Regime shifts in financial markets reorganise the joint dynamics of asset prices and macro variables, breaking any single-regime calibration. They are nonetheless difficult to detect reliably because the data signal is noisy and heavily multicollinear, while the contemporaneous text that announces them is unstructured. Standard regime shift detection methods rely solely on structured time-series data and ignore policy communications, even though these texts often signal shifts before they materialise in observed prices. We propose a text-enhanced regime shift detection pipeline that combines large language model (LLM) reasoning over central-bank communications with statistical validation on multivariate financial time series. The framework is detector-agnostic: text-proposed candidates are validated using a bootstrap likelihood-ratio test on a vector autoregression (VAR), while data-driven candidates from arbitrary regime detectors are ratified through a lenient LLM text check. We evaluate the framework on 2010-2024 FOMC minutes paired with a 14-variable U.S. Treasury and macroeconomic panel, using four interchangeable data-driven detectors. The proposed pipeline achieves F1 = 0.82 against a verified anchor list of monetary-policy regime shifts, with same-day modal detection latency and consistently stronger performance than pure data-driven baselines. The results demonstrate that combining unstructured policy text with statistical structural-break detection improves the robustness and interpretability of regime shift identification in financial markets.
We study behavioral alignment and representation dynamics of large language model (LLM) agents in financial decision environments. TradeArena, an auditable trading-agent testbed with risk reports, execution simulation, memory, and replayable trajectories, lets us analyze how rationales, positions, and interventions evolve under market stress. Code and data artifacts are available through the \href{https://github.com/weich97/TradeArena.git}{TradeArena repository}. We find pre-failure signatures: planning embeddings drift from normal centroids, fused plan-risk representations separate normal from pre-drawdown states, and local manifolds exhibit effective-rank contraction. Across 80 rolling failure anchors and eight LLM trajectories, this pattern persists across hash, LSA, Transformer, and white-box hidden-state probes. Stress tests with CoT-free target weights, lexical controls, OHLCV noise, and false audits show that rationale-level contraction can vanish without rationales, while intent-space and fused signatures remain informative. Structured risk feedback can act as an external alignment signal without fine-tuning, but not as a universal performance enhancer: true audit feedback improves calibration for some models, returns for others, and exposes cases where placebo or hidden feedback has higher short-horizon return but weaker alignment diagnostics. A 51-stock intraday experiment reveals a correlation blind spot: LLM rationales justify exposure to coupled assets that the risk layer clips. Finally, a financial-audit task suite shifts comparison from ``which model trades best'' to whether models can audit trajectories, respect execution boundaries, reproduce artifacts, and avoid claim overreach. These results support a research claim, not a profitability claim: auditable risk feedback and representation trajectories reveal when LLM financial reasoning is aligning, drifting, or failing.
Monte-Carlo pathwise sensitivities convert to market hedge ratios using a basis much smaller than the path count, solved by residual minimiz
abstractclick to expand
Monte-Carlo valuation engines can generate pathwise sensitivities of a derivative value with respect to a high-dimensional vector of model primitives. Hedge ratios with respect to market instruments are then linked to these primitive sensitivities by a pathwise linear relation. Solving this relation independently on every simulated path may be expensive, unstable, and unnecessarily high-dimensional.
This paper studies reduced stochastic hedge ratios of the form $\phi_j^r=\sum_{q=1}^r\xi_j^qX_q$, where the number of solution basis functions is much smaller than the number of Monte-Carlo paths. The hedge-instrument sensitivity tensor is not replaced by its own basis expansion; it is retained through empirical averages over the simulated paths. The basis ansatz alone does not determine the coefficients, so two coefficient criteria are distinguished. The first minimizes the full empirical pathwise residual $\sum_\ell\|A_\ell\phi_\ell^r-b_\ell\|_2^2$. The second is a projected moment equation requiring $\langle A\phi^r-b,Y_s\rangle_N=0$ for selected test functions. The special case $Y_s=X_s$ is the usual Galerkin choice; different test functions give a Petrov--Galerkin formulation. The criteria coincide in special cases but differ when the hedge-instrument sensitivities are path-dependent. The paper gives the tensor and matrix forms of both reductions, discusses regularization and conditioning, and records implementation considerations.
The constructions are motivated by sensitivity-based margin valuation adjustment and replication-consistent liquidity forecasting, where pathwise primitive sensitivities have to be converted into hedge ratios with respect to market instruments.
Generating realistic synthetic option prices requires implied volatility as an input, yet implied volatility is itself derived from observed option prices, creating a circular dependency that limits synthetic data for machine-learning and risk-analysis applications. We break this circularity with a pipeline in which implied volatility emerges as an output of a structural model of equity returns. A Jump Hidden Markov Model produces multi-asset price paths with realistic stylized facts and cross-asset tail dependence; a modified Heston variance process, whose mean-reversion target depends on regime state, days to expiration, moneyness, and a market-mood indicator, converts those paths into implied-volatility paths; and a recombining binomial lattice prices American options from the resulting surface. Initializing variance at its mean-reversion target for each strike-expiration pair lets smile, skew, and term structure emerge without external calibration. We calibrate the shape function through a hierarchy spanning a parametric baseline, a globally shared neural surrogate, and a sector-specific neural surrogate fit to a multi-ticker, multi-sector option ladder. A temporal holdout on a multi-day capture isolated scheduled corporate events as the dominant source of test-time generalization error, and calendar-derived earnings-distance and same-sector peer-coupling features recovered the anticipatory portion of that signal. We then apply the framework as a synthetic-data generator on real near-the-money put and call contracts, forward-simulating price paths, and recovering path-conditional implied volatility, finite-difference American Greeks, and terminal short-premium profit and loss from one coherent simulation, and confirm cross-ticker robustness by re-running on a second underlying from a different sector and volatility regime. The framework is released as an open-source Julia package.
This paper develops a deep learning-based framework for pricing convertible bonds with path-dependent contractual features, namely downward conversion price reset and issuer call clauses under rolling-window trigger rules, which are widespread in the convertible bond market. We formulate the valuation problem as a path-dependent partial differential equation (PPDE), which explicitly captures the dependence of the convertible bond value on the historical path of the underlying asset and the dynamic evolution of the conversion price. We derive consistent PPDE formulations for three canonical underlying dynamics: geometric Brownian motion (GBM), constant elasticity of variance (CEV) and Heston stochastic volatility. We then construct a discrete-time dynamic programming scheme in which conditional expectations are approximated by neural networks, which remains tractable in such high-dimensional path-dependent setting. Empirical tests on China CITIC Bank Convertible Bond show that our framework produces stable and accurate prices and sensitivity patterns across all model specifications. Three key economic insights emerge: 1. Contractual features dominate underlying dynamics in determining convertible bond values. 2. The call provision decreases convertible bonds prices by truncating upside gains. 3. Counterintuitively, despite improving conversion terms, the downward reset provision further decreases the price of convertible bonds by lowering the effective call threshold and making early redemption more likely. The proposed PPDE-deep learning approach provides an efficient, flexible tool for pricing convertible bonds with complex path-dependent structures.
RED-2400 is a public benchmark of 6,660 algorithmically-rejected trading events from a live Solana decentralised-exchange filter stack, observed continuously over 22 calendar days (2026-04-10T21:10Z through 2026-05-02T21:48Z, UTC). Each rejection event is linked to its post-rejection price-and-liquidity trajectory. The deposit contains 169,123 forward-outcome observations and 1,837 graveyard-tracker lifecycle snapshots, covering 1,076 distinct mints in the rejection registry and 1,075 in the forward-observation file. Outcome labels follow the five-tier classification rule introduced by a related methodology paper [Kamat 2026c]. The deposit includes a lifecycle-tracker file that permits external validation of any subset of those labels against observed token-lifecycle ground truth. Filter labels are anonymised to filter_1 through filter_8; source-collector identifiers to source_a and source_b. Liquidity and 24-hour volume are quantised to the nearest power of two, preserving heavy-tailed shape while preventing operational-threshold inference. This is the first window of a planned series; subsequent windows will extend the time horizon and enable regime-stratified analysis. "RED-2400" is a brand name, not a count; current cohort sizes are listed below and do not equal 2,400.
Prediction markets cannot exist without market makers, arbitrageurs, and other non-retail liquidity providers, yet the supply-side microstructure of Polymarket-class venues has not been characterized at on-chain pseudonymous-address scale. This paper studies non-retail participation on Polymarket using an empirical run on the PMXT v2 archive over 2026-04-21 through 2026-04-27 (13,356,931 OrderFilled events; 77,204 addresses with five+ fills; 43,116 markets).
We report three findings. First, Polymarket's off-chain CLOB architecture renders address-level quote-lifecycle attribution permanently unavailable: OrderPlaced and OrderCancelled events are off-chain and absent from public archives, so quote-intensity, two-sided-ratio, and posted-spread features cannot be built at address level. We document this as a structural validity-gate failure (G-QUOTE-LIFE universal fail) and restrict analysis to a six-feature fill-side vector. Second, density-based clustering (DBSCAN, fifteen sensitivity configurations) on the fill-side vector produces a single dense cluster with zero noise: fill-side behavior in the empirical window is uni-modal under the six-feature vector, contradicting the pre-registered hypothesis of four-to-five separable archetypes. Third, robust retail vs non-retail separation is achievable through clustering-independent feature-tier stratification: whale-tier, high-frequency-operator, and power-trader tiers jointly hold 81.4% of total notional across 12.6% of addresses.
Address-level market-making and liquidity-provision claims are withdrawn per the G-QUOTE-LIFE failure; spoof-by-non-fill manipulation detection is downgraded to market-level book diagnostics. A privacy-respecting derived-dataset deposit accompanies the paper as Bundle 3 of the PMXT family. Fourth paper in a four-paper programme on event-linked perpetuals and leveraged prediction-market microstructure.
Pre-market conditions mark mornings with drift and afternoons with reversal, yet every tested rule fails after transaction costs and year-by
abstractclick to expand
This paper constructs and validates a composite day-classification system for Micro E-Mini Nasdaq 100 futures (MNQ) using three pre-market observable conditions: first-30-minute return magnitude, overnight gap magnitude, and abnormal opening-bar volume relative to a rolling baseline. Using 947 regular trading days of five-minute data from 2021-2025, we find that classifier-positive days exhibit statistically distinct intraday behavior, including directional morning drift followed by systematic late-session reversal. Despite these descriptive characteristics, all tested directional trading strategies fail institutional validation standards after transaction costs and multi-year consistency requirements are applied. The highest-performing configuration achieves T = 1.46 and mean net +7.80 points but fails year-stability criteria. The primary contribution is the validation of the Volatility-Volume-Gap (VVG) classifier as a descriptive regime-identification framework and the documentation of failed attempts to convert these statistical patterns into deployable trading signals under realistic execution constraints.
Deploying machine learning in regulated financial environments -- credit risk, fraud detection, and anti-money laundering -- exposes critical vulnerabilities in algorithmic reproducibility. While early financial ML addressed statistical challenges such as backtest overfitting, deep neural networks and Generative AI have introduced mechanical nondeterminism rooted in hardware and architecture. This survey provides a systems perspective on reproducibility failures across three modalities now dominant in financial AI: tabular models (post-hoc explanation variance), graph networks (stochastic sampling and temporal asynchrony), and LLM-based agentic workflows (batch-dependent divergence and trajectory drift). We supplement the literature analysis with first-party experiments on public financial datasets -- quantifying explanation rank instability in credit scoring, prediction flip rates in GNN-based fraud detection, and tensor-parallel-induced output divergence in LLM entity extraction. We propose a layered evaluation framework linking modality-specific metrics (RBO, D_cos, TDI, PSD) to audit readiness, and empirically validate the complementarity of logit-level and semantic-level determinism measures.
Accurate and efficient imbalance electricity price forecasting is critical for industrial energy trading systems, especially as battery assets and automated bidding pipelines increasingly participate in balancing markets. However, real-time forecasting is complicated by nonlinear market-rule-based price formation, heterogeneous input signals, and incomplete data availability caused by communication delays, publication lags, and measurement outages. This paper proposes a market-rule-informed neural forecasting framework that embeds imbalance price formation rules into the latent space of an expressive neural network. The proposed framework preserves raw signal information while exploiting transparent market-rule priors. We further analyze operational robustness by removing price-component information and characterize how forecasting performance scales with input length and forecasting horizon. Experimental results show that the proposed model achieves competitive forecasting performance with substantially fewer trainable parameters and shorter training time than generic deep learning baselines. Experimental results show that the proposed model achieves competitive forecasting performance with substantially fewer trainable parameters and shorter training time than generic deep learning baselines, demonstrating that market-rule priors and expressive neural networks should be jointly used for accurate and computationally sustainable forecasting in industrial energy trading applications. The implementation is publicly available at https://runyao-yu.github.io/MRINN/.
This paper proposes a hybrid methodology to improve the approximation of SABR (Stochastic Alpha Beta Rho) implied volatility by combining analytical structure with machine learning. The approach augments the neural-network input representation with geometric features derived from the stochastic differential equations of the SABR model. Unlike approaches that fully replace analytical formulas with black-box models, the proposed framework preserves the analytical backbone of the model. The hybridization operates along two complementary dimensions. First, geometry-aware variables reflecting intrinsic properties of the SABR dynamics are used as structured inputs to the network. Second, the neural network is trained to learn the residual error relative to Hagan's closed-form approximation rather than implied volatility directly. The resulting model acts as a structured residual correction to the analytical formula, retaining interpretability while capturing higher-order effects that are not included in the asymptotic expansion. Numerical experiments conducted over realistic parameter domains, as well as stressed environments, show that the method improves accuracy and robustness compared with both analytical approximations and standard neural-network approaches. Because the correction remains lightweight and structurally consistent with the underlying model, the framework is well suited for real-time pricing and calibration in practical trading environments.
SNAPO trains neural policies in differentiable simulators and computes hundreds of sensitivities at the cost of a single reverse pass.
abstractclick to expand
Many real-world problems require sequential decisions under uncertainty: when to inject or withdraw gas from storage, how to rebalance a pension portfolio each month, what temperature profile to run through a pharmaceutical reactor chain. Dynamic programming solves small instances exactly but scales exponentially in state dimensions. Black-box reinforcement learning handles high-dimensional states but trains slowly and produces no sensitivities. We introduce SNAPO (Smooth Neural Adjoint Policy Optimization), a framework that embeds a neural policy inside a known, differentiable simulator, replaces hard constraints with smooth approximations, and computes exact gradients of the objective with respect to all policy parameters and all inputs in a single adjoint pass. We demonstrate SNAPO on three domains: natural gas storage (training in under a minute, 365 forward curve sensitivities at no additional cost per sensitivity), pension fund asset-liability management (6.5x-200x sensitivity speedup over bump-and-revalue, scaling with the number of risk factors), and pharmaceutical manufacturing (cross-unit sensitivities through a 4-unit process chain, with 20 ICH Q8 regulatory sensitivities from 5 adjoint passes in 74.5 milliseconds). All sensitivities are produced by the same backward pass that trains the policy, at a cost proportional to one reverse pass regardless of how many sensitivities are computed.
In this paper, we introduce INEUS, a meshfree iterative neural solver for partial integro-differential equations (PIDEs). The method replaces the explicit evaluation of nonlocal jump integrals with single-jump sampling and reformulates PIDE solving as a sequence of recursive regression problems. Like Physics-Informed Neural Networks (PINNs), INEUS learns global solutions over the entire space-time domain, yet it offers a more efficient treatment of nonlocal terms and avoids the computationally expensive differentiation of full PIDE residuals. These features make INEUS particularly well suited for high-dimensional PDEs and PIDEs. Supported by a contraction-based convergence proof for linear PIDEs, our numerical experiments show that INEUS delivers accurate and scalable solutions for various high-dimensional linear and nonlinear examples.
Lambda quantiles, originally introduced as lambda value at risk, generalise the classical value at risk by allowing for a variable confidence level. This work presents efficient algorithms for computing lambda quantiles and demonstrates their application in portfolio optimisation. We first develop a robust algorithm, {\Lambda}-Newton-Bis, that combines Newton's method with a bisection strategy to ensure global convergence. The algorithm handles potential discontinuities and achieves local quadratic convergence under standard regularity assumptions. To address cases with multiple roots, we also propose an interval analysis approach. We then demonstrate the algorithm's computational efficiency and practical relevance within a portfolio optimization framework. To this end, we develop two alternative solution methods that incorporate the {\Lambda}-Newton-Bis procedure. Numerical experiments confirm the algorithm's convergence properties and highlight its computational advantages in optimization tasks based on lambda quantiles.
Agentic artificial intelligence systems produce outputs through sequences of interdependent autonomous decisions, yet standard evaluation assesses outputs alone and cannot diagnose the underlying process. We develop a behavioral evaluation methodology that complements output-level testing by scoring the intermediate decision process itself. Behavioral traces logged at each autonomous decision point are grouped into five-day episodes and scored along six domain-specific dimensions (regime detection, routing, adaptation, risk calibration, strategy coherence, error recovery) by an ensemble of three large language model (LLM) judges. A perturbation procedure that corrupts one dimension while leaving the other five intact confirms dimension specificity; cross-model agreement reaches Krippendorff's alpha = 0.85. The composite behavioral score correlates at Spearman rho = 0.72 with realized 20-day Sharpe ratio. Closing the loop, the framework converts deficient per-dimension scores into a credit-assigned penalty added to the Soft Actor-Critic reward. Three fine-tuning cycles, confined to validation data, reduce one-day MAPE from 0.61% to 0.54% (11.5% relative; p<0.001, d=0.31) on the held-out 2017 to 2025 test period, significant under Diebold-Mariano and localized by Giacomini-White to the high-volatility regime. The methodology is application-agnostic and applies to any agentic system whose intermediate decisions can be logged.
We introduce the Frustrated Distance Matrix (FDM) model, a dynamic extension of the static distance-matrix ensemble on S^2 analyzed by Bogomolny, Bohigas, and Schmit (BBS). Its entries are pairwise geodesic distances between N Brownian particles on the sphere evolving under quenched random pairwise couplings linear in those distances. Where the static BBS theory recovers geometric information about the underlying manifold from spectra of distance matrices on i.i.d.\ samples, the time-resolved FDM spectrum carries information about structural changes of the underlying point process. The particle dynamics realize one such change: a fast collapse from a uniform configuration onto a one-dimensional ring, followed by slow rotational drift of the ring orientation; the particle-level picture provides the ground truth against which spectral diagnostics are calibrated. We find that the static BBS template is preserved at every time, with the dynamics entering as a redistribution of spectral mass within that template, sharp enough to flag ring formation. We propose self-averaging of the bulk density as the mechanism behind this preservation, verified by an i.i.d.-resample comparison, and extract a small set of spectral diagnostics of the structural change computable from the distance matrix alone. We suggest that our diagnostics can be applied in other similar inverse-problem settings: financial correlation matrices, graph and network adjacency spectra, similarity matrices in molecular dynamics, and dynamics on parameter manifolds.
We study caplet stripping, the problem of recovering a caplet volatility term structure consistent with quoted cap volatilities. Many academic papers on the Libor market model assume caplet volatilities are readily available, whereas practitioners know they are not and extracting them is a complex task. This paper presents a practical workflow, structuring the presentation around a constructive algorithm. We start with criteria on the input data based on cap time-value monotonicity. If time values fail this check, we show how to correct the quotes using robust outlier detection based on the modified Z-score. The time-value proposition naturally leads to a direct non-bootstrap stripping approach by interpolating cap time values, which yields arbitrage-free caplet volatilities by construction. We then revisit the classic sequential bootstrap approach. We introduce compact-kernel transition interpolants (flat-linear and $C^1$ flat-smooth) that preserve bootstrap equivalence. Finally, for a richer, smoother curve, we introduce global search methods using midpoint node placement with positivity-preserving calibration. Pathological cases and detailed analyses of oscillations are provided in the appendix.
947 days of five-minute bars show gross edges capped below two-point round-trip costs for all fourteen signal families tested
abstractclick to expand
This paper tests whether intraday momentum signals derived from open-high-low-close-volume (OHLCV) data produce a statistically significant trading edge in Micro E-mini Nasdaq 100 futures (MNQ) under realistic execution constraints. Using 947 trading days of five-minute data (2021-2025), fourteen signal families are evaluated, including opening range breakouts, gap strategies, volume signals, cross-session momentum, liquidity grabs, volatility-conditioned classifiers, and news-driven strategies. All signals are assessed using strict institutional criteria: out-of-sample walk-forward validation, minimum T-statistic of 2.0, at least 30 trades, positive net return after a fixed two-point round-trip cost, and multi-year stability. No signal satisfies all criteria simultaneously. The gross edge available to next-bar-open execution is constrained to approximately 0.07-1.50 points per trade, insufficient to overcome transaction costs. A gap-continuation signal achieves T = 3.23 and +14.52 points but fails minimum sample requirements (N = 22). Two validated signals from a separate research program are included as positive controls, confirming the methodology detects genuine edge when present. The primary contribution is a reproducible falsification framework and a documented null result, highlighting structural limits of OHLCV-based intraday strategies.
It is well-known that, in the Bachelier model, when asset prices and volatilities are uncorrelated, the implied volatility coincides with the fair value of the volatility swap. In this paper, via classical It\^o calculus and Taylor expansions, we write the price for out-of-the-money (OTM) and in-the-money (ITM) options as an expansion with respect to the moneyness, where the coefficients are related to the negative (non-integer) powers of the future mean volatility. As an a application, we use it as a control variate to reduce the variance of Monte Carlo option prices in the correlated case.
 full image
full image