Theory of collective learning in populations of adaptive agents
Pith reviewed 2026-07-03 04:14 UTC · model grok-4.3
The pith
An effective reward function emerges from agent interactions to fully govern the evolution of policy distributions in learning populations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
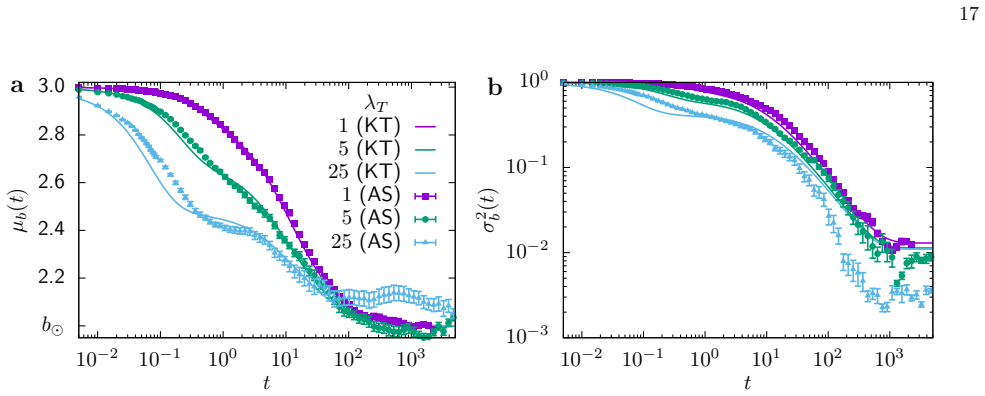
We derive formal evolution equations for the distribution of policies across the population. A central outcome of our theory is the emergence of an effective reward function that fully determines the evolution of the policy distribution and encapsulates the microscopic details of the agents physical and memory dynamics. We obtain closed equations for the policy mean and variance which admit explicit time-dependent solutions under the assumption of Gaussian-distributed memories and policies.
What carries the argument
The effective reward function that encapsulates microscopic agent dynamics and solely determines the time evolution of the policy distribution.
If this is right
- The effective reward captures how population diversity influences learning performance.
- Fluctuations in the reward slow or alter convergence of the policy distribution toward the prescribed state.
- The framework applies equally to models with perfect or partial separation of physical, memory, and policy time scales.
- One- and two-dimensional policy spaces both reduce to the same effective-reward description.
- The resulting equations recover limiting cases connected to the replicator equation and Moran model.
Where Pith is reading between the lines
- The reduction to a single effective reward suggests a route to simplify controller design in swarm robotics by tuning only that function rather than individual agent rules.
- Because the effective reward links directly to evolutionary dynamics, the same formalism may quantify how learning populations respond to changing environmental targets.
- Relaxing the Gaussian closure could expose whether learning exhibits abrupt transitions when memory distributions become heavy-tailed.
Load-bearing premise
Closed equations for policy mean and variance are obtained only when memories and policies are assumed to follow Gaussian distributions.
What would settle it
Numerical simulations of the microscopic agent models with deliberately non-Gaussian memory or policy distributions that produce mean and variance trajectories differing from the closed analytic solutions.
Figures








read the original abstract
We investigate homogeneous populations of smart active agents that exchange information with their neighbors to perform a decentralized learning process aimed at achieving a prescribed macroscopic state. Such agents may, for example, represent simple microrobots. The exchanged information comprises tunable parameters governing the agent dynamics, referred to as the individual policy, together with an internal memory encoding previously visited states. This memory is used to evaluate a reward that quantifies the success of a policy to achieve the prescribed state. We extend the kinetic-theory description of collective learning in spatially homogeneous systems [Phys. Rev. Lett. 134, 248302 (2025)] and derive formal evolution equations for the distribution of policies across the population. A central outcome of our theory is the emergence of an effective reward function that fully determines the evolution of the policy distribution and encapsulates the microscopic details of the agents physical and memory dynamics. We obtain closed equations for the policy mean and variance which admit explicit time-dependent solutions under the assumption of Gaussian-distributed memories and polices. To illustrate the framework, we present a series of minimal microscopic models, considering both perfect and partial separation of physical, memory and policy exchange time scales, as well as models with one- and two-dimensional policies. The obtained theoretical results compare well with agent-based numerical simulations. The theory captures key aspects of collective learning, including the influence of population diversity and reward fluctuations on learning performance. Finally, we discuss potential applications to swarm robotics and machine learning, and highlight connections with classical models of biological evolution, including the Replicator equation and the Moran model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends a prior kinetic-theory treatment of collective learning to homogeneous populations of adaptive agents that exchange policy parameters and internal memories to reach a prescribed macroscopic state. It derives formal evolution equations for the policy distribution across the population; a central result is the emergence of an effective reward function that governs the policy-distribution dynamics while encapsulating the microscopic physical and memory rules. Under the additional assumption of Gaussian-distributed memories and policies, closed equations for the policy mean and variance are obtained that admit explicit time-dependent solutions. The framework is illustrated on minimal models spanning perfect/partial time-scale separation and one-/two-dimensional policies; theoretical predictions are compared with agent-based simulations. Connections to the replicator equation and Moran model are noted, together with possible applications to swarm robotics and machine learning.
Significance. If the derivations hold, the work supplies a systematic coarse-graining route from microscopic agent rules to an effective macroscopic description of collective learning, with the effective reward providing a reduced, closed dynamics. The explicit Gaussian solutions and direct simulation comparisons across multiple regimes constitute concrete strengths. The explicit links to classical evolutionary models add conceptual value. The approach could be useful for analyzing decentralized learning in robotic swarms or engineered populations.
minor comments (3)
- [Abstract and introduction] The abstract states that the formal evolution equations and effective-reward construction hold more generally while the Gaussian assumption is invoked only for closed moment equations; the manuscript should make this separation explicit in the main text (e.g., by labeling the general kinetic equations versus the Gaussian closure) so readers can immediately distinguish the two levels of approximation.
- [Results/illustrative models] Quantitative measures of agreement between theory and agent-based simulations (e.g., L2 errors on mean/variance trajectories or reported R² values) are mentioned but not shown in the provided abstract; adding a short table or inset in the relevant results section would strengthen the claim of “compare well.”
- [Theory section] Notation for the effective reward function (its functional dependence on policy moments, memory statistics, etc.) should be introduced once and used consistently; any redefinition between the general kinetic equations and the Gaussian case should be flagged.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the clear summary of its contributions, and the recommendation for minor revision. We are pleased that the significance of the effective reward function, the closed Gaussian equations, and the connections to evolutionary models were recognized. Since no specific major comments were raised, we have no points requiring rebuttal or revision at this stage, but we remain ready to incorporate any additional feedback.
Circularity Check
No significant circularity; derivation self-contained with external validation
full rationale
The paper extends its own prior kinetic-theory framework (cited PRL) to derive formal evolution equations for the policy distribution, from which an effective reward function is stated to emerge while encapsulating microscopic details. Closed moment equations are obtained under an explicit Gaussian assumption on memories and policies, with explicit solutions provided. The framework is tested against independent agent-based simulations in multiple regimes (perfect/partial timescale separation, 1D/2D policies), supplying external benchmarks that are not forced by the derivation itself. No quoted step reduces a prediction to a fitted input by construction, nor does any load-bearing claim collapse to an unverified self-citation chain; the self-citation serves only as the starting point for an extension whose outputs are separately validated.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Memories and policies follow Gaussian distributions
Reference graph
Works this paper leans on
-
[1]
, Gn(S) and memoryM= (M1,
Kinetic theory with multidimensional policy and memory A starting point is to consider a multidimensional observableG(S) = G1(S), . . . , Gn(S) and memoryM= (M1, . . . ,Mn). Equation (1) then generalizes to dMj dt =λ M (Gj(S)− M j) +ξ j(t) (j= 1, . . . , n),(B1) where the Gaussian noisesξ j(t) have zero mean and correlation⟨ξj(t)ξj′(t′)⟩noise = 2DMj(P)δ j...
-
[2]
,Pq), the evolution equation forϕ(P) generalizing Eq
Dynamics of the multidimensional policy distribution and moments For a multidimensional policyP= (P 1, . . . ,Pq), the evolution equation forϕ(P) generalizing Eq. (20) is obtained by integrating Eq. (B4) over the multidimensional memoryM, yielding ∂tϕ(P) = ˜λT ρ R(P)− R ϕ(P) + qX k=1 DPk ∂2ϕ ∂P 2 k .(B5) The effective reward R(P) remains formally defined ...
-
[3]
Closures of the dynamics of the policy mean vector and covariance matrix Equations (B9) and (B10) are in general not closed, and can be dealt with in at least two ways. A first procedure consists in assuming that the policy distribution takes the form of a multivariate Gaussian distribution, which is fully parameterized by the knowledge of the policy mean...
-
[4]
Bivariate Gaussian analysis of the two-dimensional policy dynamics of AOU agents We provide in this appendix a more detailed analysis of the two-dimensional policy dynamicsP= (b, D) of the AOU agents studied in Sec. V D, now taking into account correlations between the policy componentsbandDthrough a bivariate Gaussian ansatz,ϕ(b, D) =N(µ,Σ), withµ= (µ b,...
-
[5]
Drossel, Biological evolution and statistical physics, Advances in physics50, 209 (2001)
B. Drossel, Biological evolution and statistical physics, Advances in physics50, 209 (2001)
2001
-
[6]
Sella and A
G. Sella and A. E. Hirsh, The application of statistical physics to evolutionary biology, Proceedings of the National Academy of Sciences102, 9541 (2005)
2005
-
[7]
Houchmandzadeh and M
B. Houchmandzadeh and M. Vallade, The fixation probability of a beneficial mutation in a geographically structured population, New Journal of Physics13, 073020 (2011)
2011
-
[8]
Chia and N
N. Chia and N. Goldenfeld, Statistical mechanics of horizontal gene transfer in evolutionary ecology, Journal of Statistical Physics142, 1287 (2011)
2011
-
[9]
Lorenz, Continuous opinion dynamics under bounded confidence: A survey, International Journal of Modern Physics C 18, 1819 (2007)
J. Lorenz, Continuous opinion dynamics under bounded confidence: A survey, International Journal of Modern Physics C 18, 1819 (2007)
2007
-
[10]
Castellano, S
C. Castellano, S. Fortunato, and V. Loreto, Statistical physics of social dynamics, Rev. Mod. Phys.81, 591 (2009). 34
2009
-
[11]
R. A. Watson, S. G. Ficici, and J. B. Pollack, Embodied evolution: Distributing an evolutionary algorithm in a population of robots, Robotics and Autonomous Systems39, 1 (2002)
2002
-
[12]
N. Bredeche, E. Haasdijk, and A. Prieto, Embodied evolution in collective robotics: A review, Frontiers in Robotics and AI5, 10.3389/frobt.2018.00012 (2018)
-
[13]
P. Long, T. Fan, X. Liao, W. Liu, H. Zhang, and J. Pan, Towards optimally decentralized multi-robot collision avoidance via deep reinforcement learning, in2018 IEEE international conference on robotics and automation (ICRA)(IEEE, 2018) pp. 6252–6259
2018
-
[14]
Y. Zheng, C. Huepe, and Z. Han, Experimental capabilities and limitations of a position-based control algorithm for swarm robotics, Adaptive Behavior30, 19 (2022), https://doi.org/10.1177/1059712320930418
-
[15]
Bredeche and N
N. Bredeche and N. Fontbonne, Social learning in swarm robotics, Philosophical Transactions of the Royal Society B: Biological Sciences377, 20200309 (2022)
2022
-
[16]
M. Y. Ben Zion, J. Fersula, N. Bredeche, and O. Dauchot, Morphological computation and decentralized learning in a swarm of sterically interacting robots, Science Robotics8, eabo6140 (2023)
2023
-
[17]
Novkoski, M
F. Novkoski, M. M´ elard, M. Delens, F. W´ ery, M. Noirhomme, J. Pande, A. Maier, A.-S. Smith, and N. Vandewalle, Graspion: An open-source, programmable brainbot for active matter research, Review of Scientific Instruments97, 014704 (2026)
2026
-
[18]
J. Fersula, N. Bredeche, and O. Dauchot, Aggregating swarms through morphology handling design contingencies: from the sweet spot to a rich expressivity (2026), arXiv:2601.07610 [cond-mat.soft]
-
[19]
Verdoucq, G
M. Verdoucq, G. Theraulaz, R. Escobedo, C. Sire, and G. Hattenberger, Bio-inspired control for collective motion in swarms of drones, in2022 International Conference on Unmanned Aircraft Systems (ICUAS)(2022) pp. 1626–1631
2022
-
[20]
J. Wang, G. Wang, H. Chen, Y. Liu, P. Wang, D. Yuan, X. Ma, X. Xu, Z. Cheng, B. Ji, M. Yang, J. Shuai, F. Ye, J. Wang, Y. Jiao, and L. Liu, Robo-matter towards reconfigurable multifunctional smart materials, Nat. Commun.15, 8853 (2024)
2024
-
[21]
D. Ma, J. Chen, S. Cutler, and K. Petersen, Smarticle 2.0: Design of scalable, entangled smart matter, inDistributed Autonomous Robotic Systems, edited by J. Bourgeois, J. Paik, B. Piranda, J. Werfel, S. Hauert, A. Pierson, H. Hamann, T. L. Lam, F. Matsuno, N. Mehr, and A. Makhoul (Springer Nature Switzerland, Cham, 2024) pp. 509–522
2024
-
[22]
Ozkan-Aydin, D
Y. Ozkan-Aydin, D. I. Goldman, and M. S. Bhamla, Collective dynamics in entangled worm and robot blobs, Proc. Natl. Acad. Sci. USA118, e2010542118 (2021)
2021
-
[23]
S. Li, B. Dutta, S. Cannon, J. J. Daymude, R. Avinery, E. Aydin, A. W. Richa, D. I. Goldman, and D. Randall, Program- ming active cohesive granular matter with mechanically induced phase changes, Science Advances7, eabe8494 (2021)
2021
-
[24]
Y. Zhou, J. Zu, and J. Liu, Programmable intelligent liquid matter: material, science and technology, Journal of Microme- chanics and Microengineering32, 103001 (2022)
2022
-
[25]
Kotikian, C
A. Kotikian, C. McMahan, E. C. Davidson, J. M. Muhammad, R. D. Weeks, C. Daraio, and J. A. Lewis, Untethered soft robotic matter with passive control of shape morphing and propulsion, Science Robotics4, eaax7044 (2019)
2019
-
[26]
Zeravcic, V
Z. Zeravcic, V. N. Manoharan, and M. P. Brenner, Colloquium: Toward living matter with colloidal particles, Rev. Mod. Phys.89, 031001 (2017)
2017
-
[27]
Kaspar, B
C. Kaspar, B. J. Ravoo, W. G. van der Wiel, S. V. Wegner, and W. H. P. Pernice, The rise of intelligent matter, Nature 594, 345 (2021)
2021
-
[28]
Levine and D
H. Levine and D. I. Goldman, Physics of smart active matter: integrating active matter and control to gain insights into living systems, Soft Matter19, 4204 (2023)
2023
-
[29]
Majidi, Soft-matter engineering for soft robotics, Advanced Materials Technologies4, 1800477 (2019)
C. Majidi, Soft-matter engineering for soft robotics, Advanced Materials Technologies4, 1800477 (2019)
2019
-
[30]
L. G. Mo C. and B. X., Challenges and attempts to make intelligent microswimmers, Front. Phys.11, 1279883 (2023)
2023
-
[31]
L. Cazenille, M. Toquebiau, N. Lobato-Dauzier, A. Loi, L. Macabre, N. Aubert-Kato, A. Genot, and N. Bredeche, Signaling and social learning in swarms of robots (2024), arXiv:2411.11616 [cs.RO]
-
[32]
L. G. Nava, R. Großmann, and F. Peruani, Markovian robots: Minimal navigation strategies for active particles, Phys. Rev. E97, 042604 (2018)
2018
-
[33]
Pishvar and R
M. Pishvar and R. L. Harne, Foundations for soft, smart matter by active mechanical metamaterials, Advanced Science7, 2001384 (2020)
2020
-
[34]
Cichos, K
F. Cichos, K. Gustavsson, B. Mehlig, and G. Volpe, Machine learning for active matter, Nat. Mach. Intell.2, 94–103 (2020)
2020
-
[35]
D. I. Goldman and D. Z. Rocklin, Robot swarms meet soft matter physics, Science Robotics9, eadn6035 (2024)
2024
-
[36]
Nasiri, E
M. Nasiri, E. Loran, and B. Liebchen, Smart active particles learn and transcend bacterial foraging strategies, Proceedings of the National Academy of Sciences121, e2317618121 (2024)
2024
-
[37]
te Vrugt,Artificial intelligence and intelligent matter(Springer, 2025)
M. te Vrugt,Artificial intelligence and intelligent matter(Springer, 2025)
2025
-
[38]
L¨ owen and B
H. L¨ owen and B. Liebchen, Towards intelligent active particles, inArtificial Intelligence and Intelligent Matter: Nanoscience, Soft Matter, Philosophy(Springer, 2026) pp. 257–271
2026
-
[39]
Ramaswamy, The mechanics and statistics of active matter, Annual Review of Condensed Matter Physics1, 323 (2010)
S. Ramaswamy, The mechanics and statistics of active matter, Annual Review of Condensed Matter Physics1, 323 (2010)
2010
-
[40]
M. C. Marchetti, J. F. Joanny, S. Ramaswamy, T. B. Liverpool, J. Prost, M. Rao, and R. A. Simha, Hydrodynamics of soft active matter, Rev. Mod. Phys.85, 1143 (2013)
2013
-
[41]
Ramaswamy, Active fluids, Nat
S. Ramaswamy, Active fluids, Nat. Rev. Phys.1, 640–642 (2019)
2019
-
[42]
Janzen, G
G. Janzen, G. Maselli, J. F. Jimenez, L. Garcia-Perez, D. Matoz Fernandez, and C. Valeriani, Active matter as a framework for living systems-inspired robophysics, Europhysics Letters154, 37001 (2026)
2026
-
[43]
Liebchen and H
B. Liebchen and H. L¨ owen, Optimal navigation strategies for active particles, Europhysics Letters127, 34003 (2019)
2019
-
[44]
L. Piro, E. Tang, and R. Golestanian, Optimal navigation strategies for microswimmers on curved manifolds, Phys. Rev. Res.3, 023125 (2021). 35
2021
-
[45]
L. Piro, B. Mahault, and R. Golestanian, Optimal navigation of microswimmers in complex and noisy environments, New Journal of Physics24, 093037 (2022)
2022
-
[46]
L. Piro, R. Golestanian, and B. Mahault, Efficiency of navigation strategies for active particles in rugged landscapes, Front. Phys.10, 1034267 (2022)
2022
-
[47]
Nasiri, H
M. Nasiri, H. L¨ owen, and B. Liebchen, Optimal active particle navigation meets machine learning, Europhysics Letters 142, 17001 (2023)
2023
- [48]
-
[49]
L. Cocconi, B. Mahault, and L. Piro, Dissipation-accuracy tradeoffs in autonomous control of smart active matter (2024), arXiv:2409.12595 [cond-mat.stat-mech]
- [50]
-
[51]
Echeverr´ ıa-Huarte and A
I. Echeverr´ ıa-Huarte and A. Nicolas, Body and mind: Decoding the dynamics of pedestrians and the effect of smartphone distraction by coupling mechanical and decisional processes, Transportation Research Part C: Emerging Technologies157, 104365 (2023)
2023
-
[52]
Bonnemain, M
T. Bonnemain, M. Butano, T. Bonnet, I. n. Echeverr´ ıa-Huarte, A. Seguin, A. Nicolas, C. Appert-Rolland, and D. Ullmo, Pedestrians in static crowds are not grains, but game players, Phys. Rev. E107, 024612 (2023)
2023
-
[53]
Borra, M
F. Borra, M. Cencini, and A. Celani, Optimal collision avoidance in swarms of active brownian particles, Journal of Statistical Mechanics: Theory and Experiment2021, 083401 (2021)
2021
-
[54]
L. Yang, J. Jiang, X. Gao, Q. Wang, Q. Dou, and L. Zhang, Autonomous environment-adaptive microrobot swarm navigation enabled by deep learning-based real-time distribution planning, Nature Machine Intelligence4, 480 (2022)
2022
-
[55]
Ziepke, I
A. Ziepke, I. Maryshev, I. Aranson, and E. Frey, Multi-scale organization in communicating active matter, Nat. Commun. 13, 6727 (2022)
2022
-
[56]
G. Jung, M. Ozawa, and E. Bertin, Kinetic theory of decentralized learning for smart active matter, Phys. Rev. Lett.134, 248302 (2025)
2025
-
[57]
S. Ariosto, J. Garnier-Brun, L. Saglietti, and D. Straziota, Replication and information extraction in a minimal agent- environment model, arXiv preprint arXiv:2509.23212 (2025)
-
[58]
VanSaders, M
B. VanSaders, M. Fruchart, and V. Vitelli, Measurement-induced phase transitions in informational active matter, PNAS Nexus5, pgag077 (2026)
2026
-
[59]
Garnier-Brun, R
J. Garnier-Brun, R. Zakine, and M. Benzaquen, Hydrodynamics of cooperation and self-interest in a two-population occupation model, Physical Review Letters135, 107402 (2025)
2025
-
[60]
Bertin, M
E. Bertin, M. Droz, and G. Gr´ egoire, Boltzmann and hydrodynamic description for self-propelled particles, Phys. Rev. E 74, 022101 (2006)
2006
-
[61]
Bertin, M
E. Bertin, M. Droz, and G. Gr´ egoire, Hydrodynamic equations for self-propelled particles: microscopic derivation and stability analysis, Journal of Physics A: Mathematical and Theoretical42, 445001 (2009)
2009
-
[62]
Ihle, Kinetic theory of flocking: Derivation of hydrodynamic equations, Physical Review E—Statistical, Nonlinear, and Soft Matter Physics83, 030901 (2011)
T. Ihle, Kinetic theory of flocking: Derivation of hydrodynamic equations, Physical Review E—Statistical, Nonlinear, and Soft Matter Physics83, 030901 (2011)
2011
-
[63]
Bertin, H
E. Bertin, H. Chat´ e, F. Ginelli, S. Mishra, A. Peshkov, and S. Ramaswamy, Mesoscopic theory for fluctuating active nematics, New journal of physics15, 085032 (2013)
2013
-
[64]
Ihle, Towards a quantitative kinetic theory of polar active matter, The European Physical Journal Special Topics223, 1293 (2014)
T. Ihle, Towards a quantitative kinetic theory of polar active matter, The European Physical Journal Special Topics223, 1293 (2014)
2014
-
[65]
G. Jung, J. Asnacios, M. Ozawa, O. Dauchot, and E. Bertin, Hydrodynamic description of collective learning in smart active matter (2026), in preparation
2026
-
[66]
M. E. Cates and J. Tailleur, When are active brownian particles and run-and-tumble particles equivalent? consequences for motility-induced phase separation, Europhys. Lett.101, 20010 (2013)
2013
-
[67]
Szamel, Self-propelled particle in an external potential: Existence of an effective temperature, Physical Review E90, 012111 (2014)
G. Szamel, Self-propelled particle in an external potential: Existence of an effective temperature, Physical Review E90, 012111 (2014)
2014
-
[68]
Bjedov, O
I. Bjedov, O. Tenaillon, B. Gerard, V. Souza, E. Denamur, M. Radman, F. Taddei, and I. Matic, Stress-induced mutagenesis in bacteria, Science300, 1404 (2003)
2003
-
[69]
P. L. Foster, Stress-induced mutagenesis in bacteria, Critical reviews in biochemistry and molecular biology42, 373 (2007)
2007
-
[70]
N. L. Komarova, Replicator–mutator equation, universality property and population dynamics of learning, Journal of theoretical biology230, 227 (2004)
2004
-
[71]
A. M. Saxe, J. L. McClelland, and S. Ganguli, Exact solutions to the nonlinear dynamics of learning in deep linear neural networks, arXiv preprint arXiv:1312.6120 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[72]
P. D. Taylor and L. B. Jonker, Evolutionary stable strategies and game dynamics, Mathematical biosciences40, 145 (1978)
1978
-
[73]
Hofbauer and K
J. Hofbauer and K. Sigmund, Evolutionary game dynamics, Bulletin of the American mathematical society40, 479 (2003)
2003
-
[74]
Ewens, An interpretation and proof of the fundamental theorem of natural selection, Theoretical Population Biology 36, 167 (1989)
W. Ewens, An interpretation and proof of the fundamental theorem of natural selection, Theoretical Population Biology 36, 167 (1989)
1989
-
[75]
L. L. Bonilla, Active ornstein-uhlenbeck particles, Physical Review E100, 022601 (2019)
2019
-
[76]
M. E. Cates and J. Tailleur, Motility-induced phase separation, Annual Review of Condensed Matter Physics6, 219 (2015)
2015
-
[77]
Boltzmann,Vorlesungen ¨ uber Gastheorie
L. Boltzmann,Vorlesungen ¨ uber Gastheorie. Bd. 1(Barth, 1896)
-
[78]
N. V. Brilliantov and T. P¨ oschel,Kinetic theory of granular gases(Oxford University Press, USA, 2004)
2004
-
[79]
Peshkov, E
A. Peshkov, E. Bertin, F. Ginelli, and H. Chat´ e, Boltzmann-Ginzburg-Landau approach for continuous descriptions of generic Vicsek-like models, The European Physical Journal Special Topics223, 1315 (2014). 36
2014
-
[80]
Pfeifer and G
R. Pfeifer and G. G´ omez, Morphological computation–connecting brain, body, and environment, inCreating brain-like intelligence: From basic principles to complex intelligent systems(Springer, 2009) pp. 66–83
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.