ADVENT: LLM-Driven Automatic Predicate Invention for ILP
Pith reviewed 2026-07-03 04:34 UTC · model grok-4.3
The pith
LLMs paired with Prolog verification can invent predicates that enable ILP to succeed where it previously failed entirely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ADVENT demonstrates that an iterative process of LLM-driven abductive predicate generation and deductive verification in Prolog produces human-interpretable auxiliary predicates. These predicates allow ILP to achieve a 58% success rate on tasks where standard ILP fails completely, rising to 80% with verification, and the accumulating knowledge pool provides additional gains of up to 31 percentage points through cross-task reuse.
What carries the argument
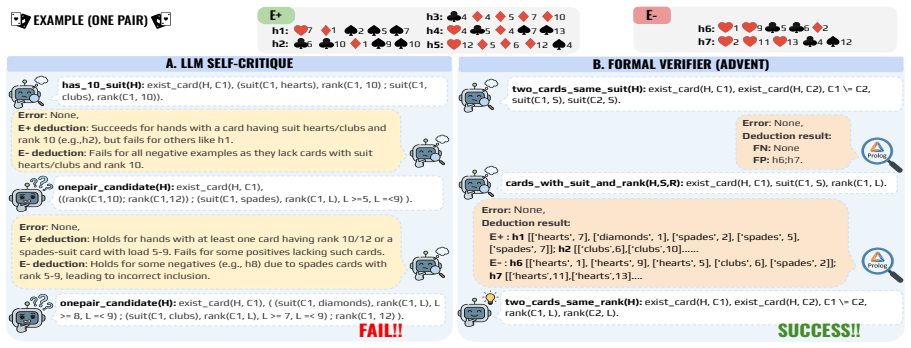
The ADVENT mechanism: an iterative loop of LLM abductive generation of predicates with meaningful names, followed by Prolog deductive verification, with invented predicates and rules stored in a knowledge pool for reuse.
If this is right
- ILP systems can handle unfamiliar domains without manual predicate definitions supplied by experts.
- Learned rules gain human interpretability through the use of meaningful predicate names and definitions.
- Performance on relational tasks improves from complete failure to over half success, and further with accumulated knowledge.
- Cross-task reuse becomes feasible, yielding measurable gains of up to 31 percentage points on related problems.
Where Pith is reading between the lines
- The same LLM-plus-verification loop might apply to other symbolic learning settings that require inventing auxiliary relations.
- Reduced dependence on human experts for predicate design could make ILP viable for a wider range of practical problems.
- Limits of the approach would become visible through tests on datasets with more complex or noisy relational structure.
Load-bearing premise
Large language models can reliably detect implicit relational patterns in structured data and produce predicates that are both correct and reusable across tasks.
What would settle it
Applying ADVENT to new relational datasets where the generated predicates consistently fail Prolog verification or produce no accuracy gain over baseline ILP would falsify the claim.
Figures


read the original abstract
Predicate invention (PI), the creation of new predicates to extend the hypothesis space, remains a critical bottleneck in Inductive Logic Programming (ILP). Existing methods rely on domain expertise and produce semantically opaque predicates, hindering adaptation to unfamiliar domains and cross-task reuse. We present ADVENT, an LLM-driven PI mechanism for ILP. ADVENT pairs LLM abductive generation with Prolog deductive verification, forming an iterative loop in which concrete execution results guide the LLM to refine candidate predicates. The mechanism leverages Large Language Models to identify implicit patterns in structured relational data and invent auxiliary predicates with meaningful names and definitions. Invented predicates and learned rules accumulate in a knowledge pool for cross-task reuse. Experiments on nine poker-hand concepts across seven LLMs show that LLM-driven PI achieves 58% success rate where ILP alone fails entirely, formal verification raises this to 80%, and the knowledge pool yields gains up to +31 percentage points, while producing human-interpretable rules. These results suggest that ADVENT offers a promising direction for automating predicate invention and enabling cross-task knowledge reuse in ILP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ADVENT, an LLM-driven approach to predicate invention (PI) in Inductive Logic Programming (ILP). It combines LLM-based abductive generation of candidate predicates with Prolog-based deductive verification in an iterative loop, using execution feedback to refine predicates, and accumulates named, interpretable predicates in a reusable knowledge pool. Experiments on nine poker-hand concepts across seven LLMs report that ADVENT achieves 58% task success (where standard ILP achieves 0%), 80% with formal verification, and gains of up to +31 percentage points from the knowledge pool.
Significance. If the empirical results are reproducible and the experimental protocol is sound, ADVENT would address a long-standing bottleneck in ILP by automating PI without domain expertise and enabling cross-task reuse of invented predicates. The explicit pairing of abductive LLM generation with deductive verification and the accumulation mechanism are concrete design choices that target reliability and reusability; the production of human-interpretable rules is an additional strength.
major comments (2)
- [Abstract / Experimental results] Abstract and experimental results: the central claims rest on specific performance numbers (58% success, 80% with verification, +31 pp gains) yet the manuscript supplies no experimental details on task encoding, number of positive/negative examples per concept, number of independent runs, statistical tests, variance, exact ILP baseline configuration, or comparison to prior PI methods. This absence prevents verification of whether the reported rates support the claim that LLM-driven PI succeeds where ILP fails.
- [Method description (abductive generation step)] The weakest assumption—that LLMs can reliably detect implicit relational patterns in structured data and produce both correct and reusable predicates—is load-bearing for the 58% figure, yet the manuscript provides no ablation isolating the contribution of the LLM generation step versus the verification loop or knowledge-pool reuse.
minor comments (2)
- [Abstract] The abstract states results across 'seven LLMs' and 'nine poker-hand concepts' but does not list which models or which exact concepts were used; this information should appear in the experimental section for reproducibility.
- [Method] Notation for the knowledge pool and the iterative loop is introduced informally; a small diagram or pseudocode would clarify the accumulation and reuse mechanism.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments identify important gaps in experimental documentation and component analysis. We address each below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results: the central claims rest on specific performance numbers (58% success, 80% with verification, +31 pp gains) yet the manuscript supplies no experimental details on task encoding, number of positive/negative examples per concept, number of independent runs, statistical tests, variance, exact ILP baseline configuration, or comparison to prior PI methods. This absence prevents verification of whether the reported rates support the claim that LLM-driven PI succeeds where ILP fails.
Authors: We agree that the current presentation lacks sufficient experimental protocol details to support independent verification of the reported rates. The manuscript will be revised to include a new subsection in the Experiments section that explicitly documents: (i) the Prolog encoding of each poker-hand concept and background knowledge, (ii) the exact number of positive and negative examples used per concept, (iii) the number of independent runs performed for each LLM, (iv) the statistical tests and variance measures applied, (v) the precise configuration of the ILP baseline (including system name and parameter settings), and (vi) direct comparisons against previously published predicate invention methods. These additions will allow readers to assess whether the 58 % success rate (and the 80 % figure with verification) substantiates the claim that LLM-driven PI succeeds where standard ILP fails. revision: yes
-
Referee: [Method description (abductive generation step)] The weakest assumption—that LLMs can reliably detect implicit relational patterns in structured data and produce both correct and reusable predicates—is load-bearing for the 58% figure, yet the manuscript provides no ablation isolating the contribution of the LLM generation step versus the verification loop or knowledge-pool reuse.
Authors: We accept that the absence of an ablation study leaves the relative contributions of the LLM generation step, the deductive verification loop, and the knowledge-pool reuse mechanism unclear. In the revised manuscript we will add an ablation subsection that reports three controlled variants: (1) LLM generation without the verification loop, (2) the full loop but without cross-task knowledge-pool reuse, and (3) the complete ADVENT pipeline. Success rates for each variant on the same nine poker-hand concepts will be presented, thereby quantifying the incremental benefit of each component and providing empirical grounding for the assumption that LLMs can detect relational patterns when paired with verification. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical LLM+Prolog iterative system for predicate invention, reporting measured success rates (58%, 80%, +31 pp) on nine fixed poker-hand tasks. No equations, derivations, fitted parameters, or first-principles claims appear; performance figures are presented as direct experimental outcomes from the described loop rather than predictions that reduce to the method's own inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Knowledge pool
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Inductive logic programming at 30: A new introduction,
A. Cropper and S. Duman ˇci´c, “Inductive logic programming at 30: A new introduction,”arXiv, 2022, accessed: Nov. 09, 2024. [Online]. Available: http://arxiv.org/abs/2008.07912
-
[2]
D. M. Gabbayet al., Eds.,Logical and Relational Learning, ser. Cognitive Technologies. Berlin, Heidelberg: Springer-Verlag Berlin Heidelberg, 2008
2008
-
[3]
Learning programs by learning from fail- ures,
A. Cropper and R. Morel, “Learning programs by learning from fail- ures,”Machine Learning, vol. 110, no. 4, pp. 801–856, Apr. 2021
2021
-
[4]
Predicate renaming via large language models,
E. Gentili, T. Ribeiro, F. Riguzzi, and K. Inoue, “Predicate renaming via large language models,”arXiv, 2025
2025
-
[5]
Forgetting to learn logic programs,
A. Cropper, “Forgetting to learn logic programs,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, Apr. 2020, pp. 3676–3683
2020
-
[6]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Junet al., “Evaluating large language models trained on code,”arXiv, 2021
2021
-
[7]
Abductive logical rule induction by bridging inductive logic programming and multimodal large language models,
Y . Peng, Y . Liu, E. Xiaet al., “Abductive logical rule induction by bridging inductive logic programming and multimodal large language models,”arXiv, 2025
2025
-
[8]
Inductive learn- ing of logical theories with LLMs: An expressivity-graded analysis,
J. ao Pedro Gandarela, D. S. Carvalho, and A. Freitas, “Inductive learn- ing of logical theories with LLMs: An expressivity-graded analysis,” arXiv, 2025
2025
-
[9]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieskeet al., “Survey of hallucination in natural language generation,”ACM Computing Surveys, vol. 55, no. 12, pp. 248:1–248:38, 2023
2023
-
[10]
Clover: Closed-loop verifi- able code generation,
C. Sun, Y . Sheng, O. Padon, and C. Barrett, “Clover: Closed-loop verifi- able code generation,” inAI Verification: First International Symposium, SAIV 2024, Montreal, QC, Canada, July 22–23, 2024, Proceedings. Berlin, Heidelberg: Springer-Verlag, 2024, pp. 134–155
2024
-
[11]
VERGE: Formal refinement and guidance engine for verifiable LLM reasoning,
V . Singh, D. Cassel, N. Weir, N. Feng, and S. Bayless, “VERGE: Formal refinement and guidance engine for verifiable LLM reasoning,”arXiv, 2026
2026
-
[12]
Fifty years of Prolog and beyond,
P. K ¨orner, M. Leuschel, J. ao Barbosa, V . S. Costa, V . Dahl, M. V . Hermenegildo, J. F. Morales, J. Wielemaker, D. Diaz, S. Abreu, and G. Ciatto, “Fifty years of Prolog and beyond,”arXiv, 2022
2022
-
[13]
Meta-interpretive learning of higher-order dyadic datalog: Predicate invention revisited,
S. H. Muggleton, D. Lin, and A. Tamaddoni-Nezhad, “Meta-interpretive learning of higher-order dyadic datalog: Predicate invention revisited,” Machine Learning, vol. 100, no. 1, pp. 49–73, Jul. 2015
2015
-
[14]
Hypothesis generation via LLM-automated language bias for ILP,
Y . Yang, J. Wu, and Y . Yue, “Hypothesis generation via LLM-automated language bias for ILP,”arXiv, 2026
2026
-
[15]
Logic-LM: Empow- ering large language models with symbolic solvers for faithful logical reasoning,
L. Pan, A. Albalak, X. Wang, and W. Y . Wang, “Logic-LM: Empow- ering large language models with symbolic solvers for faithful logical reasoning,”arXiv, 2023
2023
-
[16]
From reasoning to learning: A survey on hypothesis discovery and rule learning with large language models,
K. He and Z. Chen, “From reasoning to learning: A survey on hypothesis discovery and rule learning with large language models,”arXiv, 2025
2025
-
[17]
Poker hand,
F. O. Robert Cattral, “Poker hand,” 2002
2002
-
[18]
A theory and methodology of inductive learning,
R. S. Michalski, “A theory and methodology of inductive learning,” Artificial Intelligence, vol. 20, no. 2, pp. 111–161, Feb. 1983
1983
-
[19]
The Aleph manual,
“The Aleph manual,” 2026, accessed: Apr. 01, 2026. [Online]. Available: https://www.cs.ox.ac.uk/activities/programinduction/Aleph/aleph.html
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.