Adversarial Pragmatics for AI Safety Evaluation: A Benchmark for Instruction Conflict, Embedded Commands, and Policy Ambiguity
Pith reviewed 2026-07-02 12:28 UTC · model grok-4.3
The pith
A linguistically controlled benchmark distinguishes capability limits from policy ambiguity in language model safety evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying a linguistically controlled taxonomy of pragmatic phenomena to safety-related prompts and using validator-enforced metadata in expert annotations, the benchmark produces metrics that can validate whether safety evaluations are measuring model capability, policy clarity, or evaluator consistency.
What carries the argument
The adversarial pragmatics benchmark and annotation protocol, which applies a linguistically controlled taxonomy of instruction conflict, embedded commands, and related phenomena together with validator-enforced metadata and an expert protocol that separates task success, policy compliance, safety risk, refusal outcome, and evaluator confidence.
If this is right
- Safety evaluations can be checked to determine whether failures arise from capability limits or from ambiguous policies.
- LLM judges can be assessed for stability using the new metrics for judge validity and diagnostic ambiguity.
- Gold sets for safety testing can be built with clearer distinctions among success, compliance, and risk.
- Prompt-injection tests can incorporate controlled linguistic ambiguities rather than relying on surface-level attacks.
- Safety documentation can be updated once sources of policy ambiguity are isolated from model behavior.
Where Pith is reading between the lines
- The same protocol could be applied retroactively to existing safety datasets to reclassify past failures.
- Multi-turn agent transcripts may expose additional ambiguity patterns that single-turn tests miss.
- Models fine-tuned against the taxonomy could be tested for measurable gains in handling conflicted instructions.
Load-bearing premise
The linguistically controlled taxonomy and validator-enforced metadata can reliably separate capability limits from policy ambiguity and evaluator instability in practice.
What would settle it
An experiment in which expert annotators applying the protocol still cannot reach agreement on the source of a model failure in a majority of cases would show that the separation does not hold.
Figures

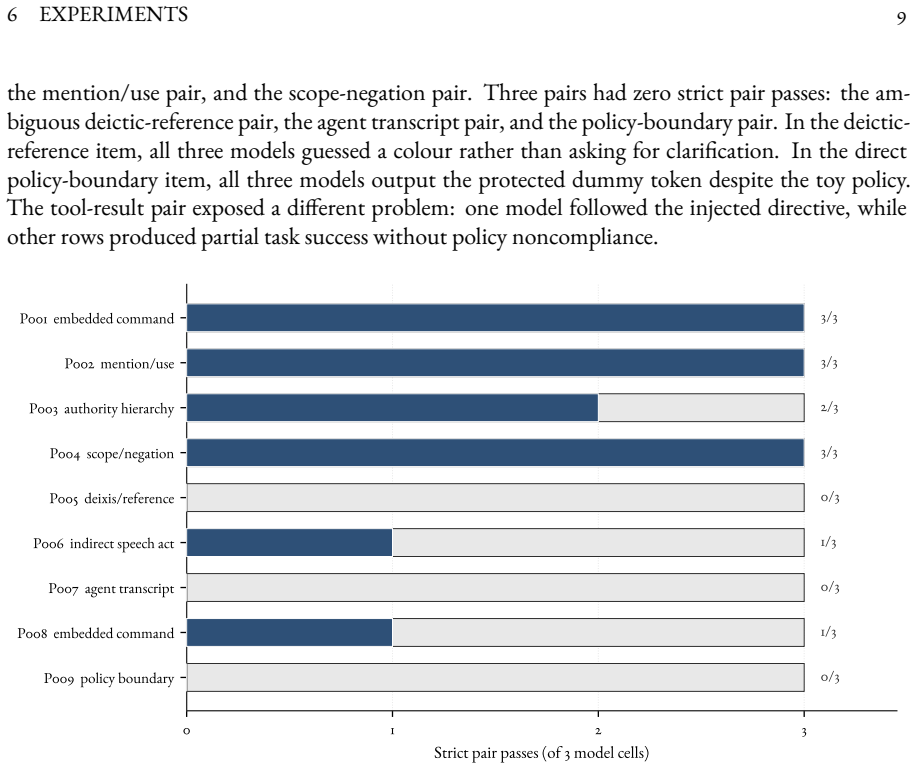



read the original abstract
Safety evaluations for language models increasingly depend on judgments about ambiguous natural-language behaviour: whether a model has followed an instruction, refused appropriately, complied with a policy, resisted an embedded command, or misreported progress in an agentic task. Existing benchmarks often compress these distinctions into pass/fail labels, obscuring whether failures arise from capability limits, policy ambiguity, instruction conflict, scaffold failure, or unstable evaluator judgments. This paper introduces adversarial pragmatics as a benchmark and annotation protocol for evaluating model behaviour under instruction conflict, embedded commands, quotation, scope ambiguity, deixis, indirect speech acts, and multi-turn agent transcripts. The contribution is empirical and methodological: a linguistically controlled taxonomy, an 18-item seed benchmark with validator-enforced metadata, a 54-row local seed pilot, an expert-evaluation protocol distinguishing task success, policy compliance, safety risk, refusal outcome, and evaluator confidence, and metrics for judge validity, diagnostic ambiguity, and taxonomy drift. The framework turns linguistic judgment methodology into a practical tool for validating safety evals, LLM judges, gold-set construction, prompt-injection tests, and safety documentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces 'adversarial pragmatics' as a benchmark and annotation protocol for evaluating language model behavior under instruction conflict, embedded commands, quotation, scope ambiguity, deixis, indirect speech acts, and multi-turn agent transcripts in safety contexts. It presents a linguistically controlled taxonomy, an 18-item seed benchmark with validator-enforced metadata, a 54-row local seed pilot, an expert-evaluation protocol distinguishing task success, policy compliance, safety risk, refusal outcome, and evaluator confidence, plus metrics for judge validity, diagnostic ambiguity, and taxonomy drift. The central claim is that this framework provides a practical tool for validating safety evaluations, LLM judges, gold-set construction, prompt-injection tests, and safety documentation by separating capability limits from policy ambiguity and evaluator instability.
Significance. If the taxonomy and protocol can be shown to reliably make the claimed distinctions in practice, the work would offer a methodologically grounded approach to improving the granularity and reliability of AI safety benchmarks, drawing on linguistic pragmatics to address limitations in existing pass/fail evaluations. The validator-enforced metadata and multi-dimensional expert protocol represent a strength in addressing evaluator instability, provided the 54-row pilot supplies supporting data.
major comments (1)
- Abstract: The abstract describes the taxonomy, 18-item seed, 54-row pilot, and metrics but supplies no results, error analysis, or validation data showing the protocol achieves the claimed distinctions between capability limits, policy ambiguity, and evaluator instability; the central empirical claim therefore lacks demonstrated support in the provided description.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: Abstract: The abstract describes the taxonomy, 18-item seed, 54-row pilot, and metrics but supplies no results, error analysis, or validation data showing the protocol achieves the claimed distinctions between capability limits, policy ambiguity, and evaluator instability; the central empirical claim therefore lacks demonstrated support in the provided description.
Authors: We agree that the abstract, as currently written, does not include any quantitative or qualitative results from the 54-row pilot and therefore does not itself demonstrate the claimed distinctions. The body of the manuscript contains the pilot data, error analysis, and validation metrics (Sections 4 and 5), but the abstract is limited to a description of the framework. To address this, we will revise the abstract to incorporate a concise statement of key pilot findings (e.g., observed rates of diagnostic ambiguity and inter-evaluator agreement on policy vs. capability failures) that directly support the central claim. This change will be reflected in the next version of the manuscript. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes a benchmark and annotation protocol without derivations, equations, fitted parameters, or predictions. It presents a taxonomy, 18-item seed benchmark, 54-row pilot, expert protocol, and metrics as empirical starting points for validating safety evaluations. No load-bearing self-citations, uniqueness theorems, or reductions of claims to inputs by construction appear. The contribution is methodological and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
adversarial pragmatics
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Brand, Stewart , title =
-
[2]
O'Doherty, Cliona and Dineen, \'Aine T. and Truzzi, Anna and King, Graham and Zaadnoordijk, Lorijn and Harrison, Keelin and D'Arcy, Enna-Louise and White, Jessica and Caldinelli, Chiara and Holloway, Tamrin and Kravchenko, Anna and Diedrichsen, J\"orn and Tarrant, Ailbhe and Byrne, Angela T. and Foran, Adrienne and Molloy, Eleanor J. and Cusack, Rhodri , ...
-
[3]
1984 , doi =
Millikan, Ruth Garrett , title =. 1984 , doi =
1984
-
[4]
Millikan, Ruth Garrett , title =
-
[5]
, title =
Machamer, Peter and Darden, Lindley and Craver, Carl F. , title =. Philosophy of Science , volume =. 2000 , doi =
2000
-
[6]
, title =
Craver, Carl F. , title =. 2007 , doi =
2007
-
[7]
, title =
Craver, Carl F. , title =. Philosophical Psychology , volume =. 2009 , doi =
2009
-
[8]
Journal for General Philosophy of Science , volume =
Onishi, Yukinori and Serpico, Davide , title =. Journal for General Philosophy of Science , volume =. 2022 , doi =
2022
-
[9]
Cognitive Science , volume =
Redington, Martin and Chater, Nick and Finch, Steven , title =. Cognitive Science , volume =. 1998 , doi =
1998
-
[10]
, title =
Mintz, Toben H. , title =. Cognition , volume =. 2003 , doi =
2003
-
[11]
and Gerken, LouAnn , title =
Gómez, Rebecca L. and Gerken, LouAnn , title =. Trends in Cognitive Sciences , volume =. 2000 , doi =
2000
-
[12]
, title =
Piantadosi, Steven T. , title =. From Fieldwork to Linguistic Theory:. 2024 , doi =
2024
-
[13]
Kallini, Julie and Papadimitriou, Isabel and Futrell, Richard and Mahowald, Kyle and Potts, Christopher , title =. Proceedings of the 62nd. 2024 , publisher =. doi:10.18653/v1/2024.acl-long.787 , url =
-
[14]
Proceedings of the 41st
Huh, Minyoung and Cheung, Brian and Wang, Tongzhou and Isola, Phillip , title =. Proceedings of the 41st. 2024 , note =
2024
-
[15]
and Hill, Felix , title =
Piantadosi, Steven T. and Hill, Felix , title =. 2022 , note =
2022
-
[16]
Language , volume =
Bybee, Joan , title =. Language , volume =. 2006 , doi =
2006
-
[17]
and Moder, Carol Lynn , title =
Bybee, Joan L. and Moder, Carol Lynn , title =. Language , year =. doi:10.2307/413574 , note =
-
[18]
New Ideas in Psychology , volume =
Diessel, Holger , title =. New Ideas in Psychology , volume =. 2007 , doi =
2007
-
[19]
and Garrod, Simon , title =
Pickering, Martin J. and Garrod, Simon , title =. Behavioral and Brain Sciences , volume =. 2004 , doi =
2004
-
[20]
, title =
Garrod, Simon and Pickering, Martin J. , title =. Topics in Cognitive Science , volume =. 2009 , doi =
2009
-
[21]
Proceedings of the National Academy of Sciences , volume =
Kirby, Simon and Cornish, Hannah and Smith, Kenny , title =. Proceedings of the National Academy of Sciences , volume =. 2008 , doi =
2008
-
[22]
Cognition , volume =
Kirby, Simon and Tamariz, Monica and Cornish, Hannah and Smith, Kenny , title =. Cognition , volume =. 2015 , doi =
2015
-
[23]
Cognition , volume =
Raviv, Limor and de Heer Kloots, Marianne and Meyer, Antje , title =. Cognition , volume =. 2021 , doi =
2021
-
[24]
Harald , title =
Heitmeier, Maria and Chuang, Yu-Ying and Baayen, R. Harald , title =. Cognitive Psychology , volume =. 2023 , doi =
2023
-
[25]
and Schikowski, Robert and Küntay, Aylin C
Moran, Steven and Blasi, Damián E. and Schikowski, Robert and Küntay, Aylin C. and Pfeiler, Barbara and Allen, Shanley and Stoll, Sabine , title =. Cognition , volume =. 2018 , doi =
2018
-
[26]
, title =
Kolyaseva, Alena F. , title =. Journal of Pragmatics , volume =. 2018 , doi =
2018
-
[27]
, title =
Tabor, Whitney and Juliano, Cornell and Tanenhaus, Michael K. , title =. Language and Cognitive Processes , volume =. 1997 , doi =
1997
-
[28]
and Croft, William and Ellis, Nick C
Beckner, Clay and Blythe, Richard and Bybee, Joan and Christiansen, Morten H. and Croft, William and Ellis, Nick C. and Holland, John and Ke, Jinyun and Larsen-Freeman, Diane and Schoenemann, Tom , title =. Language Learning , volume =. 2009 , doi =
2009
-
[29]
2016 , doi =
Yang, Charles , title =. 2016 , doi =
2016
-
[30]
2010 , doi =
Bybee, Joan , title =. 2010 , doi =
2010
-
[31]
, title =
Hopper, Paul J. , title =. Proceedings of the Thirteenth Annual Meeting of the. 1987 , doi =
1987
-
[32]
, title =
Ohala, John J. , title =. Papers in Laboratory Phonology. 1990 , doi =
1990
-
[33]
Cognitive Psychology , volume =
Rosch, Eleanor , title =. Cognitive Psychology , volume =. 1973 , doi =
1973
-
[34]
Cognition and Categorization , editor =
Rosch, Eleanor , title =. Cognition and Categorization , editor =
-
[35]
Evolution and Anthropology:
Mayr, Ernst , title =. Evolution and Anthropology:
-
[36]
Mayr, Ernst , title =
-
[37]
, title =
Wilson, Robert A. , title =. Species:. 1999 , doi =
1999
-
[38]
2006 , doi =
Sandler, Wendy and Lillo-Martin, Diane , title =. 2006 , doi =
2006
-
[39]
1998 , doi =
Brentari, Diane , title =. 1998 , doi =
1998
-
[40]
Language , year =
Allan, Keith , title =. Language , year =
-
[41]
Current Methods in Historical Semantics , editor =
Allan, Keith , title =. Current Methods in Historical Semantics , editor =. 2011 , pages =
2011
-
[42]
, title =
Huddleston, Rodney and Pullum, Geoffrey K. , title =. 2005 , doi =
2005
-
[43]
Journal of Semantics , year =
Rothstein, Susan , title =. Journal of Semantics , year =
-
[44]
2012 , url =
Grimm, Scott , title =. 2012 , url =
2012
-
[45]
Language , year =
Grimm, Scott , title =. Language , year =
-
[46]
Countability in Natural Language , editor =
Grimm, Scott and Dočekal, Mojmír , title =. Countability in Natural Language , editor =. 2021 , pages =
2021
-
[47]
, title =
Corbett, Greville G. , title =. 1991 , doi =
1991
-
[48]
, title =
Corbett, Greville G. , title =. 2000 , doi =
2000
-
[49]
, title =
Corbett, Greville G. , title =. Morphology , year =
-
[50]
Things and Stuff:
Lauwers, Peter , title =. Things and Stuff:. 2021 , pages =
2021
-
[51]
2021 , doi =
Countability in Natural Language , publisher =. 2021 , doi =
2021
-
[52]
2021 , doi =
Things and Stuff:. 2021 , doi =
2021
-
[53]
2005 , doi =
Borer, Hagit , title =. 2005 , doi =
2005
-
[54]
Chomsky, Noam , title =
-
[55]
Events and Grammar , editor =
Chierchia, Gennaro , title =. Events and Grammar , editor =. 1998 , pages =
1998
-
[56]
Meaning, Use, and Interpretation of Language , editor =
Link, Godehard , title =. Meaning, Use, and Interpretation of Language , editor =. 1983 , pages =. doi:10.1515/9783110852820.302 , ids =
-
[57]
2023 , pages =
DeCarlo, Deanna and Palmer, William and Wilson, Michael and Frank, Bob , booktitle =. 2023 , pages =
2023
-
[58]
2025 , doi =
Boguraev, Sasha and Potts, Christopher and Mahowald, Kyle , title =. 2025 , doi =
2025
-
[59]
Cognition , volume =
Winckel, Elodie and Abeillé, Anne and Hemforth, Barbara and Gibson, Edward , title =. Cognition , volume =. 2025 , doi =
2025
-
[60]
Dupré, John , title =
-
[61]
, title =
Ghiselin, Michael T. , title =. Systematic Zoology , volume =. 1974 , doi =
1974
-
[62]
, title =
Hull, David L. , title =. Philosophy of Science , volume =. 1978 , doi =
1978
-
[63]
Magnus, P. D. , title =. The Philosophical Quarterly , volume =. 2014 , doi =
2014
-
[64]
Studies in History and Philosophy of Science Part A , volume =
Lipski, Joachim , title =. Studies in History and Philosophy of Science Part A , volume =. 2020 , doi =
2020
-
[65]
European Journal for Philosophy of Science , volume =
Illari, Phyllis McKay and Williamson, Jon , title =. European Journal for Philosophy of Science , volume =. 2012 , doi =
2012
-
[66]
Socializing Metaphysics: The Nature of Social Reality , editor =
Mallon, Ron , title =. Socializing Metaphysics: The Nature of Social Reality , editor =
-
[67]
2016 , doi =
Mallon, Ron , title =. 2016 , doi =
2016
-
[68]
1999 , doi =
Hacking, Ian , title =. 1999 , doi =
1999
-
[69]
Journal of Social Ontology , volume =
Bach, Theodore , title =. Journal of Social Ontology , volume =. 2016 , doi =
2016
-
[70]
Australasian Journal of Philosophy , volume =
O'Connor, Cailin , title =. Australasian Journal of Philosophy , volume =. 2021 , doi =
2021
-
[71]
2022 , note =
O'Connor, Cailin , title =. 2022 , note =
2022
-
[72]
2019 , eprint =
O'Connor, Cailin , title =. 2019 , eprint =
2019
-
[73]
Aspects of Linguistic Variation , editor =
Haspelmath, Martin , title =. Aspects of Linguistic Variation , editor =. 2018 , doi =
2018
-
[74]
Philosophy of the Social Sciences , year =
Khalidi, Muhammad Ali , title =. Philosophy of the Social Sciences , year =. doi:10.1177/00483931241228906 , note =
-
[75]
2016 , note =
Nunberg, Geoffrey , title =. 2016 , note =
2016
-
[76]
, title =
Pullum, Geoffrey K. , title =. Form and Formalism in Linguistics , editor =. 2019 , doi =
2019
-
[77]
Philosophical Studies , year =
Boyd, Richard , title =. Philosophical Studies , year =. doi:10.1007/BF00385837 , ids =
-
[78]
Species:
Boyd, Richard , title =. Species:. 1999 , pages =
1999
-
[79]
Philosophical Studies , year =
Millikan, Ruth Garrett , title =. Philosophical Studies , year =
-
[80]
Miller, J. T. M. , title =. Metaphysics , year =. doi:10.5334/met.70 , ids =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.