HorizonRelight: Relighting Long-horizon Videos Consistently via Diffusion Transformers
Pith reviewed 2026-06-30 09:21 UTC · model grok-4.3
The pith
Propagating target-domain latents across chunks lets diffusion models relight long videos without boundary artifacts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our framework enforces cross-chunk continuity by propagating target-domain latents across boundaries and makes this behavior learnable using masked target-domain self-conditioning, training the model to continue from temporally masked propagated context. We further introduce warm-start prompting with a relit prompt anchor from a controllable generative model, which establishes the initial target-domain state and creates a general interface for prompt-based relighting.
What carries the argument
masked target-domain self-conditioning, which trains the diffusion transformer to continue relighting from temporally masked propagated latents across chunk boundaries.
If this is right
- Temporal consistency improves markedly on long-horizon videos
- Chunk-boundary artifacts are largely reduced
- Unwanted appearance changes across chunks are greatly suppressed
- Warm-start prompting provides a general interface for prompt-based relighting of long sequences
Where Pith is reading between the lines
- The same latent-propagation idea could apply to other chunked video tasks such as long video generation or editing
- Testing on videos several times longer than the training clips would reveal whether drift remains bounded
- Combining the warm-start anchor with additional control signals might extend the method to multi-prompt or style-consistent relighting
Load-bearing premise
The masked target-domain self-conditioning learned on training data will generalize to enforce consistent continuation from propagated latents on arbitrary unseen long-horizon videos without introducing new artifacts or appearance drift.
What would settle it
Running the trained model on a long unseen video and observing visible temporal discontinuities, seams, or gradual appearance drift exactly at the chunk boundaries.
Figures











read the original abstract
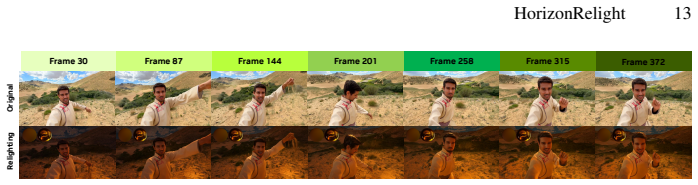
Diffusion-based video relighting enables controllable relighting from a single input video, but modern video diffusion backbones are trained on short clips and applied to long-horizon videos through chunked sliding-window inference, often causing temporal discontinuities at chunk boundaries. We address this by reframing long-horizon relighting as \emph{temporally conditioned latent domain translation}. Our framework enforces cross-chunk continuity by propagating target-domain latents across boundaries and makes this behavior learnable using \emph{masked target-domain self-conditioning}, training the model to continue from temporally masked propagated context. We further introduce \emph{warm-start prompting} with a relit prompt anchor from a controllable generative model, which establishes the initial target-domain state and creates a general interface for prompt-based relighting. Experiments on in-the-wild long-horizon videos show markedly improved temporal consistency, with chunk-boundary artifacts largely reduced and unwanted appearance changes across chunks greatly suppressed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HorizonRelight for consistent relighting of long-horizon videos with diffusion transformers. It reframes the task as temporally conditioned latent domain translation, enforces cross-chunk continuity by propagating target-domain latents, trains this behavior via masked target-domain self-conditioning on temporally masked propagated context, and adds warm-start prompting with a relit prompt anchor. The abstract claims that experiments on in-the-wild videos show markedly improved temporal consistency with reduced boundary artifacts and suppressed appearance drift.
Significance. If the central mechanism proves effective, the work would address a practical limitation of chunked inference in video diffusion models, enabling longer consistent relighting outputs. The masked self-conditioning idea for learning continuation from propagated latents could be reusable in other consistency-critical generative settings.
major comments (2)
- [Abstract] Abstract: the claim that experiments show 'markedly improved temporal consistency' with 'chunk-boundary artifacts largely reduced' is unsupported; the manuscript provides no quantitative metrics (e.g., temporal consistency scores, boundary artifact rates), no ablation tables, and no comparison baselines, making it impossible to assess whether the central claim holds.
- [Method (masked target-domain self-conditioning paragraph)] Method description of masked target-domain self-conditioning: the load-bearing assumption that training-time masking of propagated target latents will produce generalization to inference-time sliding-window propagation (without drift or new artifacts) is not tested. No analysis, distribution comparison, or multi-chunk quantitative drift measurement is reported, leaving the transfer from train to test unverified.
minor comments (1)
- [Abstract] Abstract: the phrase 'in-the-wild long-horizon videos' is used without specifying video lengths, number of chunks, or source datasets, which would help readers gauge the scope of the claimed improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims and the unverified generalization in the masked self-conditioning approach. We address each major comment below and will make revisions where the manuscript's evidence is insufficient.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments show 'markedly improved temporal consistency' with 'chunk-boundary artifacts largely reduced' is unsupported; the manuscript provides no quantitative metrics (e.g., temporal consistency scores, boundary artifact rates), no ablation tables, and no comparison baselines, making it impossible to assess whether the central claim holds.
Authors: We agree that the abstract's claims of 'markedly improved temporal consistency' and 'chunk-boundary artifacts largely reduced' are not supported by quantitative metrics, ablations, or baselines in the manuscript, which presents only qualitative visual results on in-the-wild videos. The strongest honest defense is that the visual evidence in the experiments section demonstrates reduced boundary artifacts and suppressed drift through side-by-side comparisons, but this does not quantitatively validate the claims. We will revise the abstract to qualify the language (e.g., 'visual results indicate improved temporal consistency with reduced boundary artifacts') and will add a limitations paragraph noting the absence of standardized quantitative metrics for this task. revision: yes
-
Referee: [Method (masked target-domain self-conditioning paragraph)] Method description of masked target-domain self-conditioning: the load-bearing assumption that training-time masking of propagated target latents will produce generalization to inference-time sliding-window propagation (without drift or new artifacts) is not tested. No analysis, distribution comparison, or multi-chunk quantitative drift measurement is reported, leaving the transfer from train to test unverified.
Authors: The design of masked target-domain self-conditioning trains continuation from temporally masked propagated latents to encourage generalization to sliding-window inference. However, the referee is correct that no explicit analysis (e.g., latent distribution comparisons or multi-chunk drift measurements) is reported to verify the train-to-test transfer without introducing new artifacts or drift. We will add a targeted ablation or analysis subsection in the revised manuscript to include such verification, such as measuring appearance consistency across multiple propagated chunks on held-out sequences. revision: yes
Circularity Check
No circularity; framework is a self-contained training/inference design
full rationale
The paper presents a new reframing of long-horizon relighting as temporally conditioned latent domain translation, with explicit mechanisms (propagating target-domain latents, masked target-domain self-conditioning during training, and warm-start prompting). No equations or claims reduce a prediction to a fitted input by construction, no load-bearing self-citations are invoked for uniqueness or ansatz, and no renaming of known results occurs. The derivation chain consists of architectural choices and training procedures that are independent of prior fitted results from the same authors. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y ., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y ., Cui, Y ., Ding, Y ., et al.: Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Alhaija, H.A., Alvarez, J., Bala, M., Cai, T., Cao, T., Cha, L., Chen, J., Chen, M., Ferroni, F., Fidler, S., et al.: Cosmos-transfer1: Conditional world generation with adaptive multimodal control. arXiv preprint arXiv:2503.14492 (2025)
-
[4]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Bharadwaj, S., Feng, H., Becherini, G., Fernandez Abrevaya, V ., Black, M.J.: Genlit: Refor- mulating single-image relighting as video generation. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–12 (2025)
2025
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y ., English, Z., V oleti, V ., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[7]
Chefer, H., Singer, U., Zohar, A., Kirstain, Y ., Polyak, A., Taigman, Y ., Wolf, L., Sheynin, S.: Videojam: Joint appearance-motion representations for enhanced motion generation in video models. arXiv preprint arXiv:2502.02492 (2025)
-
[8]
i-Perception2(6), 569–576 (2011)
Cutting, J.E., Brunick, K.L., DeLong, J.E., Iricinschi, C., Candan, A.: Quicker, faster, darker: Changes in hollywood film over 75 years. i-Perception2(6), 569–576 (2011)
2011
-
[9]
In: Proceedings of the 27th annual conference on Computer graphics and interactive techniques
Debevec, P., Hawkins, T., Tchou, C., Duiker, H.P., Sarokin, W., Sagar, M.: Acquiring the reflectance field of a human face. In: Proceedings of the 27th annual conference on Computer graphics and interactive techniques. pp. 145–156 (2000)
2000
-
[10]
In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). pp. 4171–4186 (2019)
2019
-
[11]
https://ai
Google: Nano banana image generation — gemini api documentation. https://ai. google.dev/gemini-api/docs/image-generation, accessed: 2026-03-04
2026
-
[12]
He, K., Liang, R., Munkberg, J., Hasselgren, J., Vijaykumar, N., Keller, A., Fidler, S., Gilitschenski, I., Gojcic, Z., Wang, Z.: Unirelight: Learning joint decomposition and synthesis for video relighting. arXiv preprint arXiv:2506.15673 (2025)
-
[13]
In: Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles
Jiang, C., Cai, Z., Tian, Y ., Jia, Z., Wang, Y ., Wu, C.: Dcp: Addressing input dynamism in long-context training via dynamic context parallelism. In: Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. pp. 221–236 (2025)
2025
-
[14]
Advances in Neural Information Processing Systems37, 141129–141152 (2024)
Jin, H., Li, Y ., Luan, F., Xiangli, Y ., Bi, S., Zhang, K., Xu, Z., Sun, J., Snavely, N.: Neural gaffer: Relighting any object via diffusion. Advances in Neural Information Processing Systems37, 141129–141152 (2024)
2024
-
[15]
Advances in neural information processing systems35, 26565–26577 (2022)
Karras, T., Aittala, M., Aila, T., Laine, S.: Elucidating the design space of diffusion-based generative models. Advances in neural information processing systems35, 26565–26577 (2022)
2022
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kocsis, P., Philip, J., Sunkavalli, K., Nießner, M., Hold-Geoffroy, Y .: Lightit: Illumination modeling and control for diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9359–9369 (2024) HorizonRelight 17
2024
-
[17]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Lester, B., Al-Rfou, R., Constant, N.: The power of scale for parameter-efficient prompt tuning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 3045–3059 (2021)
2021
-
[18]
Li, X.L., Liang, P.: Prefix-tuning: Optimizing continuous prompts for generation. In: Pro- ceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (V olume 1: Long Papers). pp. 4582–4597 (2021)
2021
-
[19]
In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2025)
Liang, R., Gojcic, Z., Ling, H., Munkberg, J., Hasselgren, J., Lin, Z.H., Gao, J., Keller, A., Vijaykumar, N., Fidler, S., Wang, Z.: Diffusionrenderer: Neural inverse and forward rendering with video diffusion models. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2025)
2025
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lu, Y ., Zhang, J., Fang, T., Nahmias, J.D., Tsin, Y ., Quan, L., Cao, X., Yao, Y ., Li, S.: Matrix3d: Large photogrammetry model all-in-one. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 11250–11263 (2025)
2025
-
[21]
Transactions on Machine Learning Research (2025),https://openreview.net/forum?id=ntGPYNUF3t
Ma, X., Wang, Y ., Chen, X., Jia, G., Liu, Z., Li, Y .F., Chen, C., Qiao, Y .: Latte: Latent diffusion transformer for video generation. Transactions on Machine Learning Research (2025),https://openreview.net/forum?id=ntGPYNUF3t
2025
-
[22]
In: Computer graphics forum
Nalbach, O., Arabadzhiyska, E., Mehta, D., Seidel, H.P., Ritschel, T.: Deep shading: convolu- tional neural networks for screen space shading. In: Computer graphics forum. vol. 36, pp. 65–78. Wiley Online Library (2017)
2017
-
[23]
https : / / openai
OpenAI: Introducing 4o image generation. https : / / openai . com / index / introducing-4o-image-generation/(2025), accessed: 2026-03-04
2025
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4195–4205 (October 2023)
2023
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Po, R., Nitzan, Y ., Zhang, R., Chen, B., Dao, T., Shechtman, E., Wetzstein, G., Huang, X.: Long-context state-space video world models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8733–8744 (2025)
2025
-
[26]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
In: ACM SIGGRAPH 2024 Conference Papers
Zeng, C., Dong, Y ., Peers, P., Kong, Y ., Wu, H., Tong, X.: Dilightnet: Fine-grained lighting control for diffusion-based image generation. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–12 (2024)
2024
-
[28]
Zeng, Z., Deschaintre, V ., Georgiev, I., Hold-Geoffroy, Y ., Hu, Y ., Luan, F., Yan, L.Q., Hašan, M.: Rgb↔x: Image decomposition and synthesis using material- and lighting-aware diffusion models. In: ACM SIGGRAPH 2024 Conference Papers. SIGGRAPH ’24, Association for Computing Machinery, New York, NY , USA (2024). https://doi.org/10.1145/ 3641519.3657445,...
-
[29]
In: The Thirteenth International Conference on Learning Representations (2025), https://openreview
Zhang, L., Rao, A., Agrawala, M.: Scaling in-the-wild training for diffusion-based illumi- nation harmonization and editing by imposing consistent light transport. In: The Thirteenth International Conference on Learning Representations (2025), https://openreview. net/forum?id=u1cQYxRI1H
2025
-
[30]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025), https://openreview.net/forum? id=VrYCLQ5inI
Zhang, P., Chen, Y ., Huang, H., Lin, W., Liu, Z., Stoica, I., Xing, E.P., Zhang, H.: Faster video diffusion with trainable sparse attention. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025), https://openreview.net/forum? id=VrYCLQ5inI
2025
-
[31]
Freeman, Kai Zhang, and Fujun Luan
Zhang, T., Kuang, Z., Jin, H., Xu, Z., Bi, S., Tan, H., Zhang, H., Hu, Y ., Hasan, M., Freeman, W.T., et al.: Relitlrm: Generative relightable radiance for large reconstruction models. arXiv preprint arXiv:2410.06231 (2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.