Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Pith reviewed 2026-05-23 04:51 UTC · model grok-4.3
The pith
Hunyuan3D 2.0 scales flow-based diffusion transformers to generate high-resolution textured 3D assets that outperform prior models in geometry, alignment, and texture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
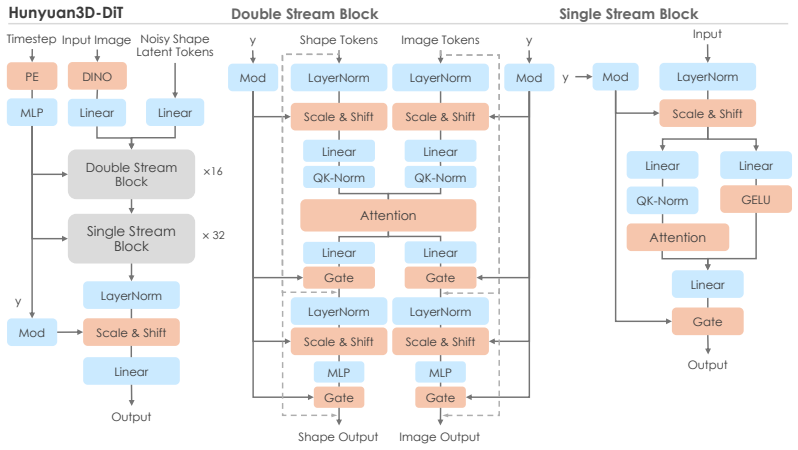
Hunyuan3D 2.0 consists of Hunyuan3D-DiT, a scalable flow-based diffusion transformer that generates geometry aligned with a condition image, and Hunyuan3D-Paint, a texture synthesis model that produces high-resolution vibrant texture maps for generated or hand-crafted meshes; together they deliver measurable improvements in geometry details, condition alignment, and texture quality over previous state-of-the-art systems.
What carries the argument
The scalable flow-based diffusion transformer (Hunyuan3D-DiT) for condition-aligned shape generation paired with the geometric-prior texture model (Hunyuan3D-Paint).
If this is right
- Shapes produced by the system align more closely with given condition images than earlier generators.
- Texture maps reach higher resolution and vibrancy on both new and existing meshes.
- The accompanying Hunyuan3D-Studio platform lets users manipulate and animate meshes with less manual effort.
- Public release of weights and code supplies the open-source community with large-scale 3D foundation models.
Where Pith is reading between the lines
- Production pipelines in games or film could shorten iteration cycles by adopting the released models for initial asset creation.
- Combining the shape and texture stages into a single end-to-end pipeline might become feasible once training resources grow.
- The same scaling approach could be tested on related tasks such as 3D animation or scene-level generation.
Load-bearing premise
The reported performance gains rest on fair comparisons that do not hide differences in training data scale, compute, or evaluation choices.
What would settle it
An independent side-by-side test in which another model matches or exceeds Hunyuan3D 2.0 scores on geometry detail, condition alignment, and texture quality when both systems are evaluated with matching disclosed data and compute budgets.
Figures










read the original abstract
We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Hunyuan3D 2.0, a large-scale 3D synthesis system with two core components: Hunyuan3D-DiT, a scalable flow-based diffusion transformer for generating geometry aligned to condition images, and Hunyuan3D-Paint, a texture synthesis model leveraging geometric and diffusion priors to produce high-resolution textures on generated or hand-crafted meshes. It also introduces Hunyuan3D-Studio, a user-friendly platform for mesh manipulation and animation. The authors claim systematic evaluations demonstrate outperformance over prior SOTA open- and closed-source models in geometry details, condition alignment, texture quality, and related metrics, and publicly release the code and pre-trained weights.
Significance. If the outperformance claims hold under reproducible conditions, this would be a significant contribution to the open-source 3D generation community by providing large-scale foundation models for shape and texture. The public release of code, weights, and the studio platform is a clear strength that supports independent verification and broader adoption.
major comments (2)
- [§4 (Experiments)] The central claim of outperformance (abstract and §4) rests on systematic evaluations, yet the manuscript provides insufficient detail on evaluation protocols, exact datasets, baseline implementations (especially for closed-source models), metric definitions, and statistical analysis; this directly affects verifiability of superiority in geometry, alignment, and texture.
- [Abstract and §4] Comparisons with closed-source models (abstract) do not specify access methods, version matching, or compute equalization, which is load-bearing for the fairness of the outperformance claim.
minor comments (2)
- [§3 (Method)] The description of Hunyuan3D-DiT and Hunyuan3D-Paint would benefit from explicit statements on model scale (parameters, training data volume) to contextualize the scaling claims.
- [§4] Figure captions and tables in the experiments section should include error bars or variance measures where quantitative results are reported.
Simulated Author's Rebuttal
We thank the referee for the constructive comments regarding the verifiability of our experimental claims. We address each major comment below and will make revisions to improve transparency and reproducibility.
read point-by-point responses
-
Referee: [§4 (Experiments)] The central claim of outperformance (abstract and §4) rests on systematic evaluations, yet the manuscript provides insufficient detail on evaluation protocols, exact datasets, baseline implementations (especially for closed-source models), metric definitions, and statistical analysis; this directly affects verifiability of superiority in geometry, alignment, and texture.
Authors: We agree that the current level of detail in Section 4 is insufficient for full independent verification. In the revised manuscript we will expand the experimental section with explicit descriptions of the evaluation protocols, the precise datasets and test splits employed, implementation details or references for all baselines (including closed-source models), formal definitions of each metric, and any statistical procedures such as variance across runs or significance testing. revision: yes
-
Referee: [Abstract and §4] Comparisons with closed-source models (abstract) do not specify access methods, version matching, or compute equalization, which is load-bearing for the fairness of the outperformance claim.
Authors: We acknowledge that the manuscript does not currently provide these specifics. We will revise both the abstract and Section 4 to document the access methods (official APIs or interfaces), the dates or versions used for each closed-source model, and the steps taken to equalize compute where feasible. For proprietary systems we will note the inherent limitations on exact version matching while supplying the best available information. revision: yes
Circularity Check
No significant circularity; empirical release with public code
full rationale
The paper describes an empirical 3D generation system (Hunyuan3D-DiT shape model and Hunyuan3D-Paint texture model) built on standard diffusion transformers, with systematic benchmark evaluations and public code/weights release. No derivation chain, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. Claims of outperformance rest on external comparisons rather than internal reductions, rendering the work self-contained against benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 60 Pith papers
-
CORGI: Consistency-Aware 3D Dog Reconstruction from a Single Image in the Wild
A new pipeline using canonical LoRAs for view synthesis, deformable 3D Gaussian splatting anchored on D-SMAL, and generative repair to produce animatable 3D dogs from single wild images without 3D supervision.
-
WarpHammer: Densifying Scene Warps with 3D Object Priors for Extreme View Synthesis
WarpHammer densifies scene warps with 3D object priors from generative models and fuses pose-unknown auxiliary views via multi-view geometry to enable stable extreme novel view synthesis.
-
UnfoldArt: Zero-Shot Recovery of Full Articulated 3D Objects from Text or Image
UnfoldArt uses multi-agent debate grounded in vision-language and video models to infer articulation parameters and reconstruct full 3D objects including occluded parts from text or image inputs.
-
UnfoldArt: Zero-Shot Recovery of Full Articulated 3D Objects from Text or Image
UnfoldArt uses a two-round structured debate between high-level semantic agents and low-level parameter agents, grounded in generated video, to infer articulation and reconstruct full articulated 3D objects including ...
-
GenRecon: Bridging Generative Priors for Multi-View 3D Scene Reconstruction
GenRecon lifts object-level generative priors to scene-scale reconstruction by chunking scenes and using projection-based conditioning on multi-view features, claiming 16% better results than prior methods.
-
Stream3D: Sequential Multi-View 3D Generation via Evidential Memory
Stream3D is a training-free method that maintains temporal consistency in 3D generation from monocular streams by dynamically caching a fixed number of informative historical frames using an evidence score.
-
CelloCut: Constructive Watertight Remeshing via Tetrahedral Cell Cuts
CelloCut formulates watertight remeshing as binary labeling on a Delaunay tetrahedral partition solved by graph-cut minimization with one-sided constraints to guarantee volumetrically consistent solids.
-
QuadLink: Autoregressive Quad-Dominant Mesh Generation via Point-Relation Learning
QuadLink generates anisotropic quad-dominant meshes from point clouds via anchor prediction, centroid-conditioned linking, and quad-first assembly, supporting hybrid n-gon topology.
-
OmniFit: Multi-modal 3D Body Fitting via Scale-agnostic Dense Landmark Prediction
OmniFit uses a conditional transformer decoder to predict dense body landmarks from multi-modal inputs for scale-agnostic SMPL-X fitting, outperforming prior methods by 57-81% and reaching millimeter accuracy on CAPE ...
-
Geometrically Consistent Multi-View Scene Generation from Freehand Sketches
A framework generates consistent multi-view scenes from one freehand sketch via a ~9k-sample dataset, Parallel Camera-Aware Attention Adapters, and Sparse Correspondence Supervision Loss, outperforming baselines in re...
-
Towards Realistic and Consistent Orbital Video Generation via 3D Foundation Priors
A video generation approach conditions a base model with multi-scale 3D latent features and a cross-attention adapter to produce geometrically realistic and consistent orbital videos from one image.
-
Any 3D Scene is Worth 1K Tokens: 3D-Grounded Representation for Scene Generation at Scale
A 3D-grounded autoencoder and diffusion transformer allow direct generation of 3D scenes in an implicit latent space using a fixed 1K-token representation for arbitrary views and resolutions.
-
GenLCA: 3D Diffusion for Full-Body Avatars from In-the-Wild Videos
GenLCA enables scalable training of a 3D diffusion model for photorealistic, animatable full-body avatars by tokenizing large-scale real-world videos with a pretrained reconstructor and applying visibility-aware diffu...
-
InverseDraping: Recovering Sewing Patterns from 3D Garment Surfaces via BoxMesh Bridging
A two-stage autoregressive framework centered on BoxMesh recovers parametric sewing patterns from 3D garment surfaces, claiming state-of-the-art results on benchmarks and generalization to real scans and single-view images.
-
PerpetualWonder: Long-Horizon Action-Conditioned 4D Scene Generation
PerpetualWonder introduces a closed-loop generative simulator with a unified physical-visual representation for long-horizon action-conditioned 4D scene generation from one image.
-
VecSet-Edit: Unleashing Pre-trained LRM for Mesh Editing from Single Image
VecSet-Edit is the first method to perform high-fidelity mesh editing from a single image by analyzing and manipulating spatial token subsets in a pre-trained VecSet LRM.
-
ATATA: One Algorithm to Align Them All
ATATA enables fast joint inference of structurally aligned pairs using Rectified Flow models via segment transport, improving state-of-the-art for image and video generation while matching 3D quality at much higher speed.
-
LangDriveCTRL: Natural Language Controllable Driving Scene Editing with Multi-modal Agents
LangDriveCTRL decomposes driving videos into 3D scene graphs and uses an agentic pipeline with specialized multi-modal agents to perform language-controlled object and behavior edits, achieving nearly 2x higher instru...
-
PacTure: Efficient PBR Texture Generation on Packed Views with Visual Autoregressive Models
PacTure uses view packing and next-scale autoregressive prediction to generate consistent multi-view PBR textures faster than prior sequential or cross-attention methods.
-
Ink3D: Sculpting 3D Assets with Extremely Complex Textures via Video Generative Models
Ink3D decouples geometry from texture by generating dense orbit videos with a conditional video model and baking them via a neural optimizer to produce complex 3D textures.
-
PointSplat: Compact Gaussian Splatting via Human-Centric Prediction
PointSplat infers compact Gaussian splats directly in 3D space from input point sets via ray casting and Point-Image Transformer to reduce inter-view redundancy and improve novel-view quality for humans.
-
Mesh BDF: Barycentric Dominance Field for 3D Native Mesh Generation
Barycentric Dominance Field converts discrete mesh connectivity into a continuous surface signal that diffusion models can use directly for higher-quality native 3D mesh generation.
-
DualBrep: A Dual-Field Continuous Representation for B-rep Modelling
DualBrep encodes B-rep models as dual scalar fields (SDF geometry + UDF topology) compressed into a shared latent space for flow-matching generation and neural B-rep extraction.
-
HandMade: Spatial Prompting for Generative 3D Creation with Part-Labeled VR Sketches
HandMade converts segmented VR strokes into multi-view part guidance and structured prompts so generative 3D models better preserve user-specified spatial scaffolds than text-only or sketch baselines.
-
SubdivAR: Autoregressive Next-Scale Prediction for Neural Mesh Subdivision
SubdivAR reformulates neural mesh subdivision as autoregressive next-scale coordinate prediction with a topology-aware transformer and reports 18.8% and 14.2% reductions in Hausdorff and Chamfer distance over baseline...
-
HiFiVe: High-Fidelity Vehicle Generation Leveraging Auto-Regressive 2D Generative Priors
HiFiVe is a training-free framework using an auto-regressive texture refinement pipeline with depth-based warping, multi-view fusion, and symmetry to enhance both texture and geometry fidelity in vehicle generation fr...
-
Artic-O: End-to-End Articulated Object Reconstruction via Latent Geometry Learning
Artic-O introduces an end-to-end feed-forward model that reconstructs articulated objects from sparse multi-state images via latent geometry learning and an image-grounded part-reasoning module, outperforming staged m...
-
Surflo: Consistent 3D Surface Flow Model with Global State
Surflo compresses unposed RGB views into K global latent tokens and uses flow matching with photometric guidance to decode consistent arbitrary-resolution 3D surface points in one forward pass.
-
DeepJEB++: Foundation Model-Driven Large-Scale 3D Engineering Dataset via 2D Latent Space Augmentation
DeepJEB++ expands a small seed set of jet engine brackets into 15,360 labeled 3D designs via 2D latent diffusion augmentation, VLM filtering, generative 3D lifting, and automated finite-element labeling.
-
MORPHOS: Autoregressive 4D Generation with Temporal Structured Latents
MORPHOS introduces an autoregressive 4D generation method with Temporal Structured Latents (T-SLAT) that produces dynamic 3D assets from videos while handling topological changes and long sequences.
-
FoundObj: Self-supervised Foundation Models as Rewards for Label-free 3D Object Segmentation
FoundObj uses foundation-model priors as RL rewards to discover multi-class 3D objects from point clouds without scene-level labels.
-
Helix4D: Complex 4D Mesh Generation
Helix4D generates high-quality dynamic 4D meshes from videos by extending Trellis2 with sliding-window cross-frame attention anchored on the first frame and a repurposed 4D temporal encoding.
-
Fishbone: From One 3D Asset to a Million Controllable Edits
Fishbone introduces a unified rib-spine representation computed via adaptive heat method, iso-contour ribs, and geometry-aware spine that enables real-time parametric deformation, reduced-space simulation, and animati...
-
Stream3D: Sequential Multi-View 3D Generation via Evidential Memory
Stream3D is a training-free method that maintains a fixed-size evidential memory of past frames to convert frozen view-conditioned 3D generators into consistent streaming generators.
-
ROAR-3D: Routing Arbitrary Views for High-Fidelity 3D Generation
ROAR-3D adds a token-wise view router and dual-stream attention to pretrained single-view 3D generators so they can use arbitrary unposed images for higher-fidelity output.
-
QuadLink: Autoregressive Quad-Dominant Mesh Generation via Point-Relation Learning
QuadLink generates anisotropic quad-dominant meshes from point clouds via a hybrid centroid-conditioned vertex linking model and a Tri-to-Quad data conversion operator.
-
TOPOS: High-Fidelity and Efficient Industry-Grade 3D Head Generation
TOPOS creates high-fidelity 3D heads with fixed industry topology from single images via a specialized VAE with Perceiver Resampler and a rectified flow transformer.
-
Real2Sim in HOI: Toward Physically Plausible HOI Reconstruction from Monocular Videos
HA-HOI produces physically plausible 4D HOI animations from monocular videos by anchoring object reconstruction to human motion and refining the result in a physics-based humanoid-object simulator.
-
Pixal3D: Pixel-Aligned 3D Generation from Images
Pixal3D performs pixel-aligned 3D generation from images via back-projected multi-scale feature volumes, achieving fidelity close to reconstruction while supporting multi-view and scene synthesis.
-
GenMed: A Pairwise Generative Reformulation of Medical Diagnostic Tasks
GenMed uses diffusion models to capture P(X,Y) for medical tasks and performs inference via gradient-based test-time optimization, supporting arbitrary observation combinations without retraining.
-
DVD: Discrete Voxel Diffusion for 3D Generation and Editing
DVD applies discrete diffusion directly to voxel occupancy for 3D generation, uncertainty estimation via entropy, and single-round editing via block perturbation fine-tuning.
-
DVD: Discrete Voxel Diffusion for 3D Generation and Editing
DVD treats voxel occupancy as a discrete variable in a diffusion framework to generate, assess, and edit sparse 3D voxels without continuous thresholding.
-
Structured 3D Latents Are Surprisingly Powerful: Unleashing Generalizable Style with 2D Diffusion
DiLAST optimizes 3D latents via guidance from a 2D diffusion model to enable generalizable style transfer for OOD styles in 3D asset generation.
-
CADFit: Precise Mesh-to-CAD Program Generation with Hybrid Optimization
CADFit recovers complex editable CAD construction sequences from meshes via IoU-driven hybrid optimization over structured programs, outperforming prior methods on volumetric IoU, Chamfer Distance, and invalid ratio.
-
CADFit: Precise Mesh-to-CAD Program Generation with Hybrid Optimization
CADFit recovers complex editable CAD construction sequences from meshes via IoU-driven hybrid optimization and outperforms prior mesh-to-CAD methods on volumetric IoU, Chamfer Distance, and invalid program ratio.
-
MeshReGen: A Unified 3D Geometry Regeneration Framework
MeshReGen introduces a conditioned 3D geometry regenerator with VecSet that learns a regeneration prior via self-supervision and reports state-of-the-art results on controllable generation tasks.
-
MeshReGen: A Unified 3D Geometry Regeneration Framework
3D-ReGen is a conditioned 3D regenerator using VecSet that learns a regeneration prior from unlabeled 3D datasets via self-supervised tasks and achieves state-of-the-art results on controllable 3D geometry tasks.
-
Sculpt4D: Generating 4D Shapes via Sparse-Attention Diffusion Transformers
Sculpt4D generates temporally coherent 4D shapes by integrating a block sparse attention mechanism with time-decaying mask into a pretrained 3D diffusion transformer, achieving SOTA results with 56% less computation.
-
MetaEarth3D: Unlocking World-scale 3D Generation with Spatially Scalable Generative Modeling
MetaEarth3D is the first generative foundation model for spatially consistent, unbounded 3D scene generation at planetary scale using optical Earth observation data.
-
PostureObjectstitch: Anomaly Image Generation Considering Assembly Relationships in Industrial Scenarios
PostureObjectStitch generates assembly-aware anomaly images by decoupling multi-view features into high-frequency, texture and RGB components, modulating them temporally in a diffusion model, and applying conditional ...
-
Beyond Voxel 3D Editing: Learning from 3D Masks and Self-Constructed Data
BVE framework enables text-guided 3D editing beyond voxel limits by combining self-constructed data, lightweight semantic injection, and annotation-free masking to preserve local invariance.
-
Pair2Scene: Learning Local Object Relations for Procedural Scene Generation
Pair2Scene generates complex 3D scenes beyond training data by recursively applying a learned model of local support and functional object-pair relations inside hierarchies, using collision-aware rejection sampling fo...
-
Pair2Scene: Learning Local Object Relations for Procedural Scene Generation
Pair2Scene generates complex 3D scenes beyond training data by training a network on local object-pair placement rules and applying them recursively with collision-aware sampling.
-
AssemLM: A Spatial Reasoning Multimodal Large Language Model for Robotic Assembly
AssemLM uses a specialized point cloud encoder inside a multimodal LLM to reach state-of-the-art 6D pose prediction for assembly tasks, backed by a new 900K-sample benchmark called AssemBench.
-
UniRecGen: Unifying Multi-View 3D Reconstruction and Generation
UniRecGen unifies reconstruction and generation via shared canonical space and disentangled cooperative learning to produce complete, consistent 3D models from sparse views.
-
MV-SAM3D: Adaptive Multi-View Fusion for Layout-Aware 3D Generation
MV-SAM3D adds multi-view fusion via multi-diffusion with attention-entropy and visibility weighting plus physics-aware optimization to improve fidelity and physical plausibility in layout-aware 3D generation.
-
Restore3D: Breathing Life into Broken Objects with Shape and Texture Restoration
Restore3D restores shape and texture of broken 3D objects via multi-view image refinement with a Mask Self-Perceiver and coarse-to-fine mesh reconstruction, outperforming baselines on synthetic and real benchmarks.
-
Vitality-Aware Compression for Efficient Image-to-Shape Diffusion Transformers
Introduces vitality-aware compression for image-to-3D DiT models via structured pruning, adaptive quantization, and fine-tuning, claiming 66% size reduction with comparable fidelity.
-
JacobianAvatar: Temporally Consistent Semi-rigid Avatar Reconstruction from a Monocular Video
JacobianAvatar uses neural Jacobian fields with a constrained Poisson solver, signed distance regularization, and deformation-guided flow loss to produce temporally consistent avatars from monocular video.
-
HiFiVe: High-Fidelity Vehicle Generation Leveraging Auto-Regressive 2D Generative Priors
HiFiVe generates high-fidelity 3D vehicles by anchoring auto-regressive 2D texture synthesis to coarse geometry via depth warping and symmetry, then refining mesh with normal maps.
Reference graph
Works this paper leans on
-
[1]
Doodle your 3d: From abstract freehand sketches to precise 3d shapes
Hmrishav Bandyopadhyay, Subhadeep Koley, Ayan Das, Ayan Kumar Bhunia, Aneeshan Sain, Pinaki Nath Chowdhury, Tao Xiang, and Yi-Zhe Song. Doodle your 3d: From abstract freehand sketches to precise 3d shapes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9795–9805, 2024
work page 2024
-
[2]
Raphael Bensadoun, Yanir Kleiman, Idan Azuri, Omri Harosh, Andrea Vedaldi, Natalia Neverova, and Oran Gafni. Meta 3d texturegen: Fast and consistent texture generation for 3d objects. arXiv preprint arXiv:2407.02430, 2024
-
[3]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023
work page 2023
-
[4]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Mesh2tex: Generating mesh textures from image queries
Alexey Bokhovkin, Shubham Tulsiani, and Angela Dai. Mesh2tex: Generating mesh textures from image queries. In IEEE International Conference on Computer Vision (ICCV), October 2023
work page 2023
-
[6]
InstructPix2Pix: Learning to follow image editing instructions.arXiv preprint arXiv:2211.09800, 2022
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. arXiv preprint arXiv:2211.09800, 2022
-
[7]
Efficient geometry-aware 3d generative adversarial networks
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient geometry-aware 3d generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16123–16133, 2022
work page 2022
-
[8]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
Text2tex: Text-driven texture synthesis via diffusion models
Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, and Matthias Nießner. Text2tex: Text-driven texture synthesis via diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 18558–18568, 2023
work page 2023
-
[10]
Qimin Chen, Zhiqin Chen, Hang Zhou, and Hao Zhang. Shaddr: Interactive example-based geometry and texture generation via 3d shape detailization and differentiable rendering. In SIGGRAPH Asia 2023 Conference Papers, 2023
work page 2023
-
[11]
Dora: Sampling and benchmarking for 3d shape variational auto-encoders
Rui Chen, Jianfeng Zhang, Yixun Liang, Guan Luo, Weiyu Li, Jiarui Liu, Xiu Li, Xiaoxiao Long, Jiashi Feng, and Ping Tan. Dora: Sampling and benchmarking for 3d shape variational auto-encoders. arXiv preprint arXiv:2412.17808, 2024
-
[12]
Meshanything v2: Artist-created mesh generation with adjacent mesh tokenization,
Yiwen Chen, Yikai Wang, Yihao Luo, Zhengyi Wang, Zilong Chen, Jun Zhu, Chi Zhang, and Guosheng Lin. Meshanything v2: Artist-created mesh generation with adjacent mesh tokenization. arXiv preprint arXiv:2408.02555, 2024
-
[13]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024
work page 2024
-
[14]
Learning implicit fields for generative shape modeling
Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5939–5948, 2019
work page 2019
-
[15]
Mvpaint: Synchronized multi-view diffusion for painting anything 3d
Wei Cheng, Juncheng Mu, Xianfang Zeng, Xin Chen, Anqi Pang, Chi Zhang, Zhibin Wang, Bin Fu, Gang Yu, Ziwei Liu, et al. Mvpaint: Synchronized multi-view diffusion for painting anything 3d. arXiv preprint arXiv:2411.02336, 2024
-
[16]
Sdfusion: Multimodal 3d shape completion, reconstruction, and generation
Yen-Chi Cheng, Hsin-Ying Lee, Sergey Tulyakov, Alexander G Schwing, and Liang-Yan Gui. Sdfusion: Multimodal 3d shape completion, reconstruction, and generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4456–4465, 2023
work page 2023
-
[17]
Abo: Dataset and benchmarks for real-world 3d object understanding
Jasmine Collins, Shubham Goel, Kenan Deng, Achleshwar Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, Matthieu Guillaumin, and Jitendra Malik. Abo: Dataset and benchmarks for real-world 3d object understanding. CVPR, 2022. 22
work page 2022
-
[18]
A volumetric method for building complex models from range images
Brian Curless and Marc Levoy. A volumetric method for building complex models from range images. In Proceedings of the 23rd annual conference on Computer graphics and interactive techniques, pages 303–312, 1996
work page 1996
-
[19]
Objaverse-XL: A Universe of 10M+ 3D Objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl V ondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, and Ali Farhadi. Objaverse-xl: A universe of 10m+ 3d objects. arXiv preprint arXiv:2307.05663, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. arXiv preprint arXiv:2212.08051, 2022
-
[21]
Laura Downs, Anthony Francis, Nate Koenig, Brandon Kinman, Ryan Hickman, Krista Reymann, Thomas B. McHugh, and Vincent Vanhoucke. Google scanned objects: A high-quality dataset of 3d scanned household items, 2022
work page 2022
-
[22]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Fine detailed texture learning for 3d meshes with generative models
Aysegul Dundar, Jun Gao, Andrew Tao, and Bryan Catanzaro. Fine detailed texture learning for 3d meshes with generative models. IEEE Trans. Pattern Anal. Mach. Intell., 2023
work page 2023
-
[24]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[25]
3d-front: 3d furnished rooms with layouts and semantics
Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Binqiang Zhao, et al. 3d-front: 3d furnished rooms with layouts and semantics. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10933–10942, 2021
work page 2021
-
[26]
Get3d: A generative model of high quality 3d textured shapes learned from images
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. Get3d: A generative model of high quality 3d textured shapes learned from images. Advances In Neural Information Processing Systems, 35:31841–31854, 2022
work page 2022
-
[27]
Tm-net: Deep generative networks for textured meshes
Lin Gao, Tong Wu, Yu-Jie Yuan, Ming-Xian Lin, Yu-Kun Lai, and Hao Zhang. Tm-net: Deep generative networks for textured meshes. ACM Trans. Graph., 40(6):1–15, 2021
work page 2021
-
[28]
Surface simplification using quadric error metrics
Michael Garland and Paul S Heckbert. Surface simplification using quadric error metrics. In Proceedings of the 24th annual conference on Computer graphics and interactive techniques, pages 209–216, 1997
work page 1997
-
[29]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014
work page 2014
-
[30]
Sparse 3D convolutional neural networks
Ben Graham. Sparse 3d convolutional neural networks. arXiv preprint arXiv:1505.02890, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
Karol Gregor, Ivo Danihelka, Andriy Mnih, Charles Blundell, and Daan Wierstra. Deep autoregressive networks. In International Conference on Machine Learning, pages 1242–1250. PMLR, 2014
work page 2014
-
[32]
Sketch2mesh: Reconstructing and editing 3d shapes from sketches
Benoit Guillard, Edoardo Remelli, Pierre Yvernay, and Pascal Fua. Sketch2mesh: Reconstructing and editing 3d shapes from sketches. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 13023–13032, 2021
work page 2021
-
[33]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[34]
LRM: Large reconstruction model for single image to 3d
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: Large reconstruction model for single image to 3d. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[35]
New quadric metric for simplifying meshes with appearance attributes
Hugues Hoppe. New quadric metric for simplifying meshes with appearance attributes. In Proceedings Visualization’99 (Cat. No. 99CB37067), pages 59–510. IEEE, 1999
work page 1999
-
[36]
Mv-adapter: Multi-view consistent image generation made easy.arXiv preprint arXiv:2412.03632, 2024
Zehuan Huang, Yuanchen Guo, Haoran Wang, Ran Yi, Lizhuang Ma, Yan-Pei Cao, and Lu Sheng. Mv-adapter: Multi-view consistent image generation made easy. arXiv preprint arXiv:2412.03632, 2024. 23
-
[37]
Make-a-shape: a ten-million-scale 3d shape model
Ka-Hei Hui, Aditya Sanghi, Arianna Rampini, Kamal Rahimi Malekshan, Zhengzhe Liu, Hooman Shayani, and Chi-Wing Fu. Make-a-shape: a ten-million-scale 3d shape model. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[38]
Rethinking fid: Towards a better evaluation metric for image generation
Sadeep Jayasumana, Srikumar Ramalingam, Andreas Veit, Daniel Glasner, Ayan Chakrabarti, and Sanjiv Kumar. Rethinking fid: Towards a better evaluation metric for image generation. In IEEE Computer Vision and Pattern Recognition (CVPR), pages 9307–9315, 2024
work page 2024
-
[39]
Flexitex: Enhancing texture generation with visual guidance
DaDong Jiang, Xianghui Yang, Zibo Zhao, Sheng Zhang, Jiaao Yu, Zeqiang Lai, Shaoxiong Yang, Chunchao Guo, Xiaobo Zhou, and Zhihui Ke. Flexitex: Enhancing texture generation with visual guidance. arXiv preprint arXiv:2409.12431, 2024
-
[40]
3d gaussian splatting for real-time radiance field rendering
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph., 42(4):139–1, 2023
work page 2023
-
[41]
Auto-Encoding Variational Bayes
Diederik P Kingma. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[42]
EASI-Tex: Edge-aware mesh texturing from single-image
Perla Sai Raj Kishore, Yizhi Wang, Ali Mahdavi-Amiri, and Hao Zhang. EASI-Tex: Edge-aware mesh texturing from single-image. ACM Transactions on Graphics (Special Issue of SIGGRAPH), 43(4), 2024
work page 2024
-
[43]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Fitting smooth surfaces to dense polygon meshes
Venkat Krishnamurthy and Marc Levoy. Fitting smooth surfaces to dense polygon meshes. InProceedings of the 23rd annual conference on Computer graphics and interactive techniques, pages 313–324, 1996
work page 1996
-
[45]
Black Forest Labs. Flux. https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[46]
Ln3diff: Scalable latent neural fields diffusion for speedy 3D generation
Yushi Lan, Fangzhou Hong, Shuai Yang, Shangchen Zhou, Xuyi Meng, Bo Dai, Xingang Pan, and Chen Change Loy. Ln3diff: Scalable latent neural fields diffusion for speedy 3D generation. In European Conference on Computer Vision (ECCV), 2024
work page 2024
-
[47]
Gaussiananything: Interactive point cloud latent diffusion for 3d generation
Yushi Lan, Shangchen Zhou, Zhaoyang Lyu, Fangzhou Hong, Shuai Yang, Bo Dai, Xingang Pan, and Chen Change Loy. Gaussiananything: Interactive point cloud latent diffusion for 3d generation. In ICLR, 2025
work page 2025
-
[48]
Era3d: High-resolution multiview diffusion using efficient row-wise attention
Peng Li, Yuan Liu, Xiaoxiao Long, Feihu Zhang, Cheng Lin, Mengfei Li, Xingqun Qi, Shanghang Zhang, Wenhan Luo, Ping Tan, et al. Era3d: High-resolution multiview diffusion using efficient row-wise attention. arXiv preprint arXiv:2405.11616, 2024
-
[49]
Weiyu Li, Jiarui Liu, Hongyu Yan, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, and Xiaoxiao Long. Craftsman: High-fidelity mesh generation with 3d native generation and interactive geometry refiner, 2024
work page 2024
-
[50]
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, Dayou Chen, Jiajun He, Jiahao Li, Wenyue Li, Chen Zhang, Rongwei Quan, Jianxiang Lu, Jiabin Huang, Xiaoyan Yuan, Xiaoxiao Zheng, Yixuan Li, Jihong Zhang, Chao Zhang, Meng Chen, Jie Liu, Zheng Fang, Weiyan Wang, Jinbao Xue,...
work page 2024
-
[51]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. In IEEE Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[52]
Common diffusion noise schedules and sample steps are flawed
Shanchuan Lin, Bingchen Liu, Jiashi Li, and Xiao Yang. Common diffusion noise schedules and sample steps are flawed. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 5404–5411, 2024
work page 2024
-
[53]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[54]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky T. Q. Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code, 2024
work page 2024
-
[55]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, 2023. 24
work page 2023
-
[56]
Vcd-texture: Variance alignment based 3d-2d co-denoising for text-guided texturing
Shang Liu, Chaohui Yu, Chenjie Cao, Wen Qian, and Fan Wang. Vcd-texture: Variance alignment based 3d-2d co-denoising for text-guided texturing. In European Conference on Computer Vision, pages 373–389. Springer, 2025
work page 2025
-
[57]
Wen Liu, Zhixin Piao, Jie Min, Wenhan Luo, Lin Ma, and Shenghua Gao. Liquid warping gan: A unified framework for human motion imitation, appearance transfer and novel view synthesis. In Proceedings of the IEEE/CVF international conference on computer vision, pages 5904–5913, 2019
work page 2019
-
[58]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[59]
Text-guided texturing by synchronized multi-view diffusion
Yuxin Liu, Minshan Xie, Hanyuan Liu, and Tien-Tsin Wong. Text-guided texturing by synchronized multi-view diffusion. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[60]
Wonder3d: Single image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Single image to 3d using cross-domain diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9970–9980, 2024
work page 2024
-
[61]
Genesistex2: Stable, consistent and high-quality text-to-texture generation
Jiawei Lu, Yingpeng Zhang, Zengjun Zhao, He Wang, Kun Zhou, and Tianjia Shao. Genesistex2: Stable, consistent and high-quality text-to-texture generation. arXiv preprint arXiv:2409.18401, 2024
-
[62]
Latent-nerf for shape- guided generation of 3d shapes and textures
Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or. Latent-nerf for shape- guided generation of 3d shapes and textures. In IEEE Computer Vision and Pattern Recognition (CVPR), pages 12663–12673, 2023
work page 2023
-
[63]
Autosdf: Shape priors for 3d completion, reconstruction and generation
Paritosh Mittal, Yen-Chi Cheng, Maneesh Singh, and Shubham Tulsiani. Autosdf: Shape priors for 3d completion, reconstruction and generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 306–315, 2022
work page 2022
-
[64]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Laba...
work page 2023
-
[65]
Normalizing flows for probabilistic modeling and inference
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshmi- narayanan. Normalizing flows for probabilistic modeling and inference. Journal of Machine Learning Research, 22(57):1–64, 2021
work page 2021
-
[66]
On aliased resizing and surprising subtleties in gan evaluation
Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. In IEEE Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[67]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
work page 2023
-
[68]
Convolutional occupancy networks
Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. Convolutional occupancy networks. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, pages 523–540. Springer, 2020
work page 2020
-
[69]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[71]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[72]
Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies
Xuanchi Ren, Jiahui Huang, Xiaohui Zeng, Ken Museth, Sanja Fidler, and Francis Williams. Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4209–4219, 2024
work page 2024
-
[73]
Texture: Text-guided texturing of 3d shapes
Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, and Daniel Cohen-Or. Texture: Text-guided texturing of 3d shapes. In ACM SIGGRAPH 2023 conference proceedings, pages 1–11, 2023. 25
work page 2023
-
[74]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[75]
Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
work page 2023
-
[76]
Clip-forge: Towards zero-shot text-to-shape generation
Aditya Sanghi, Hang Chu, Joseph G Lambourne, Ye Wang, Chin-Yi Cheng, Marco Fumero, and Ka- mal Rahimi Malekshan. Clip-forge: Towards zero-shot text-to-shape generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18603–18613, 2022
work page 2022
-
[77]
Buildingnet: Learning to label 3d buildings
Pratheba Selvaraju, Mohamed Nabail, Marios Loizou, Maria Maslioukova, Melinos Averkiou, Andreas Andreou, Siddhartha Chaudhuri, and Evangelos Kalogerakis. Buildingnet: Learning to label 3d buildings. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10397– 10407, October 2021
work page 2021
-
[78]
Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, and Hao Su. Zero123++: a single image to consistent multi-view diffusion base model. arXiv preprint arXiv:2310.15110, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[79]
Mvdream: Multi-view diffusion for 3d generation
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d generation. In The Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[80]
Texturify: Generating textures on 3d shape surfaces
Yawar Siddiqui, Justus Thies, Fangchang Ma, Qi Shan, Matthias Nießner, and Angela Dai. Texturify: Generating textures on 3d shape surfaces. In European Conference on Computer Vision (ECCV), pages 72–88. Springer, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.