From Approximation to Emergence: A Theory of Deep Learning
Pith reviewed 2026-07-03 21:37 UTC · model grok-4.3
The pith
Deep learning theory forms a single narrative from classical approximation through optimization to modern emergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
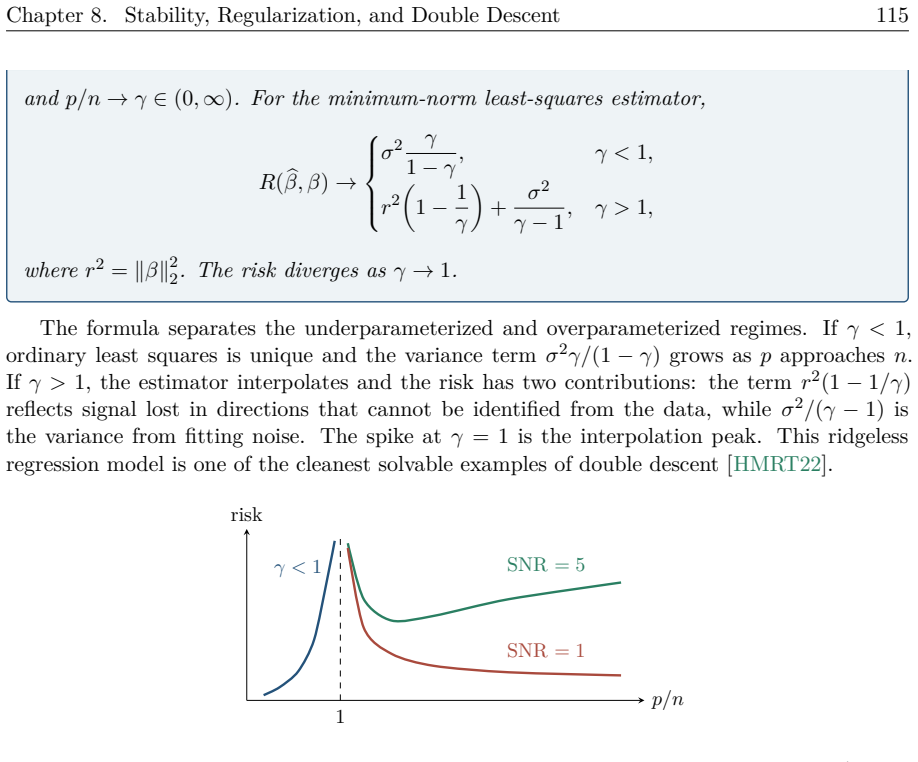
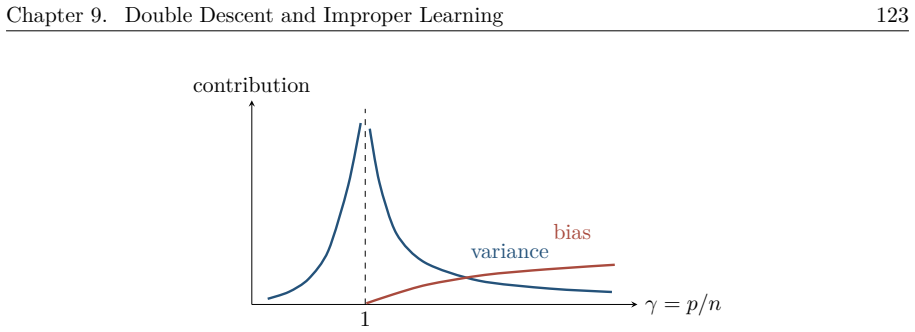
The paper establishes that deep learning theory is best organized as a continuous progression: classical approximation theory supplies representational power, optimization and generalization analyses explain trainability and performance, and contemporary topics such as overparameterization, robustness, generative modeling, transformers, in-context learning, scaling laws, interpretability, alignment, and emergence address how new mechanisms appear once scale, data volume, and architectural choices cross certain thresholds.
What carries the argument
The coherent research narrative that examines each theory through the object it controls, the assumptions that validate it, and the phenomena it leaves unexplained.
If this is right
- Approximation results set the representational limits that later scaling phenomena must respect.
- Overparameterization resolves optimization success in regimes where classical generalization bounds predict failure.
- Scaling laws and emergence mark the points at which new capabilities appear as functions of model size and data volume.
- Interpretability and alignment questions become questions about how mechanisms that arise at scale can be inspected and steered.
Where Pith is reading between the lines
- The narrative could be used to locate which current phenomena still lack any controlling theory.
- Future work might test whether the same progression applies when new architectures or training methods are introduced.
- The structure suggests that theoretical effort should concentrate on the transition regimes where emergence is observed.
Load-bearing premise
The broad and diverse literature on deep learning can be organized into one coherent narrative that accurately reflects the assumptions, scope, and limitations of each theory without significant selection bias or omissions.
What would settle it
Identification of a substantial body of results on deep learning that cannot be placed inside the proposed progression without violating the assumptions used in the earlier sections on approximation or optimization.
Figures



































































































































































































































































































































































read the original abstract
Deep learning has outgrown any single mathematical explanation. From Approximation to Emergence develops a unified, proof-oriented account of modern deep learning theory, tracing a path from the classical foundations of approximation, optimization, and generalization to the contemporary mechanisms of overparameterization, robustness, generative modeling, transformers, in-context learning, scaling laws, interpretability, alignment, and emergence. Rather than presenting isolated results, the book organizes a broad literature into a coherent research narrative: each theory is examined through the object it controls, the assumptions that make it valid, and the phenomena it leaves unexplained. Written for researchers, graduate students, and mathematically trained practitioners, this monograph offers a rigorous map of deep learning theory as it stands today: powerful, incomplete, and increasingly centered on the question of how learned mechanisms arise from scale, data, architecture, and training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a monograph synthesizing deep learning theory. It traces a path from classical foundations in approximation, optimization, and generalization to modern topics including overparameterization, robustness, generative modeling, transformers, in-context learning, scaling laws, interpretability, alignment, and emergence. The central contribution is an organizational narrative that examines each theory by the object it controls, its assumptions, and the phenomena it leaves unexplained, rather than presenting isolated results or new derivations.
Significance. If the synthesis is comprehensive and balanced, the monograph would provide a valuable reference map of the field for researchers and graduate students, highlighting the increasing focus on how mechanisms emerge from scale, data, architecture, and training. The work's strength is its explicit framing of assumptions and limitations across the literature; no new machine-checked proofs or parameter-free derivations are claimed.
minor comments (1)
- The abstract states the work is 'proof-oriented,' yet the overall description positions it as a survey of existing results; clarifying in the introduction how proofs from the cited literature are presented or re-derived would help readers assess the rigor.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the monograph's organizational narrative and for recommending minor revision. The report correctly identifies the work as a synthesis that examines theories by their controlled objects, assumptions, and unexplained phenomena, without claiming new proofs or derivations.
Circularity Check
No significant circularity: survey of existing results
full rationale
This monograph is explicitly a survey that organizes existing literature into a narrative without introducing new derivations, predictions, fitted parameters, or original theorems. The abstract and structure describe tracing paths from classical results to contemporary mechanisms by examining published theories, their assumptions, and limitations. No load-bearing steps exist that could reduce by construction to inputs, self-citations, or ansatzes, as the work contains no deductive chain or empirical claims of its own. The reader's assessment of score 0.0 is confirmed by the absence of any evaluable original content that might exhibit circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Pattern Recognition and Machine Learning , author =. 2006 , publisher =
work page 2006
-
[3]
Probabilistic Machine Learning: An Introduction , author =. 2022 , publisher =
work page 2022
-
[4]
Mathematics of Control, Signals and Systems , volume =
Approximation by superpositions of a sigmoidal function , author =. Mathematics of Control, Signals and Systems , volume =. 1989 , doi =
work page 1989
-
[5]
Approximation capabilities of multilayer feedforward networks , author =. Neural Networks , volume =. 1991 , doi =
work page 1991
-
[6]
IEEE Transactions on Information Theory , volume =
Universal approximation bounds for superpositions of a sigmoidal function , author =. IEEE Transactions on Information Theory , volume =. 1993 , doi =
work page 1993
-
[7]
Proceedings of the 29th Conference on Learning Theory , series =
The Power of Depth for Feedforward Neural Networks , author =. Proceedings of the 29th Conference on Learning Theory , series =. 2016 , publisher =
work page 2016
-
[8]
Proceedings of the 29th Conference on Learning Theory , series =
Benefits of depth in neural networks , author =. Proceedings of the 29th Conference on Learning Theory , series =. 2016 , publisher =
work page 2016
-
[9]
Error bounds for approximations with deep
Yarotsky, Dmitry , journal =. Error bounds for approximations with deep. 2017 , doi =
work page 2017
-
[10]
Advances in Neural Information Processing Systems , volume =
Neural Tangent Kernel: Convergence and Generalization in Neural Networks , author =. Advances in Neural Information Processing Systems , volume =. 2018 , url =
work page 2018
-
[11]
Proceedings of the 36th International Conference on Machine Learning , series =
Gradient Descent Finds Global Minima of Deep Neural Networks , author =. Proceedings of the 36th International Conference on Machine Learning , series =. 2019 , publisher =
work page 2019
-
[12]
Proceedings of the 36th International Conference on Machine Learning , series =
A Convergence Theory for Deep Learning via Over-Parameterization , author =. Proceedings of the 36th International Conference on Machine Learning , series =. 2019 , publisher =
work page 2019
-
[13]
Advances in Neural Information Processing Systems , volume =
Wide Neural Networks of Any Depth Evolve as Linear Models under Gradient Descent , author =. Advances in Neural Information Processing Systems , volume =. 2019 , url =
work page 2019
-
[14]
Advances in Neural Information Processing Systems , volume =
On Lazy Training in Differentiable Programming , author =. Advances in Neural Information Processing Systems , volume =. 2019 , url =
work page 2019
-
[15]
Journal of Machine Learning Research , volume =
Adaptive Subgradient Methods for Online Learning and Stochastic Optimization , author =. Journal of Machine Learning Research , volume =. 2011 , url =
work page 2011
-
[16]
International Conference on Learning Representations , year =
Adam: A Method for Stochastic Optimization , author =. International Conference on Learning Representations , year =
-
[17]
International Conference on Learning Representations , year =
On the Convergence of Adam and Beyond , author =. International Conference on Learning Representations , year =
-
[18]
International Conference on Learning Representations , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations , year =
-
[19]
Advances in Neural Information Processing Systems , volume =
The Marginal Value of Adaptive Gradient Methods in Machine Learning , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
work page 2017
-
[20]
Proceedings of the 35th International Conference on Machine Learning , series =
Characterizing Implicit Bias in Terms of Optimization Geometry , author =. Proceedings of the 35th International Conference on Machine Learning , series =. 2018 , publisher =
work page 2018
-
[21]
Journal of Machine Learning Research , volume =
The Implicit Bias of Gradient Descent on Separable Data , author =. Journal of Machine Learning Research , volume =. 2018 , url =
work page 2018
- [22]
-
[23]
Understanding Machine Learning: From Theory to Algorithms , author =. 2014 , publisher =
work page 2014
-
[24]
IEEE Transactions on Information Theory , volume =
Sample complexity of pattern classification with neural networks: the size of the weights is more important than the size of the network , author =. IEEE Transactions on Information Theory , volume =. 1998 , doi =
work page 1998
-
[25]
International Conference on Learning Representations , year =
Understanding deep learning requires rethinking generalization , author =. International Conference on Learning Representations , year =
-
[26]
Journal of Machine Learning Research , volume =
Stability and Generalization , author =. Journal of Machine Learning Research , volume =. 2002 , url =
work page 2002
-
[27]
Proceedings of the 33rd International Conference on Machine Learning , series =
Train faster, generalize better: Stability of stochastic gradient descent , author =. Proceedings of the 33rd International Conference on Machine Learning , series =. 2016 , publisher =
work page 2016
-
[28]
Proceedings of the National Academy of Sciences , volume =
Reconciling modern machine-learning practice and the classical bias--variance trade-off , author =. Proceedings of the National Academy of Sciences , volume =. 2019 , doi =
work page 2019
-
[29]
The Annals of Statistics , volume =
Surprises in High-Dimensional Ridgeless Least Squares Interpolation , author =. The Annals of Statistics , volume =. 2022 , doi =
work page 2022
- [30]
-
[31]
Efficient noise-tolerant learning from statistical queries , author =. Journal of the ACM , volume =. 1998 , doi =
work page 1998
-
[32]
International Conference on Learning Representations , year =
Intriguing properties of neural networks , author =. International Conference on Learning Representations , year =
-
[33]
International Conference on Learning Representations , year =
Explaining and Harnessing Adversarial Examples , author =. International Conference on Learning Representations , year =
-
[34]
International Conference on Learning Representations , year =
Towards Deep Learning Models Resistant to Adversarial Attacks , author =. International Conference on Learning Representations , year =
-
[35]
Proceedings of the 36th International Conference on Machine Learning , series =
Certified Adversarial Robustness via Randomized Smoothing , author =. Proceedings of the 36th International Conference on Machine Learning , series =. 2019 , publisher =
work page 2019
-
[36]
Proceedings of the 34th International Conference on Machine Learning , series =
Understanding Black-box Predictions via Influence Functions , author =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
work page 2017
-
[37]
Advances in Neural Information Processing Systems , volume =
Spectral Signatures in Backdoor Attacks , author =. Advances in Neural Information Processing Systems , volume =. 2018 , url =
work page 2018
-
[38]
Advances in Neural Information Processing Systems , volume =
Generative Adversarial Nets , author =. Advances in Neural Information Processing Systems , volume =. 2014 , url =
work page 2014
-
[39]
Proceedings of the 34th International Conference on Machine Learning , series =
Wasserstein Generative Adversarial Networks , author =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
work page 2017
-
[40]
Improved Training of Wasserstein
Gulrajani, Ishaan and Ahmed, Faruk and Arjovsky, Martin and Dumoulin, Vincent and Courville, Aaron , booktitle =. Improved Training of Wasserstein. 2017 , url =
work page 2017
-
[41]
Proceedings of the 34th International Conference on Machine Learning , series =
Compressed Sensing using Generative Models , author =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
work page 2017
-
[42]
Human-level control through deep reinforcement learning , author =. Nature , volume =. 2015 , doi =
work page 2015
-
[43]
Reinforcement Learning: An Introduction , author =. 2018 , publisher =
work page 2018
-
[44]
Advances in Neural Information Processing Systems , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
work page 2017
-
[45]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
work page 2020
-
[46]
Advances in Neural Information Processing Systems , volume =
What Can Transformers Learn In-Context? A Case Study of Simple Function Classes , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
work page 2022
-
[47]
Proceedings of the 40th International Conference on Machine Learning , series =
Transformers Learn In-Context by Gradient Descent , author =. Proceedings of the 40th International Conference on Machine Learning , series =. 2023 , publisher =
work page 2023
-
[48]
Advances in Neural Information Processing Systems , volume =
Denoising Diffusion Probabilistic Models , author =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
work page 2020
-
[49]
International Conference on Learning Representations , year =
Score-Based Generative Modeling through Stochastic Differential Equations , author =. International Conference on Learning Representations , year =
-
[50]
International Conference on Learning Representations , year =
Flow Matching for Generative Modeling , author =. International Conference on Learning Representations , year =
-
[51]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author =. arXiv preprint arXiv:2001.08361 , year =. 2001.08361 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[52]
Advances in Neural Information Processing Systems , volume =
Training Compute-Optimal Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
work page 2022
- [53]
- [54]
-
[55]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author =. 2023 , url =
work page 2023
-
[56]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets , author =. arXiv preprint arXiv:2201.02177 , year =. 2201.02177 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Progress measures for grokking via mechanistic interpretability
Progress Measures for Grokking via Mechanistic Interpretability , author =. arXiv preprint arXiv:2301.05217 , year =. 2301.05217 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Emergent Abilities of Large Language Models
Emergent Abilities of Large Language Models , author =. arXiv preprint arXiv:2206.07682 , year =. 2206.07682 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Advances in Neural Information Processing Systems , volume =
Are Emergent Abilities of Large Language Models a Mirage? , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
work page 2023
-
[60]
Advances in Neural Information Processing Systems , volume =
Deep Reinforcement Learning from Human Preferences , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
work page 2017
-
[61]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
work page 2022
-
[62]
Advances in Neural Information Processing Systems , volume =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
work page 2023
-
[63]
A theory of learning from different domains , author =. Machine Learning , volume =. 2010 , doi =
work page 2010
-
[64]
On the Opportunities and Risks of Foundation Models
On the Opportunities and Risks of Foundation Models , author =. arXiv preprint arXiv:2108.07258 , year =. 2108.07258 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.