MATCH: Multiplier-Assisted Tests for Conditional Hypotheses in Non-Euclidean Data
Pith reviewed 2026-07-03 07:30 UTC · model grok-4.3
The pith
MATCH uses sample splitting and random multipliers to test conditional Fréchet means without degeneracy from nuisance errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MATCH establishes a unified framework for significance and specification testing in Fréchet regression by constructing a test statistic through sample splitting and independent random multipliers applied to held-out losses; the resulting statistic has a nondegenerate Gaussian limit under the null that is free of nuisance estimation effects and does not require tangent-space coordinates or residual adjustments.
What carries the argument
The multiplier-assisted statistic obtained by applying independent random multipliers to held-out losses after sample splitting, which isolates a nondegenerate Gaussian leading term.
If this is right
- The tests achieve asymptotic validity under the null hypothesis.
- The procedure is consistent against fixed alternatives.
- Local power guarantees hold for the proposed tests.
- Cross-fitted versions and repeated cross-fitting with p-value merging improve data efficiency and stability.
- The method applies directly to distributional, symmetric positive-definite matrix, and spherical responses.
Where Pith is reading between the lines
- The multiplier construction may reduce the need for explicit coordinate systems in other non-Euclidean regression problems.
- Repeated cross-fitting could be examined for its effect on finite-sample size in settings with small sample sizes.
- The same splitting-plus-multiplier idea might adapt to specification tests outside Fréchet regression where loss differences are similarly degenerate.
Load-bearing premise
Independent random multipliers applied after sample splitting produce a nondegenerate leading term whose asymptotics remain unaffected by nuisance estimation error.
What would settle it
A simulation study under the null in which the limiting distribution of the MATCH statistic still depends on unknown nuisance quantities or collapses to zero would show the construction fails to deliver the claimed nondegeneracy.
Figures







read the original abstract
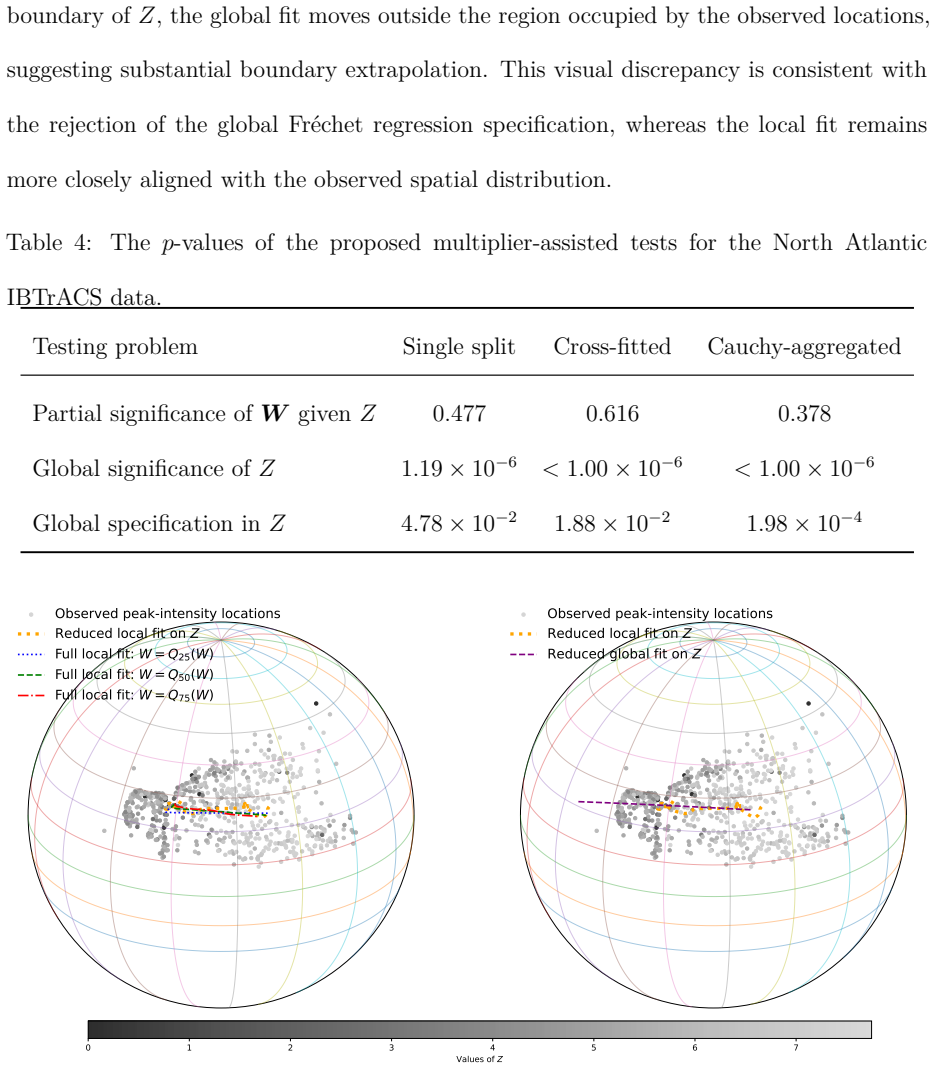
We propose a new procedure MATCH (Multiplier-Assisted Tests for Conditional Hypotheses) to test whether the non-Euclidean data match the target model, which is a general framework for significance and specification testing in Fr\'echet regression. MATCH covers global significance, partial significance, and the adequacy of global Fr\'echet regression, providing a unified way to compare unrestricted conditional Fr\'echet means with restricted alternatives. One of the key challenges is that the ordinary held-out loss difference is first-order degenerate under the null: the oracle losses coincide, and plug-in statistics is dominated by nuisance estimation error. MATCH uses sample splitting and independent random multipliers on held-out losses to create a nondegenerate Gaussian leading term without residuals or tangent-space coordinates. To improve data use and stability, we further develop cross-fitted tests and repeated cross-fitting with p-value merging. We establish asymptotic null validity, consistency under fixed alternatives, and local power guarantees. Simulations for distributional, symmetric positive-definite (SPD) matrix-valued, and spherical responses support the theoretical findings, and applications to county-level household income distributions and North Atlantic tropical-cyclone locations demonstrate the practical use of the proposed tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MATCH, a multiplier-assisted procedure for testing conditional hypotheses (global/partial significance and model adequacy) in Fréchet regression on general metric spaces. It uses sample splitting plus independent random multipliers on held-out losses to construct a nondegenerate Gaussian leading term that avoids residuals and tangent-space coordinates, and claims to establish asymptotic null validity, consistency under fixed alternatives, and local power guarantees, with supporting simulations for distributional, SPD-matrix, and spherical responses plus two real-data applications.
Significance. If the asymptotic results hold, the work supplies a unified, coordinate-free testing framework for non-Euclidean conditional means that directly addresses the first-order degeneracy of plug-in loss differences; this would be a useful methodological contribution for applications involving distributions, matrices, or directional data.
major comments (2)
- [Abstract] Abstract: the claim that independent random multipliers on split-sample held-out losses produce a nondegenerate leading term whose limiting distribution is free of nuisance estimation error is stated without an explicit expansion or influence-function representation of the Fréchet loss; in a general metric space the oracle loss difference is exactly zero under the null, so the argument that cross terms between the multiplier and the conditional Fréchet-mean estimator are o_p(1) uniformly must be supplied in detail.
- [Abstract] The construction must ensure that the conditional variance of the multiplier term remains positive and consistently estimable when the oracle loss difference vanishes; without this, the critical values derived from the Gaussian limit would not be valid. The manuscript needs to state the precise multiplier distribution and the minimal conditions on the metric and loss that guarantee non-degeneracy.
Simulated Author's Rebuttal
We thank the referee for the careful review and valuable suggestions on the abstract. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that independent random multipliers on split-sample held-out losses produce a nondegenerate leading term whose limiting distribution is free of nuisance estimation error is stated without an explicit expansion or influence-function representation of the Fréchet loss; in a general metric space the oracle loss difference is exactly zero under the null, so the argument that cross terms between the multiplier and the conditional Fréchet-mean estimator are o_p(1) uniformly must be supplied in detail.
Authors: The explicit expansion of the Fréchet loss difference, the influence-function representation, and the uniform o_p(1) argument for the cross terms are derived in detail in the proof of Theorem 3.1 (Section 3.2), using sample splitting and the properties of the Fréchet mean estimator in general metric spaces. We will revise the abstract to briefly reference this expansion and the resulting nondegenerate limit. revision: yes
-
Referee: [Abstract] The construction must ensure that the conditional variance of the multiplier term remains positive and consistently estimable when the oracle loss difference vanishes; without this, the critical values derived from the Gaussian limit would not be valid. The manuscript needs to state the precise multiplier distribution and the minimal conditions on the metric and loss that guarantee non-degeneracy.
Authors: The multipliers are i.i.d. standard normal (Section 2.2). The minimal conditions guaranteeing that the conditional variance remains positive and consistently estimable (complete separable metric space, Fréchet differentiability of the loss, and a nondegenerate variance operator) are stated in Assumptions 2.1--2.3 and 3.1. These ensure validity of the Gaussian critical values. We will revise the abstract to state the multiplier distribution and reference these conditions explicitly. revision: yes
Circularity Check
No circularity: direct construction via sample splitting and multipliers
full rationale
The paper introduces MATCH as an explicit statistical construction that applies sample splitting followed by independent random multipliers to held-out losses, thereby generating a nondegenerate Gaussian leading term. The provided abstract and description contain no equations, no fitted parameters renamed as predictions, and no load-bearing self-citations that reduce the validity claim to prior author work. The central argument rests on the algebraic effect of the multipliers and splitting, which is presented as a new device rather than derived from or equivalent to the target asymptotic statements. No self-definitional loops, ansatz smuggling, or uniqueness theorems imported from the same authors appear. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Responses are random elements in a metric space admitting unique Fréchet means and satisfying regularity conditions for asymptotic expansions
Reference graph
Works this paper leans on
-
[1]
and Patrangenaru, Vic , title =
Bhattacharya, Rabi N. and Patrangenaru, Vic , title =. The Annals of Statistics , year =
-
[2]
Journal of the American Statistical Association , year =
Cai, Leheng and Guo, Xu and Zhong, Wei , title =. Journal of the American Statistical Association , year =
-
[3]
Capitaine, Louis and Bigot, J. Fr. Journal of Machine Learning Research , year =
-
[4]
Uniform Convergence of Local Fr
Chen, Yaqing and M. Uniform Convergence of Local Fr. The Annals of Statistics , year =
-
[5]
and Gonz
Delgado, Miguel A. and Gonz. Significance Testing in Nonparametric Regression Based on the Bootstrap , journal =. 2001 , volume =
2001
-
[6]
and Mardia, Kanti V
Dryden, Ian L. and Mardia, Kanti V. , title =. 2016 , doi =
2016
-
[7]
Econometrica , year =
Fan, Yanqin and Li, Qi , title =. Econometrica , year =
-
[8]
Fr. Les. Annales de l'Institut Henri Poincar. 1948 , volume =
1948
-
[9]
Comparing Nonparametric Versus Parametric Regression Fits , journal =
H. Comparing Nonparametric Versus Parametric Regression Fits , journal =. 1993 , volume =
1993
-
[10]
Iao, Su I and Zhou, Yidong and M. Deep Fr. Journal of the American Statistical Association , year =
-
[11]
Journal of the American Statistical Association , year =
Liu, Yaowu and Xie, Jun , title =. Journal of the American Statistical Association , year =
-
[12]
Steve and Alonso, Andr
Marron, J. Steve and Alonso, Andr. Overview of Object Oriented Data Analysis , journal =. 2014 , volume =
2014
-
[13]
Marron, J. S. and Dryden, Ian L. , title =. 2021 , doi =
2021
-
[14]
and Zemel, Yoav , title =
Panaretos, Victor M. and Zemel, Yoav , title =. 2020 , doi =
2020
-
[15]
2015 , doi =
Patrangenaru, Victor and Ellingson, Leif , title =. 2015 , doi =
2015
-
[16]
, title =
Petersen, Alexander and Liu, Xi and Divani, Afshin A. , title =. The Annals of Statistics , year =
-
[17]
Petersen, Alexander and M. Fr. The Annals of Statistics , year =
-
[18]
Journal of Machine Learning Research , year =
Qiu, Rui and Yu, Zhou and Zhu, Ruoqing , title =. Journal of Machine Learning Research , year =
-
[19]
Nonparametric Regression in Nonstandard Spaces , journal =
Sch. Nonparametric Regression in Nonstandard Spaces , journal =. 2022 , volume =
2022
-
[20]
Inference for Fr
Song, Wookyeong and Dubey, Paromita and M. Inference for Fr. 2026 , journal =
2026
-
[21]
and Wu, Yichao and M
Tucker, Derek C. and Wu, Yichao and M. Variable Selection for Global Fr. Journal of the American Statistical Association , year =
-
[22]
2025 , journal =
Xu, Haoshu and Li, Hongzhe , title =. 2025 , journal =
2025
-
[23]
Journal of Machine Learning Research , year =
Xu, Haoshu and Li, Hongzhe , title =. Journal of Machine Learning Research , year =
-
[24]
Journal of the American Statistical Association , year =
Zhang, Qi and Xue, Lingzhou and Li, Bing , title =. Journal of the American Statistical Association , year =
-
[25]
Journal of Econometrics , year =
Zheng, John Xu , title =. Journal of Econometrics , year =
-
[26]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Significance tests of feature relevance for a black-box learner , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2024 , publisher=
2024
-
[27]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Assumption-lean inference for generalised linear model parameters , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2022 , publisher=
2022
-
[28]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
Variance estimation using refitted cross-validation in ultrahigh dimensional regression , author=. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=. 2012 , publisher=
2012
-
[29]
The Econometrics Journal , volume =
Chernozhukov, Victor and Chetverikov, Denis and Demirer, Mert and Duflo, Esther and Hansen, Christian and Newey, Whitney and Robins, James , title =. The Econometrics Journal , volume =. 2018 , month =. doi:10.1111/ectj.12097 , url =
-
[30]
The Annals of Statistics , volume=
Adaptive-to-model checking for regressions with diverging number of predictors , author=. The Annals of Statistics , volume=. 2019 , publisher=
2019
-
[31]
Biometrika , volume=
Integrated conditional moment test and beyond: when the number of covariates is divergent , author=. Biometrika , volume=. 2022 , publisher=
2022
-
[32]
The Annals of Statistics , volume=
The projected covariance measure for assumption-lean variable significance testing , author=. The Annals of Statistics , volume=. 2024 , publisher=
2024
-
[33]
arXiv preprint arXiv:2501.17345 , year=
Testing Conditional Mean Independence Using Generative Neural Networks , author=. arXiv preprint arXiv:2501.17345 , year=
-
[34]
Journal of the American Statistical Association , volume=
A general framework for inference on algorithm-agnostic variable importance , author=. Journal of the American Statistical Association , volume=. 2023 , publisher=
2023
-
[35]
Biometrika , year =
Vovk, Vladimir and Wang, Ruodu , title =. Biometrika , year =
-
[36]
The Annals of Statistics , year =
Vovk, Vladimir and Wang, Ruodu , title =. The Annals of Statistics , year =
-
[37]
The Annals of Statistics , year =
Vovk, Vladimir and Wang, Bin and Wang, Ruodu , title =. The Annals of Statistics , year =
-
[38]
, title =
Wilson, Daniel J. , title =. Proceedings of the National Academy of Sciences of the United States of America , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.