Epic-Organized vs. Requirement-Aligned Gherkin: An Empirical Evaluation of LLM-Based Acceptance Criteria Generation
Pith reviewed 2026-07-03 08:56 UTC · model grok-4.3
The pith
Epic-organized LLM generation of Gherkin produces higher expert-rated quality than requirement-aligned generation while preserving semantic coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
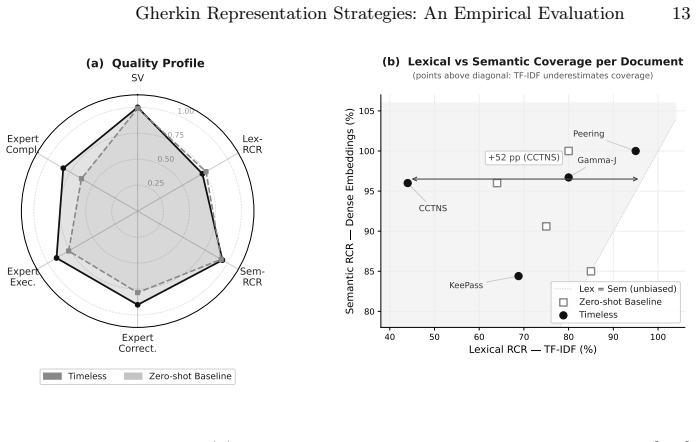
The epic-organized approach, implemented as the Timeless pipeline, produced Gherkin scenarios that experts rated higher on correctness (4.61 vs 4.14), executability (4.61 vs 4.07), and completeness (4.31 vs 3.50) compared to a requirement-aligned zero-shot baseline, while achieving comparable semantic requirement coverage (94.3% vs 92.9%).
What carries the argument
The Timeless epic-organized LLM pipeline, which structures generation around epics rather than individual requirements, evaluated through structural validity checks, TF-IDF and embedding-based semantic coverage, and blind expert assessment.
If this is right
- JSON-constrained LLM pipelines can achieve full structural validity in generated Gherkin scenarios.
- TF-IDF lexical metrics may underestimate coverage when scenarios paraphrase requirements at a higher level of abstraction.
- Epic-organized generation can improve perceived quality metrics without loss of semantic requirement coverage.
- The comparison is limited to four documents and requires broader replication before generalization.
Where Pith is reading between the lines
- Teams using BDD could reduce manual Gherkin authoring effort by adopting epic-organized LLM pipelines in their requirements tools.
- Applying the approach to industry requirements outside the PURE dataset would test whether quality gains hold in practice.
- Combining epic organization with additional prompting methods might produce further gains in the rated quality dimensions.
Load-bearing premise
The four requirements documents from the PURE dataset and assessments by four expert raters provide a sufficient and representative basis for generalizing that epic-organized generation improves perceived Gherkin quality.
What would settle it
A replication using ten or more independent expert raters across additional requirements documents that finds no significant preference for the epic-organized outputs on correctness, executability, or completeness.
Figures


read the original abstract
Automated authoring of Gherkin Behavior-Driven Development (BDD) acceptance criteria remains a manual bottleneck in requirements engineering. This study investigates whether epic-organized LLM-generated Gherkin produces higher quality and coverage than requirement-aligned generation. We compare our Timeless (an epic-organized LLM pipeline) approach against a naive large language model (LLM) baseline on four requirements documents (107 requirements) from the PURE dataset. Evaluation covers structural metrics, automated requirement coverage via TF-IDF and dense embeddings, and blind expert assessment by four researchers. In our evaluation, the JSON-constrained pipeline produced structurally valid scenarios across all generated outputs, while the zero-shot baseline achieved 99% structural validity. Semantic coverage was comparable to the baseline, with Timeless achieving 94.3% semantic Requirement Coverage Rate compared with 92.9% for the baseline. TF-IDF produced lower coverage scores for the epic-organized output, suggesting that lexical metrics may miss coverage when scenarios paraphrase requirements at a higher level of abstraction. Expert raters prefer the epic-organized strategy on Correctness (4.61 vs 4.14), Executability (4.61 vs 4.07), and Completeness (4.31 vs 3.50). Overall, the results suggest that epic-organized generation can improve perceived Gherkin quality while maintaining comparable semantic coverage, although broader replication is needed before generalizing this finding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an epic-organized LLM pipeline (Timeless) for generating Gherkin BDD acceptance criteria yields higher perceived quality than a requirement-aligned zero-shot baseline, as measured by expert ratings on Correctness (4.61 vs 4.14), Executability (4.61 vs 4.07), and Completeness (4.31 vs 3.50), while achieving comparable semantic coverage (94.3% vs 92.9% via embeddings) on four PURE dataset documents containing 107 requirements. Structural validity is near-perfect for both approaches, and the authors conclude that epic organization can improve quality with a call for broader replication.
Significance. If the central claim holds after addressing evaluation limitations, the work offers a practical contribution to automated requirements engineering by showing that organizing LLM generation around epics rather than individual requirements can enhance perceived Gherkin attributes without sacrificing coverage. The combination of structural metrics, dual semantic coverage methods (TF-IDF and embeddings), and blind expert assessment is a methodological strength, as is the explicit acknowledgment that replication is needed.
major comments (2)
- [Expert Assessment / Results] Expert Assessment (results section): The mean expert preference scores are reported from only four raters on four documents with no inter-rater agreement statistic (e.g., Fleiss' kappa or ICC), no per-rater or per-document score distributions, no standard deviations or confidence intervals, and no hypothesis tests. This directly undermines the load-bearing claim that epic-organized generation improves perceived quality, as the differences could reflect sampling variability or rater-specific biases rather than a general effect.
- [Evaluation Setup] Evaluation Setup (experimental design): The study relies on only four requirements documents (107 requirements total) from a single source (PURE dataset). While the paper correctly flags the need for replication, the absence of any power analysis, diversity justification, or sensitivity checks means the observed quality differences cannot yet support the generalization that epic-organized generation improves Gherkin quality.
minor comments (2)
- [Methods] The abstract states the JSON-constrained pipeline achieved 100% structural validity while the baseline reached 99%; the precise definition and automated checks used to determine 'structural validity' of Gherkin scenarios should be detailed in the methods.
- [Semantic Coverage Analysis] The discrepancy between TF-IDF coverage (lower for Timeless) and embedding-based coverage (comparable) is noted as evidence that lexical metrics miss higher-abstraction paraphrasing, but no quantitative comparison of the two coverage methods or example scenarios illustrating the difference is provided.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript to improve statistical reporting and limitation discussions while preserving the original empirical observations.
read point-by-point responses
-
Referee: [Expert Assessment / Results] Expert Assessment (results section): The mean expert preference scores are reported from only four raters on four documents with no inter-rater agreement statistic (e.g., Fleiss' kappa or ICC), no per-rater or per-document score distributions, no standard deviations or confidence intervals, and no hypothesis tests. This directly undermines the load-bearing claim that epic-organized generation improves perceived quality, as the differences could reflect sampling variability or rater-specific biases rather than a general effect.
Authors: We agree that the small rater and document counts warrant more transparent reporting. In revision we will add standard deviations and 95% confidence intervals to the mean scores, include per-document score tables, and compute/report Fleiss' kappa from the existing ratings. We will also explicitly note the absence of hypothesis tests and the risk of rater bias. The consistent directional preference across metrics still supports the observed pattern, but we accept that stronger statistical framing is needed and will adjust the results and discussion sections accordingly. revision: partial
-
Referee: [Evaluation Setup] Evaluation Setup (experimental design): The study relies on only four requirements documents (107 requirements total) from a single source (PURE dataset). While the paper correctly flags the need for replication, the absence of any power analysis, diversity justification, or sensitivity checks means the observed quality differences cannot yet support the generalization that epic-organized generation improves Gherkin quality.
Authors: We concur that the single-source sample of four documents limits generalizability, which is why the manuscript already calls for replication. We will add a post-hoc power note, a short justification for PURE document selection (public availability and domain variety), and a sensitivity discussion (e.g., noting that leave-one-document-out patterns remain directionally consistent). No new data collection is proposed; the revision will strengthen the limitations paragraph without altering the core claim for the studied cases. revision: yes
Circularity Check
No circularity: empirical evaluation with direct measurements
full rationale
This is a purely empirical comparison paper. It generates Gherkin scenarios via two LLM pipelines (Timeless epic-organized vs. zero-shot baseline), then measures structural validity, TF-IDF/dense-embedding coverage, and blind expert ratings on four PURE documents. No equations, fitted parameters, predictions derived from inputs, or self-citations are used to support the central claims. All reported differences (e.g., expert means 4.61 vs 4.14) are direct observations from the evaluation protocol. The paper itself notes the need for replication, confirming the results are not presented as self-contained derivations. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert assessments by four researchers provide a valid measure of Gherkin scenario quality
- domain assumption The subset of four requirements documents from the PURE dataset is sufficient to draw conclusions about the two generation strategies
Reference graph
Works this paper leans on
-
[1]
In: Generative AI for Effective Software Development, pp
Arora, C., Grundy, J., Abdelrazek, M.: Advancing requirements engineering through generative ai: Assessing the role of llms. In: Generative AI for Effective Software Development, pp. 129–148. Springer (2024)
2024
-
[2]
In: 2018 IEEE 25th Inter- national Conference on Software Analysis, Evolution and Reengineering (SANER)
Binamungu, L.P., Embury, S.M., Konstantinou, N.: Maintaining behaviour driven development specifications: Challenges and opportunities. In: 2018 IEEE 25th Inter- national Conference on Software Analysis, Evolution and Reengineering (SANER). pp. 175–184. IEEE (2018)
2018
-
[3]
Journal of Systems and Software203, 111749 (2023) 16 S
Binamungu, L.P., Maro, S.: Behaviour driven development: A systematic mapping study. Journal of Systems and Software203, 111749 (2023) 16 S. Siddeeq et al
2023
-
[4]
Cucumber Open Source Project: Cucumber – bdd testing and automation.https: //cucumber.io(2023)
2023
-
[5]
In: Proceedings of the 25th International Requirements Engineering Conference (RE)
Ferrari, A., Spagnolo, G.O., Gnesi, S.: PURE: A dataset of public requirements documents. In: Proceedings of the 25th International Requirements Engineering Conference (RE). pp. 502–503. IEEE (2017).https://doi.org/10.1109/RE.2017. 29, dataset available at:https://zenodo.org/record/1414117
-
[6]
In: 2025 IEEE/ACM International Conference on Automation of Software Test (AST)
Ferreira, M., Viegas, L., Faria, J.P., Lima, B.: Acceptance test generation with large language models: An industrial case study. In: 2025 IEEE/ACM International Conference on Automation of Software Test (AST). pp. 1–11. IEEE (2025)
2025
-
[7]
Information and Software Technology p
Hassani, S., Sabetzadeh, M., Amyot, D.: From law to gherkin: A human-centred quasi-experiment on the quality of llm-generated behavioural specifications from food-safety regulations. Information and Software Technology p. 108122 (2026)
2026
-
[8]
Requirements Engineering3(2), 84–90 (1998)
Kamsties, E., Hörmann, K., Schlich, M.: Requirements engineering in small and medium enterprises: State-of-the-practice, problems, solutions, and technology transfer. Requirements Engineering3(2), 84–90 (1998)
1998
-
[9]
IEEE Access (2024)
Karpurapu, S., Myneni, S., Nettur, U., Gajja, L.S., Burke, D., Stiehm, T., Payne, J.: Comprehensive evaluation and insights into the use of large language models in the automation of behavior-driven development acceptance test formulation. IEEE Access (2024)
2024
-
[10]
Requirements engineering 21(3), 383–403 (2016)
Lucassen, G., Dalpiaz, F., van der Werf, J.M.E., Brinkkemper, S.: Improving agile requirements: the quality user story framework and tool. Requirements engineering 21(3), 383–403 (2016)
2016
-
[11]
Better Software Magazine.[Online]
North, D.: Introducing bdd. Better Software Magazine.[Online]. (2006), available at:https://dannorth.net/blog/introducing-bdd
2006
-
[12]
In: Proceed- ings of the Conference on the Future of Software Engineering (ICSE 2000)
Nuseibeh, B., Easterbrook, S.: Requirements engineering: A roadmap. In: Proceed- ings of the Conference on the Future of Software Engineering (ICSE 2000). pp. 35–46. ACM (2000)
2000
-
[13]
OpenAI: Gpt-4 technical report. Tech. rep., OpenAI (2023), arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Robust Speech Recognition via Large-Scale Weak Supervision
Radford, A., Kim, J.W., Xu, T., Brockman, G., McLeavey, C., Sutskever, I.: Robust speech recognition via large-scale weak supervision. arXiv preprint arXiv:2212.04356 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
arXiv preprint arXiv:2411.08507 (2024)
Rasheed, Z., Sami, M.A., Rasku, J., Kemell, K.K., Zhang, Z., Harjamaki, J., Siddeeq, S., Lahti, S., Herda, T., Nurminen, M., et al.: Timeless: A vision for the next generation of software development. arXiv preprint arXiv:2411.08507 (2024)
-
[16]
arXiv preprint arXiv:2603.04729 (2026)
Rathnayake, A., Shahin, M., Abaei, G.: Behaviour driven development scenario generation with large language models. arXiv preprint arXiv:2603.04729 (2026). https://doi.org/10.48550/arXiv.2603.04729
-
[17]
In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Reimers, N., Gurevych, I.: Sentence-BERT: Sentence embeddings using siamese BERT-networks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 3982–3992. Association for Computa- tional Linguistics (2019)
2019
-
[18]
Lecture Notes in Business Information Processing, vol
Ronanki, K., Cabrero-Daniel, B., Berger, C.: ChatGPT as a tool for user story quality evaluation: Trustworthy out of the box? In: Agile Processes in Software Engineering and Extreme Programming – Workshops (XP 2022 Workshops). Lecture Notes in Business Information Processing, vol. 489, pp. 173–181. Springer (2024). https://doi.org/10.1007/978-3-031-48550-...
-
[19]
Simon and Schuster (2023)
Smart, J.F., Molak, J.: BDD in Action: Behavior-Driven Development for the Whole Software Lifecycle. Simon and Schuster (2023)
2023
-
[20]
In: Proceedings of the 37th EUROMICRO Conference on Software Engineering and Advanced Applications (SEAA)
Solís, C., Wang, X.: A study of the characteristics of behaviour driven development. In: Proceedings of the 37th EUROMICRO Conference on Software Engineering and Advanced Applications (SEAA). pp. 383–387. IEEE (2011)
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.