Rise From The Ashes: LLM-based Static Analysis for Deep Learning Framework Bugs
Pith reviewed 2026-07-02 08:58 UTC · model grok-4.3
The pith
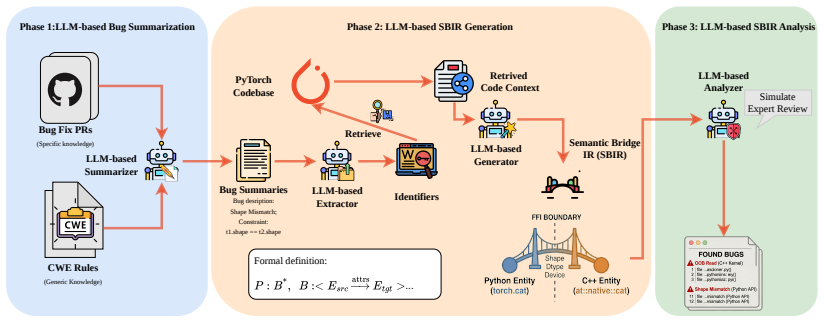
Phoenix uses multi-agent LLMs to build SBIRs that model tensor flows and detect bugs in deep learning frameworks without execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Phoenix shows that a multi-agent LLM workflow can distill bug patterns from patches, retrieve relevant symbols, synthesize SBIRs that capture tensor semantics with surrounding code, and then flag real bugs in semantic propagation across the multilingual architecture of DL frameworks.
What carries the argument
The structured semantic bridge intermediate representation (SBIR) that encodes cross-language tensor flows together with concrete code context so LLMs can check for propagation bugs.
If this is right
- Static analysis becomes feasible for DL frameworks that mix languages and maintain complex tensor state.
- Tensor bugs can be located without incurring the runtime cost of dynamic test execution.
- The technique applies across heterogeneous hardware backends such as Intel CPU, NVIDIA CUDA, and Apple MPS.
- Bugs found this way can lead to accepted upstream patches in projects like PyTorch.
Where Pith is reading between the lines
- If SBIR construction remains reliable, the same agent pattern could extend to other large multilingual codebases that move data objects across modules.
- Continuous integration pipelines for AI frameworks could incorporate this static pass to catch propagation issues earlier than fuzzing alone.
- Pairing the method with existing dynamic tools might yield higher overall bug coverage at lower total compute cost.
Load-bearing premise
The multi-agent workflow produces SBIRs that correctly capture tensor semantics and the analysis agent identifies actual bugs instead of false positives.
What would settle it
Apply Phoenix to a PyTorch version containing known injected tensor propagation errors and check whether it reports most of them or instead generates a high rate of incorrect warnings.
Figures






read the original abstract
Deep learning (DL) frameworks are critical AI infrastructures that often hide bugs with serious security implications. While dynamic approaches such as fuzzing are effective in uncovering these bugs, they require real test execution and incur high computational costs. Static analysis is a natural complement because it can detect bugs without runtime execution, offering fast and scalable testing. Unfortunately, there is still limited work targeting static analysis for DL frameworks due to their multilingual architectures and tensor-related program state. We present Phoenix, the first LLM-based static analysis technique for DL frameworks. Our key insight is that cross-language tensor flows in DL frameworks can be modeled, together with concrete code context, as a structured semantic bridge intermediate representation (SBIR) that LLMs can analyze for potential bugs in tensor semantic propagation. We implement this insight through a multi-agent workflow. A summarization agent first distills bug summaries from historical bug-fix patches and CWE rules. Guided by each summary, an extraction agent identifies bug-relevant repository symbols for code retrieval, and a generation agent synthesizes grounded SBIRs from the retrieved context. Finally, an analysis agent is leveraged to check SBIRs and report potential bugs. Our evaluation shows that Phoenix is a practical complement to dynamic DL framework testing for bug finding. To date, Phoenix has found 31 real new bugs in PyTorch for different heterogeneous hardware backends (Intel CPU, NVIDIA CUDA, and Apple MPS). Among them, 20 submitted bug-fixing patches have been merged into upstream.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Phoenix, the first LLM-based static analysis technique for deep learning frameworks. It models cross-language tensor flows and code context as a structured semantic bridge intermediate representation (SBIR) via a four-agent workflow (summarization from patches/CWE, extraction of symbols, SBIR generation, and analysis). On PyTorch, Phoenix reports discovering 31 previously unknown bugs across Intel CPU, NVIDIA CUDA, and Apple MPS backends, with 20 submitted patches merged upstream.
Significance. If the results hold, the work is significant for demonstrating a scalable static complement to dynamic fuzzing in critical DL infrastructure. The external validation via 20 merged upstream patches provides concrete, falsifiable evidence that the multi-agent SBIR workflow can surface actionable bugs rather than hallucinations. This is a strength for reproducibility and impact in software engineering for AI systems.
major comments (2)
- [§4 (Evaluation)] §4 (Evaluation): The central claim of 31 real bugs rests on the analysis agent's output, yet the manuscript provides no breakdown of how many candidate SBIRs were generated versus how many were triaged as bugs, nor any reported false-positive rate or manual confirmation protocol beyond the merged patches. This makes it difficult to assess whether the workflow reliably identifies tensor semantic propagation errors.
- [§3.3 (Analysis agent)] §3.3 (Analysis agent): The description of how the analysis agent checks SBIRs for bugs lacks concrete criteria or examples of the prompts/templates used to distinguish real tensor-flow mismatches from benign patterns; without this, the claim that SBIRs 'accurately model tensor semantic propagation' remains under-specified for replication.
minor comments (3)
- [§3] The SBIR definition and its construction steps would benefit from a single running example (e.g., a small tensor operation across C++/CUDA) to illustrate the summarization-to-analysis pipeline.
- [§2] Related-work section should explicitly compare against prior LLM-based static analysis efforts (e.g., those using LLMs for vulnerability detection) to clarify the novelty of the SBIR modeling choice.
- [§4] Table or figure reporting the 31 bugs should include columns for backend, bug type (e.g., CWE), and patch status to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, the recognition of the work's significance, and the recommendation for minor revision. The comments highlight opportunities to improve transparency in the evaluation and replicability of the analysis agent, which we address below.
read point-by-point responses
-
Referee: [§4 (Evaluation)] §4 (Evaluation): The central claim of 31 real bugs rests on the analysis agent's output, yet the manuscript provides no breakdown of how many candidate SBIRs were generated versus how many were triaged as bugs, nor any reported false-positive rate or manual confirmation protocol beyond the merged patches. This makes it difficult to assess whether the workflow reliably identifies tensor semantic propagation errors.
Authors: We agree that a more detailed breakdown would strengthen the presentation. The primary evidence for the 31 bugs is the external validation via 20 merged upstream patches, which provides concrete confirmation beyond internal triage. In the revised manuscript, we will add to §4 a description of the triage process, the number of SBIRs generated and analyzed where tracked, and the manual confirmation steps performed before patch submission. We will also note any observed false positives during development. This addresses the request for additional protocol details without altering the core results. revision: yes
-
Referee: [§3.3 (Analysis agent)] §3.3 (Analysis agent): The description of how the analysis agent checks SBIRs for bugs lacks concrete criteria or examples of the prompts/templates used to distinguish real tensor-flow mismatches from benign patterns; without this, the claim that SBIRs 'accurately model tensor semantic propagation' remains under-specified for replication.
Authors: We acknowledge that §3.3 currently provides a high-level overview of the analysis agent's role. To improve replicability, we will revise this section to include the concrete decision criteria used to identify tensor semantic propagation errors (e.g., mismatches in shape, dtype, or device propagation across backends) and add example prompts/templates as an appendix. This will make explicit how the agent differentiates actionable bugs from benign patterns while preserving the multi-agent workflow description. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical tool (Phoenix) for static bug detection in DL frameworks via a multi-agent LLM workflow that constructs SBIRs from code context and historical patches. Its central claim is the discovery of 31 previously unknown bugs with 20 upstream-merged patches serving as external validation. No equations, derivations, fitted parameters, or self-referential predictions appear in the manuscript. The workflow is described as a practical engineering pipeline rather than a mathematical derivation, and the results are anchored by independent confirmation (merged patches) rather than internal consistency alone. No load-bearing self-citations, ansatzes, or renamings reduce the reported findings to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cam- bridge University Press, 2017
Paul Ammann and Jeff Offutt.Introduction to software testing. Cam- bridge University Press, 2017
2017
-
[2]
The oracle problem in software testing: A survey.IEEE transactions on software engineering, 41(5):507–525, 2014
Earl T Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo. The oracle problem in software testing: A survey.IEEE transactions on software engineering, 41(5):507–525, 2014
2014
-
[3]
Juliet 1
Tim Boland and Paul E Black. Juliet 1. 1 c/c++ and java test suite. Computer, 45(10):88–90, 2012
2012
-
[4]
JAX: Composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, and Skye Wanderman-Milne. JAX: Composable transformations of Python+NumPy programs, 2018. https: //github.com/jax-ml/jax
2018
-
[5]
Simin Chen, Jinjun Peng, Yixin He, Junfeng Yang, and Baishakhi Ray. Your compiler is backdooring your model: Understanding and exploiting compilation inconsistency vulnerabilities in deep learning compilers. arXiv preprint arXiv:2509.11173, 2025
-
[6]
Tvm: An automated end-to-end optimizing compiler for deep learning
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. Tvm: An automated end-to-end optimizing compiler for deep learning. In13th USENIX symposium on operating systems design and implementation (OSDI 18), pages 578–594, 2018
2018
-
[7]
Metamorphic testing: A review of challenges and opportunities.ACM Computing Surveys (CSUR), 51(1):1–27, 2018
Tsong Yueh Chen, Fei-Ching Kuo, Huai Liu, Pak-Lok Poon, Dave Towey, TH Tse, and Zhi Quan Zhou. Metamorphic testing: A review of challenges and opportunities.ACM Computing Surveys (CSUR), 51(1):1–27, 2018
2018
-
[8]
Keras, 2015
Franc ¸ois Chollet et al. Keras, 2015. https://keras.io
2015
-
[9]
Abstract interpretation: a unified lattice model for static analysis of programs by construction or approx- imation of fixpoints
Patrick Cousot and Radhia Cousot. Abstract interpretation: a unified lattice model for static analysis of programs by construction or approx- imation of fixpoints. InProceedings of the 4th ACM SIGACT-SIGPLAN symposium on Principles of programming languages, pages 238–252, 1977
1977
-
[10]
Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models
Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang. Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. InProceedings of the 32nd ACM SIGSOFT international symposium on software testing and analysis, pages 423–435, 2023
2023
-
[11]
Large language models are edge-case generators: Crafting unusual programs for fuzzing deep learning libraries
Yinlin Deng, Chunqiu Steven Xia, Chenyuan Yang, Shizhuo Dylan Zhang, Shujing Yang, and Lingming Zhang. Large language models are edge-case generators: Crafting unusual programs for fuzzing deep learning libraries. InProceedings of the 46th IEEE/ACM international conference on software engineering, pages 1–13, 2024
2024
-
[12]
An empirical study of fault triggers in deep learning frameworks.IEEE Transactions on Dependable and Secure Computing, 20(4):2696–2712, 2022
Xiaoting Du, Yulei Sui, Zhihao Liu, and Jun Ai. An empirical study of fault triggers in deep learning frameworks.IEEE Transactions on Dependable and Secure Computing, 20(4):2696–2712, 2022
2022
-
[13]
Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag
Xueying Du, Geng Zheng, Kaixin Wang, Yi Zou, Yujia Wang, Wentai Deng, Jiayi Feng, Mingwei Liu, Bihuan Chen, Xin Peng, et al. Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag. ACM Transactions on Software Engineering and Methodology, 2024
2024
-
[14]
Ac/c++ code vulnerability dataset with code changes and cve summaries
Jiahao Fan, Yi Li, Shaohua Wang, and Tien N Nguyen. Ac/c++ code vulnerability dataset with code changes and cve summaries. In Proceedings of the 17th international conference on mining software repositories, pages 508–512, 2020
2020
-
[15]
Audee: Automated testing for deep learning frameworks
Qianyu Guo, Xiaofei Xie, Yi Li, Xiaoyu Zhang, Yang Liu, Xiaohong Li, and Chao Shen. Audee: Automated testing for deep learning frameworks. InProceedings of the 35th IEEE/ACM international conference on automated software engineering, pages 486–498, 2020
2020
-
[16]
Yuchen Ji, Ting Dai, Zhichao Zhou, Yutian Tang, and Jingzhu He. Artemis: Toward accurate detection of server-side request forgeries through llm-assisted inter-procedural path-sensitive taint analysis.Pro- ceedings of the ACM on Programming Languages, 9(OOPSLA1):1349– 1377, 2025
2025
-
[17]
Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157, 2024
2024
-
[18]
Auerbach Publications, 2013
Paul C Jorgensen.Software testing: a craftsman’s approach. Auerbach Publications, 2013
2013
-
[19]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[20]
Enhancing static analysis for practical bug detection: An llm-integrated approach.Pro- ceedings of the ACM on Programming Languages, 8(OOPSLA1):474– 499, 2024
Haonan Li, Yu Hao, Yizhuo Zhai, and Zhiyun Qian. Enhancing static analysis for practical bug detection: An llm-integrated approach.Pro- ceedings of the ACM on Programming Languages, 8(OOPSLA1):474– 499, 2024
2024
-
[21]
Towards more accurate static analysis for taint-style bug detection in linux kernel
Haonan Li, Hang Zhang, Kexin Pei, and Zhiyun Qian. Towards more accurate static analysis for taint-style bug detection in linux kernel. In 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 380–392. IEEE, 2025
2025
-
[22]
The seeds of the future sprout from history: Fuzzing for unveiling vulnerabilities in prospective deep-learning libraries
Zhiyuan Li, Jingzheng Wu, Xiang Ling, Tianyue Luo, Zhiqing Rui, and Yanjun Wu. The seeds of the future sprout from history: Fuzzing for unveiling vulnerabilities in prospective deep-learning libraries. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), pages 1616–1627. IEEE, 2025
2025
-
[23]
Iris: Llm-assisted static anal- ysis for detecting security vulnerabilities
Ziyang Li, Saikat Dutta, and Mayur Naik. Iris: Llm-assisted static anal- ysis for detecting security vulnerabilities. InInternational Conference on Learning Representations, volume 2025, pages 35735–35758, 2025
2025
-
[24]
Nnsmith: Generating diverse and valid test cases for deep learning compilers
Jiawei Liu, Jinkun Lin, Fabian Ruffy, Cheng Tan, Jinyang Li, Aurojit Panda, and Lingming Zhang. Nnsmith: Generating diverse and valid test cases for deep learning compilers. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 2, pages 530–543, 2023
2023
-
[25]
Neuri: Diversifying dnn generation via inductive rule inference
Jiawei Liu, Jinjun Peng, Yuyao Wang, and Lingming Zhang. Neuri: Diversifying dnn generation via inductive rule inference. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the F oundations of Software Engineering, pages 657–669, 2023
2023
-
[26]
Llm- powered static binary taint analysis.ACM Transactions on Software Engineering and Methodology, 34(3):1–36, 2025
Puzhuo Liu, Chengnian Sun, Yaowen Zheng, Xuan Feng, Chuan Qin, Yuncheng Wang, Zhenyang Xu, Zhi Li, Peng Di, Yu Jiang, et al. Llm- powered static binary taint analysis.ACM Transactions on Software Engineering and Methodology, 34(3):1–36, 2025
2025
-
[27]
Graph-based fuzz testing for deep learning inference engines
Weisi Luo, Dong Chai, Xiaoyue Ruan, Jiang Wang, Chunrong Fang, and Zhenyu Chen. Graph-based fuzz testing for deep learning inference engines. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), pages 288–299. IEEE, 2021
2021
-
[28]
2025 CWE Top 25 Most Dangerous Software Weaknesses,
MITRE. 2025 CWE Top 25 Most Dangerous Software Weaknesses,
2025
-
[29]
https://cwe.mitre.org/top25/archive/2025/2025 cwe top25.html
2025
-
[30]
Deep learning for financial applications: A survey.Applied soft computing, 93:106384, 2020
Ahmet Murat Ozbayoglu, Mehmet Ugur Gudelek, and Omer Berat Sezer. Deep learning for financial applications: A survey.Applied soft computing, 93:106384, 2020
2020
-
[31]
Pytorch: An imperative style, high-performance deep learning library.Advances in Neural Information Processing Systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Brad- bury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[32]
Cradle: cross-backend validation to detect and localize bugs in deep learning 11 libraries
Hung Viet Pham, Thibaud Lutellier, Weizhen Qi, and Lin Tan. Cradle: cross-backend validation to detect and localize bugs in deep learning 11 libraries. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), pages 1027–1038. IEEE, 2019
2019
-
[33]
Bandit: Security linter for python source code, 2026
Python Code Quality Authority. Bandit: Security linter for python source code, 2026. https://bandit.readthedocs.io/
2026
-
[34]
http://pytorch.org
Pytorch, 2018. http://pytorch.org
2018
-
[35]
PyTorch documentation: torch.nn.functional.embedding bag,
PyTorch. PyTorch documentation: torch.nn.functional.embedding bag,
-
[36]
https://pytorch.org/docs/stable/generated/torch.nn.functional.em bedding bag.html
-
[37]
PyTorch issue #106362: Calling ops.aten.embedding bag() function got silent crash, 2023
PyTorch Contributors. PyTorch issue #106362: Calling ops.aten.embedding bag() function got silent crash, 2023. https://github.com/pytorch/pytorch/issues/106362
2023
-
[38]
PyTorch pull requests matching tensor, 2026
PyTorch Contributors. PyTorch pull requests matching tensor, 2026. https://github.com/pytorch/pytorch/pulls?q=is:pr+tensor
2026
-
[39]
Tricorder: Building a program analysis ecosystem
Caitlin Sadowski, Jeffrey Van Gogh, Ciera Jaspan, Emma Soderberg, and Collin Winter. Tricorder: Building a program analysis ecosystem. In2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, volume 1, pages 598–608. IEEE, 2015
2015
-
[40]
Deepface: Closing the gap to human-level performance in face veri- fication
Yaniv Taigman, Ming Yang, Marc’Aurelio Ranzato, and Lior Wolf. Deepface: Closing the gap to human-level performance in face veri- fication. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1701–1708, 2014
2014
-
[41]
Clang static analyzer, 2026
The Clang Team. Clang static analyzer, 2026. https://clang-analyzer.ll vm.org/
2026
-
[42]
Deeptest: Automated testing of deep-neural-network-driven autonomous cars
Yuchi Tian, Kexin Pei, Suman Jana, and Baishakhi Ray. Deeptest: Automated testing of deep-neural-network-driven autonomous cars. In Proceedings of the 40th international conference on software engineer- ing, pages 303–314, 2018
2018
-
[43]
An empirical investigation into learning bug-fixing patches in the wild via neural machine translation
Michele Tufano, Cody Watson, Gabriele Bavota, Massimiliano Di Penta, Martin White, and Denys Poshyvanyk. An empirical investigation into learning bug-fixing patches in the wild via neural machine translation. InProceedings of the 33rd ACM/IEEE international conference on automated software engineering, pages 832–837, 2018
2018
-
[44]
Llmdfa: analyzing dataflow in code with large language models.Advances in Neural Information Processing Systems, 37:131545–131574, 2024
Chengpeng Wang, Wuqi Zhang, Zian Su, Xiangzhe Xu, Xiaoheng Xie, and Xiangyu Zhang. Llmdfa: analyzing dataflow in code with large language models.Advances in Neural Information Processing Systems, 37:131545–131574, 2024
2024
-
[45]
Boosting static resource leak detection via llm-based resource-oriented intention inference
Chong Wang, Jianan Liu, Xin Peng, Yang Liu, and Yiling Lou. Boosting static resource leak detection via llm-based resource-oriented intention inference. In2025 IEEE/ACM 47th International Conference on Soft- ware Engineering (ICSE), pages 2905–2917. IEEE, 2025
2025
-
[46]
Qlcoder: A query synthesizer for static analysis of security vulnerabilities, 2025
Claire Wang, Ziyang Li, Saikat Dutta, and Mayur Naik. Qlcoder: A query synthesizer for static analysis of security vulnerabilities, 2025
2025
-
[47]
Deep learning library testing via effective model generation
Zan Wang, Ming Yan, Junjie Chen, Shuang Liu, and Dongdi Zhang. Deep learning library testing via effective model generation. InProceed- ings of the 28th ACM joint meeting on european software engineering conference and symposium on the foundations of software engineering, pages 788–799, 2020
2020
-
[48]
Codescope: An execution-based multilingual multitask multidimensional benchmark for evaluating llms on code understanding and generation
Weixiang Yan, Haitian Liu, Yunkun Wang, Yunzhe Li, Qian Chen, Wen Wang, Tingyu Lin, Weishan Zhao, Li Zhu, Hari Sundaram, et al. Codescope: An execution-based multilingual multitask multidimensional benchmark for evaluating llms on code understanding and generation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (...
2024
-
[49]
Whitefox: White-box compiler fuzzing empowered by large language models.Proceedings of the ACM on Programming Languages, 8(OOPSLA2):709–735, 2024
Chenyuan Yang, Yinlin Deng, Runyu Lu, Jiayi Yao, Jiawei Liu, Rey- haneh Jabbarvand, and Lingming Zhang. Whitefox: White-box compiler fuzzing empowered by large language models.Proceedings of the ACM on Programming Languages, 8(OOPSLA2):709–735, 2024
2024
-
[50]
Knighter: Transforming static analysis with llm-synthesized checkers
Chenyuan Yang, Zijie Zhao, Zichen Xie, Haoyu Li, and Lingming Zhang. Knighter: Transforming static analysis with llm-synthesized checkers. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, pages 655–669, 2025
2025
-
[51]
Shaoyu Yang, Chunrong Fang, Haifeng Lin, Xiang Chen, Jia Liu, and Zhenyu Chen. May the feedback be with you! unlocking the power of feedback-driven deep learning framework fuzzing via llms.arXiv preprint arXiv:2506.17642, 2025
-
[52]
Siren’s song in the ai ocean: A survey on hallucination in large language models
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. Siren’s song in the ai ocean: A survey on hallucination in large language models. Computational Linguistics, 51(4):1373–1418, 2025
2025
-
[53]
Sglang: Efficient execution of structured language model programs.Advances in Neural Information Processing Systems, 37:62557–62583, 2024
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in Neural Information Processing Systems, 37:62557–62583, 2024
2024
-
[54]
Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks.Advances in Neural Information Processing Systems, 32, 2019
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks.Advances in Neural Information Processing Systems, 32, 2019. 12
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.